













 Подружка
Подружка Бизнес-аналитика,Маркетинг,Общие вопросы парсинга
Парсинг цен конкурентов: полное руководство по обходу блокировок и защит

Авг
Введение: почему мониторинг цен — необходимость, а защита — не преграда
Представьте, что вы пытаетесь собрать данные о ценах конкурентов, но постоянно натыкаетесь на ошибки, блокировки и бесконечные CAPTCHA. Сайты ваших соперников по рынку становятся все умнее, используя сложные и дорогостоящие системы защиты, которые превращают простой, казалось бы, сбор данных в настоящую головную боль.1 Это создает иллюзию непреодолимого барьера, заставляя многих предпринимателей и маркетологов опускать руки, теряя ценную информацию для принятия стратегических решений.

Но что, если мы скажем вам, что любая, даже самая продвинутая защита — это всего лишь техническая задача, у которой есть решение? А юридические риски, которыми так часто пугают, при правильном и этичном подходе сводятся практически к нулю? Парсинг цен — это не магия и не нарушение закона. Это мощный, безопасный и абсолютно легальный инструмент для любого бизнеса в сфере e-commerce, который хочет оставаться конкурентоспособным.3

Эта статья — ваш исчерпывающий путеводитель. Мы проведем вас через все лабиринты современных технологий защиты и тонкостей российского законодательства. Мы не просто дадим вам набор разрозненных техник, а предложим целостную стратегию, которая превратит парсинг из непредсказуемой проблемы в управляемый и стабильный бизнес-процесс. Вы узнаете, как работают системы защиты, какими инструментами их можно обойти, и как собирать нужные данные, не нарушая ни законов, ни этических норм.
Анатомия защиты: как сайты конкурентов защищаются от парсинга
Чтобы эффективно обходить любую защиту, для начала нужно понять, как она устроена. Это похоже на подбор ключа к замку: зная его механизм, вы легко найдете правильный ключ. Современные сайты используют многоуровневую систему обороны, от простых барьеров до сложных комплексов на основе искусственного интеллекта.
Базовые рубежи обороны: первая линия фронта
Это самые простые и распространенные методы, с которыми сталкивается любой начинающий парсер. Они призваны отсечь самый незамысловатый автоматизированный трафик.
Ограничение частоты запросов (Rate Limiting)
Представьте, что на входе в магазин стоит охранник, который пропускает не более одного человека в секунду. Если группа из десяти человек попытается забежать одновременно, он их остановит. Точно так же работает и Rate Limiting: система отслеживает количество запросов с одного IP-адреса за определенный промежуток времени (например, 100 запросов в минуту). Если лимит превышен, сервер временно блокирует этот IP-адрес или начинает отвечать с большой задержкой.1 Это эффективная мера против «прямолинейных» парсеров, которые пытаются скачать весь сайт с максимальной скоростью.
Блокировка по IP-адресу
Это логическое продолжение предыдущего метода. Если какой-то IP-адрес систематически превышает лимиты или ведет себя подозрительно, его могут занести в постоянный «черный список».6 Хотя этот метод кажется простым, он часто бывает неэффективен против профессионального парсинга, который использует тысячи разных IP-адресов.
Проверка HTTP-заголовков (User-Agent)
Это как проверка документов на входе. Когда вы заходите на сайт, ваш браузер отправляет «паспорт» — заголовок User-Agent, в котором указано, например: «я — Google Chrome последней версии на Windows 10». Простые парсеры часто «приходят» либо без такого «паспорта», либо с устаревшим или некорректным, что сразу вызывает подозрения у сервера.6 Система защиты может блокировать все запросы, у которых
User-Agent не похож на заголовок реального популярного браузера.
Файл robots.txt
Важно понимать, что robots.txt — это не техническая защита, а скорее «джентльменское соглашение». Это текстовый файл в корне сайта, где его владелец прописывает правила для «хороших» ботов, в первую очередь для поисковых систем вроде Яндекса и Google. В нем указывается, какие страницы можно сканировать, а какие — нет. Технически ничто не мешает парсеру проигнорировать эти правила, но для систем защиты это первый и самый явный признак «плохого» бота.9
Продвинутые барьеры: когда сайт начинает думать
Когда базовые методы не справляются, в игру вступают более интеллектуальные системы, требующие от парсера не просто отправлять запросы, а имитировать действия человека.
CAPTCHA (тесты на человечность)
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) — это всем известные тесты, где нужно ввести искаженный текст, выбрать картинки с автобусами или поставить галочку в поле «Я не робот». Современные версии, такие как Google reCAPTCHA v2/v3 или hCaptcha, становятся все сложнее. Они могут появляться при обнаружении подозрительной активности и являются серьезным, но вполне преодолимым препятствием для профессиональных парсеров.6
Динамическая загрузка контента (JavaScript/AJAX)
Представьте, что вы пришли в библиотеку за книгой, а вам выдают пустые полки и инструкцию, как их заполнить. Простой парсер, который скачивает исходный HTML-код страницы, видит только эти «пустые полки». Сами данные (цены, описания товаров) подгружаются позже с помощью специальных скриптов (JavaScript), которые выполняются в браузере пользователя.2 Чтобы получить эти данные, парсер должен уметь работать как полноценный браузер: загрузить страницу, выполнить все скрипты и только потом забрать появившийся контент.
«Ловушки» для ботов (Honeypots)
Это хитрая техника, основанная на размещении на странице скрытых ссылок. Обычный пользователь их не видит (например, они скрыты с помощью CSS или имеют цвет фона), но парсер, который слепо сканирует весь HTML-код, переходит по ним. Такой переход немедленно выдает бота, и его IP-адрес отправляется в бан.11
Элитные системы защиты: WAF, CDN и искусственный интеллект
На этом уровне мы сталкиваемся с тяжелой артиллерией — комплексными платформами, которые стоят между сайтом и посетителем, анализируя каждый запрос в реальном времени. Такие сервисы, как Cloudflare, DataDome и Kasada, обрабатывают триллионы запросов в день со всего мира и используют машинное обучение для выявления малейших аномалий в поведении.12
Фингерпринтинг (цифровой отпечаток)
Это ключевая технология современных систем защиты. Они анализируют не только ваш «паспорт» (User-Agent), но и сотни других параметров, создавая уникальный «цифровой отпечаток» вашего устройства и браузера. В этот отпечаток входят:
- Параметры браузера и ОС: какие шрифты у вас установлены, какой язык системы, разрешение экрана, версия браузера.
- Сетевые параметры (TLS и HTTP/2 фингерпринтинг): как ваш браузер устанавливает защищенное соединение (TLS handshake), какие шифры поддерживает, как формирует HTTP/2 запросы.13 Малейшие отклонения от поведения стандартных браузеров могут выдать автоматизированный инструмент.
- Аппаратные характеристики: информация о видеокарте (WebGL), процессоре и другие параметры, доступные через браузерные API.
Совокупность этих данных создает настолько уникальный профиль, что его становится практически невозможно подделать простыми методами.13
Поведенческий анализ
Даже если парсеру удалось создать идеальный цифровой отпечаток, системы защиты анализируют всю сессию пользователя: как он двигает мышкой, с какой скоростью скроллит страницу, как быстро заполняет формы, в какой последовательности посещает страницы.12 Обычный человек сначала зайдет на главную, потом перейдет в категорию, затем откроет несколько товаров. Бот же может сразу начать обходить тысячи карточек товаров по заранее составленному списку прямых ссылок, что является абсолютно неестественным поведением.
Краткий обзор лидеров рынка:
- Cloudflare: Самая распространенная система защиты. Она предлагает разные уровни, от бесплатного Bot Fight Mode, который отсекает самых простых ботов, до корпоративного Bot Management.19 Продвинутые версии Cloudflare присваивают каждому запросу «оценку бота» (bot score) от 1 до 99. Если оценка низкая (например, ниже 30), запрос считается ботом и блокируется или отправляется на дополнительную проверку (например, CAPTCHA).21
- DataDome: Позиционирует себя как решение, использующее многоуровневый искусственный интеллект. Платформа анализирует до 5 триллионов сигналов в день и принимает решение о блокировке за миллисекунды.15 DataDome активно использует сложные JavaScript-челленджи, которые должен выполнить браузер, чтобы доказать свою «человечность», а также поведенческий анализ.13
- Kasada: Отличается особенно агрессивным подходом «виновен, пока не доказано обратное» и отсутствием привычных CAPTCHA.16 Kasada проверяет абсолютно каждый запрос, пропуская его через сложную систему клиентских и серверных проверок. Это делает ее одной из самых сложных систем для обхода.16
Защита от парсинга прошла долгий путь эволюции. Изначально системы блокировали по простым атрибутам — IP-адресу или User-Agent. Это было легко обойти, подменив нужные параметры. В ответ появились более сложные проверки, вроде CAPTCHA и выполнения JavaScript. Но современный этап этой гонки вооружений — это комплексный анализ поведения. Системы больше не смотрят на один отдельный запрос, они оценивают всю совокупность сигналов: отпечаток браузера, сетевые характеристики, движения мыши, историю переходов. Поэтому успешный парсинг сегодня — это уже не просто отправка запросов, а полноценная и дотошная симуляция человеческого поведения на всех уровнях. Именно это объясняет, почему готовые «коробочные» решения для парсинга часто бессильны против серьезно защищенных сайтов и почему для таких задач требуется глубокая экспертиза и кастомная разработка.
Инструментарий для парсинга: от основ к продвинутым техникам
Теперь, когда мы разобрали «замки», пришло время поговорить о «ключах». Этот раздел — практическое руководство по инструментам и техникам, которые позволяют получать данные даже с самых защищенных сайтов. Успешный парсинг — это не один волшебный инструмент, а грамотно выстроенная инфраструктура, где каждый элемент выполняет свою роль.
Прокси-серверы: основа анонимности и стабильности
Прокси-сервер — это ваш главный инструмент для маскировки. Он выступает посредником между вами и целевым сайтом, подменяя ваш реальный IP-адрес своим. Это необходимо для решения двух ключевых задач:
- Обход блокировок по IP: Если один IP-адрес заблокируют, система автоматически переключится на другой.7
- Распределение нагрузки: Отправляя запросы с тысяч разных IP, вы не превышаете лимиты (Rate Limiting) для каждого отдельного адреса и выглядите как множество разных посетителей, а не один агрессивный бот.6
Выбор правильного типа прокси — половина успеха. Они сильно различаются по цене, надежности и уровню доверия со стороны систем защиты.
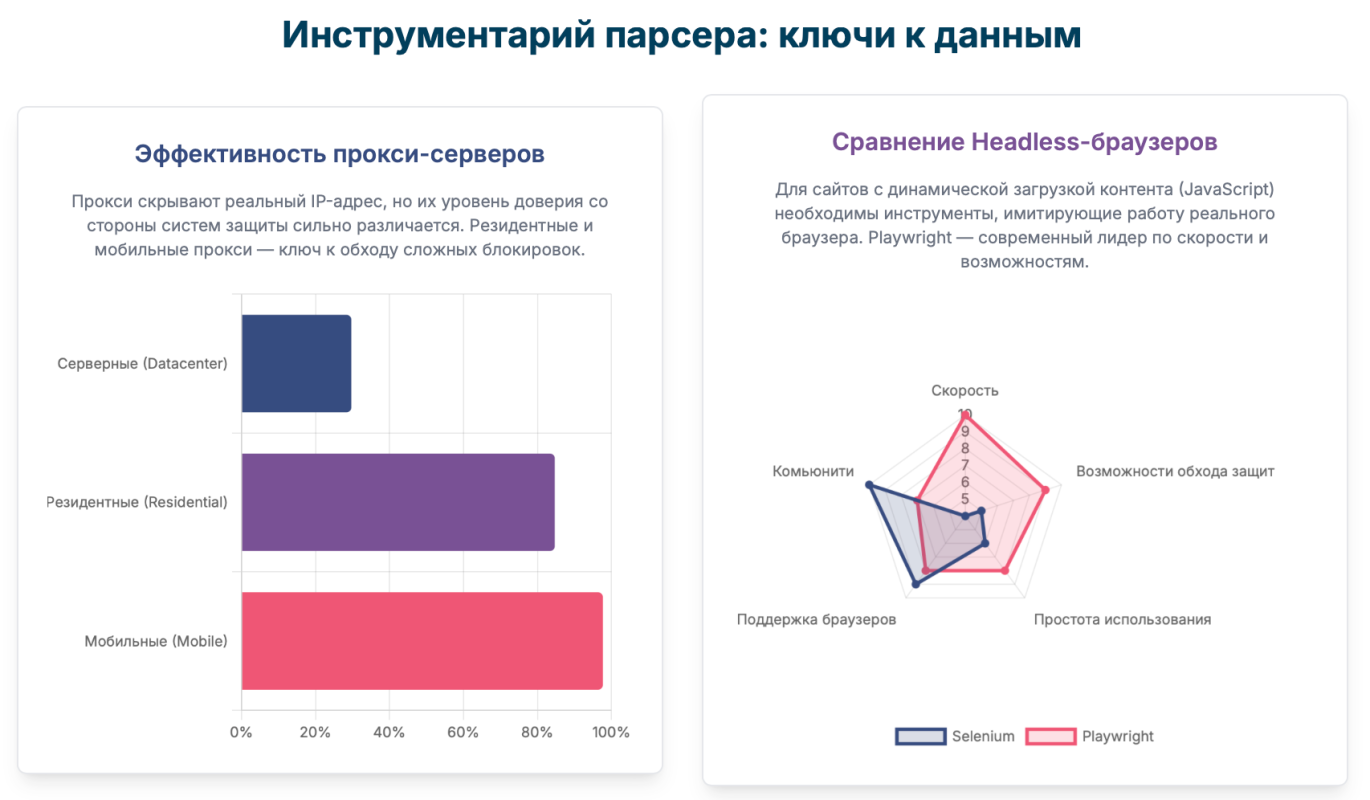
- Серверные (Datacenter) прокси: Это IP-адреса, принадлежащие дата-центрам и хостинг-провайдерам. Они самые дешевые, быстрые и стабильные. Однако их главный недостаток — они легко определяются. Системы защиты имеют списки IP-адресов всех крупных дата-центров и понимают, что реальный пользователь вряд ли будет сидеть в интернете с сервера. Поэтому серверные прокси подходят только для парсинга сайтов с базовой защитой или без нее.26
- Резидентные (Residential) прокси: Это IP-адреса реальных домашних интернет-провайдеров (Ростелеком, Билайн, МТС и т.д.). С точки зрения сайта, запрос с такого IP ничем не отличается от запроса обычного пользователя, сидящего дома. Это обеспечивает максимальный уровень доверия и позволяет обходить сложные системы защиты. Они значительно дороже серверных (оплата обычно идет за объем трафика, а не за количество IP) и могут быть менее стабильными, но для большинства защищенных e-commerce сайтов они абсолютно необходимы.26
- Мобильные (Mobile) прокси: Это IP-адреса мобильных операторов (Мегафон, Tele2 и т.д.). Они обладают наивысшим уровнем доверия. Дело в том, что из-за технологии NAT один и тот же мобильный IP-адрес в один момент времени могут использовать сотни и даже тысячи пользователей. Сайты это знают и крайне неохотно блокируют такие IP, так как рискуют заблокировать множество реальных клиентов. Мобильные прокси — самый дорогой и надежный вариант, который используется для самых сложных и хорошо защищенных целей.28
Таблица 1: Сравнительная характеристика прокси-серверов
| Параметр | Серверные прокси | Резидентные прокси | Мобильные прокси |
| Принцип работы | IP-адреса из дата-центров | IP-адреса домашних провайдеров | IP-адреса мобильных операторов |
| Анонимность/Доверие | Низкое (легко определяются) | Высокое | Максимальное |
| Скорость | Высокая | Средняя/Низкая | Средняя/Низкая |
| Стабильность | Высокая | Средняя (зависит от пользователя) | Высокая (динамические IP) |
| Цена | Низкая (оплата за IP/месяц) | Средняя (оплата за трафик) | Высокая (оплата за трафик) |
| Сценарии использования | Сайты без серьезной защиты, массовые задачи | E-commerce, соцсети, защищенные WAF сайты | Самые сложные сайты, мобильные приложения, работа с соцсетями |
На рынке существует множество провайдеров прокси. Среди надежных сервисов, актуальных для российского рынка, можно выделить: Proxy6, SX.ORG, Proxys.io, IPRoyal, Bright Data.31
Использование хороших прокси — это только начало. Чтобы обмануть продвинутые системы защиты, нужно, чтобы каждый ваш запрос был неотличим от запроса реального пользователя.
- Ротация User-Agent и заголовков: Недостаточно просто подставить User-Agent от последней версии Chrome. Нужно иметь базу из тысяч актуальных User-Agent для разных браузеров и ОС и случайным образом их менять. Важно, чтобы и все остальные HTTP-заголовки (Accept-Language, Accept-Encoding, Accept и т.д.) соответствовали выбранному User-Agent. Несоответствие, например, когда заголовки от Chrome отправляются с User-Agent от Firefox, — это верный признак бота.7
- Управление Cookies: Cookies — это небольшие файлы, которые сайт сохраняет в вашем браузере, чтобы «узнавать» вас при последующих визитах. Парсер должен корректно принимать, хранить и отправлять cookies для каждой сессии. Это создает видимость постоянного пользователя, а не одноразового бота.2
- Заголовок Referer: Этот заголовок указывает, с какой страницы вы пришли на текущую. Бот, который сразу заходит на 1000 страниц товаров по прямым ссылкам, выглядит подозрительно. Пользователь, который перешел на страницу товара со страницы категории или из поиска Google, — нет. Правильное формирование заголовка Referer имитирует естественную навигацию по сайту и значительно снижает подозрительность.11
- Соблюдение «человеческих» интервалов: Ни один человек не способен кликать по ссылкам с интервалом ровно в 0.5 секунды. Парсер должен делать случайные задержки между запросами (например, от 2 до 10 секунд), чтобы его активность была похожа на человеческую.6
Работа со сложными сайтами: парсинг динамического контента
Как мы уже выяснили, многие современные сайты подгружают данные с помощью JavaScript. Чтобы получить эти данные, парсеру нужен собственный «мозг» — движок браузера. Для этого используются так называемые headless-браузеры.
Headless-браузеры — это обычные браузеры (Chrome, Firefox), но без графического интерфейса. Они запускаются на сервере и управляются программно. Скрипт дает им команды: «открой эту страницу», «подожди 5 секунд, пока все загрузится», «нажми на эту кнопку», «забери HTML-код готовой страницы».11 Это позволяет парсить даже самые сложные динамические сайты.
Существует три основных инструмента для управления headless-браузерами:
- Selenium: Старейший и самый универсальный фреймворк. Он поддерживает практически все браузеры и множество языков программирования (Python, Java, C# и др.). Его главный недостаток — он относительно медленный и требует сложной настройки через специальные драйверы (WebDriver).36
- Puppeteer: Библиотека, разработанная Google специально для управления Chrome/Chromium. Она работает напрямую с браузером через DevTools Protocol, что делает ее очень быстрой и мощной. Идеально подходит для работы с JavaScript-сайтами, но ограничена только одним браузером.36
- Playwright: Современный инструмент от Microsoft, созданный той же командой, что и Puppeteer. Он взял все лучшее от предшественника, но добавил поддержку нескольких браузеров (Chrome, Firefox, WebKit) и множество удобных функций, таких как автоматическое ожидание загрузки элементов. На сегодняшний день считается самым быстрым, удобным и мощным решением для автоматизации браузеров.36
Таблица 2: Сравнение Headless-браузеров для задач парсинга
| Критерий | Selenium | Puppeteer | Playwright |
| Поддерживаемые браузеры | Все основные (Chrome, Firefox, Safari, Edge) | Только Chrome/Chromium | Chrome, Firefox, WebKit |
| Поддерживаемые языки | Java, Python, C#, Ruby, JS и др. | Только JavaScript/Node.js | JS, Python, Java, C# |
| Скорость выполнения | Низкая | Высокая | Очень высокая |
| Сложность настройки/использования | Высокая (требует WebDriver) | Средняя | Средняя (более современный API) |
| Комьюнити и документация | Огромное, зрелое | Большое, активное | Растущее, отличная документация |
| Возможности обхода защиты | Базовые. Требует ручной настройки. | Хорошие (есть stealth-плагины) | Отличные (разработан с учетом обхода защит) |
Автоматизация решения CAPTCHA
Даже при использовании всех вышеперечисленных техник, сайт все равно может показать CAPTCHA. Но и это не является непреодолимым препятствием. Парсер не пытается «разгадать» капчу самостоятельно. Вместо этого он интегрируется со специальными сервисами по решению CAPTCHA.
Процесс выглядит так:
- Парсер обнаруживает на странице CAPTCHA.
- Он делает скриншот картинки (или получает специальные параметры для reCAPTCHA) и отправляет их через API на сервис-решатель.35
- На сервисе задачу решает либо живой человек, либо продвинутая нейросеть.
- Сервис возвращает готовый ответ (например, текст с картинки).41
- Парсер вставляет этот ответ в нужное поле на сайте и продолжает свою работу.
Особую сложность представляет reCAPTCHA v3, которая работает в фоновом режиме и оценивает «человечность» пользователя по всей совокупности его поведения, не показывая явных задач. Для ее успешного прохождения часто требуется не просто решить задачу, а иметь высокий «рейтинг доверия»: использовать качественный резидентный прокси, иметь «прогретые» cookies от предыдущих посещений и демонстрировать естественное поведение на странице.42
Таблица 3: Обзор популярных сервисов для решения CAPTCHA
| Сервис | Поддерживаемые типы CAPTCHA | Средняя цена за 1000 решений | Средняя скорость решения |
| RuCaptcha | ReCaptcha V2/V3, hCaptcha, текстовые, FunCaptcha и др. | 44 — 160 руб. | 10-40 сек. 40 |
| Anti-Captcha | reCAPTCHA, hCaptcha, FunCaptcha, Cloudflare и др. | $0.7 — $2 | 13-20 сек. 40 |
| 2Captcha | ReCaptcha V2/V3, Key CAPTCHA, Yandex SmartCaptcha и др. | $1 — $2.99 | 10-40 сек. 40 |
| CapSolver | reCAPTCHA, hCaptcha, DataDome, FunCaptcha, Cloudflare | $0.15 — $3 | <1-10 сек. 40 |
| CapMonster | reCAPTCHA Enterprise, hCaptcha Enterprise, GeeTest, DataDome | 1.76 — 194 руб. | <1-11 сек. 40 |
Становится очевидно, что для обхода современных защит недостаточно просто купить прокси или использовать Playwright. Для сайта с ограничением частоты запросов нужны прокси. Для сайта с динамическим контентом — headless-браузер. Для сайта с CAPTCHA — сервис-решатель. А для сайта, защищенного Cloudflare или DataDome, необходимо все это вместе, да еще и с правильно настроенными цифровыми отпечатками, заголовками и поведенческими паттернами.
Таким образом, профессиональный парсинг — это не запуск одного скрипта. Это построение и поддержка сложной, постоянно адаптирующейся инфраструктуры, где каждый компонент выполняет свою роль. Ротатор прокси, менеджер сессий и cookie, кластер headless-браузеров, интеграция с API решателей CAPTCHA — все это должно работать как единый слаженный механизм. Это объясняет, почему аутсорсинг парсинга профессиональной команде часто оказывается более выгодным и надежным решением, чем попытки создать и поддерживать такую сложную систему внутри компании с нуля.
Парсинг и закон: правовая оценка сбора открытых данных в России
Один из главных вопросов, который волнует бизнес: «А это вообще законно?». Вокруг парсинга существует множество мифов и страхов. Давайте разберемся в юридических тонкостях, опираясь на российское законодательство и судебную практику. Главный тезис: парсинг открытых фактических данных, таких как цены и наименования товаров, при соблюдении определенных правил является законным. Проблемы начинаются там, где заканчиваются открытые данные и начинается сбор персональной, авторской или закрытой информации.

Фундамент законности: право на информацию
Начнем с позитивной ноты. Статья 29 Конституции РФ закрепляет право каждого «свободно искать, получать, передавать, производить и распространять информацию любым законным способом».43 Цены и характеристики товаров, опубликованные на сайте интернет-магазина, являются общедоступной информацией. Любой человек может зайти на сайт и посмотреть их. Парсер делает то же самое, только автоматически. Это создает базовую презумпцию в пользу законности сбора такой информации.
Ключевые ограничения и «красные линии»
Несмотря на право на информацию, существуют четкие границы, которые нельзя переходить. Нарушение этих границ превращает легальный инструмент бизнес-аналитики в правонарушение.
Это самая важная и строгая «красная линия». Парсить персональные данные — ФИО, номера телефонов, адреса электронной почты, адреса проживания — категорически незаконно.44 С 1 марта 2021 года в России действуют поправки в закон «О персональных данных», которые гласят: даже если человек сам опубликовал свои данные в открытом доступе (например, в профиле социальной сети или в объявлении), для их сбора, хранения и дальнейшей обработки требуется получить его отдельное согласие.45 Сбор таких данных без согласия влечет за собой административную ответственность по статье 13.11 КоАП РФ (штрафы для юридических лиц могут быть весьма существенными) и даже уголовную по статье 272.1 УК РФ.43
Вывод для бизнеса: Мониторинг цен и товаров не предполагает сбора персональных данных, поэтому этот риск в нашем случае минимален.
Авторское право и базы данных (ГК РФ, ст. 1334)
Каталог товаров на сайте интернет-магазина с юридической точки зрения может быть признан «базой данных». Согласно статье 1334 Гражданского кодекса РФ, изготовителю базы данных, создание которой потребовало существенных финансовых, материальных или организационных затрат, принадлежит исключительное право извлекать из нее материалы и использовать их.45
Здесь есть ключевой нюанс: закон запрещает извлечение существенной части материалов из базы данных.45 Что это значит на практике?
- Незаконно: Полностью скопировать весь каталог товаров конкурента с уникальными описаниями, фотографиями и характеристиками, чтобы на его основе создать свой собственный интернет-магазин. Это прямое нарушение, которое может повлечь взыскание компенсации в размере до 5 миллионов рублей.49
- Как правило, законно: Регулярно собирать информацию о ценах, наличии и названиях по ограниченному списку товаров (например, 100-200 ключевых позиций) для внутреннего анализа и корректировки собственной ценовой стратегии. Такие действия обычно не рассматриваются как извлечение «существенной части» базы.
Важно также помнить, что сами по себе факты — цена товара, его название, техническая характеристика (например, «диагональ экрана 55 дюймов») — не являются объектами авторского права. Авторским правом защищается творческий контент: уникальные маркетинговые описания, статьи, обзоры, авторские фотографии.50
Коммерческая тайна и неправомерный доступ (ст. 272 УК РФ)
Необходимо четко разделять понятия «парсинг» и «взлом».
- Парсинг — это автоматизированный сбор публично доступной информации, то есть той, которую видит любой обычный посетитель сайта.
- Взлом — это неправомерный доступ к закрытой, охраняемой законом информации (например, к данным в чужом личном кабинете, к базе данных на сервере, к внутренней CRM-системе) путем обхода технических средств защиты.47
Такие действия квалифицируются по статье 272 УК РФ «Неправомерный доступ к компьютерной информации» и влекут за собой серьезную уголовную ответственность. Мы подчеркиваем, что наша компания занимается исключительно этичным парсингом общедоступных данных и никогда не прибегает к методам, которые могут быть расценены как взлом.
Создание помех работе сайта (DDoS-атака)
Слишком частые и агрессивные запросы парсера могут создать чрезмерную нагрузку на сервер конкурента, замедлить его работу или даже сделать сайт недоступным для обычных пользователей. Такие действия могут быть расценены как разновидность DDoS-атаки, за которую также предусмотрена ответственность.44 Именно поэтому так важно соблюдать этические нормы парсинга, о которых мы поговорим ниже.
Прецедентное дело «ВКонтакте vs. Дабл Дата»: уроки для рынка
Этот шестилетний судебный спор стал знаковым для всей IT-отрасли в России. Хотя он закончился мировым соглашением, в ходе его рассмотрения были подняты ключевые вопросы о правомерности сбора общедоступных данных.54
Суть спора: Социальная сеть «ВКонтакте» обвинила компанию «Дабл Дата» в том, что та незаконно извлекает данные из их базы профилей пользователей для создания своего коммерческого продукта (скоринг для банков).54
Ключевые выводы из этого дела, важные для нас:
- Пользовательский контент охраняется: Суд подтвердил, что даже если база данных (сайт) наполняется самими пользователями, она все равно может охраняться законом как объект смежных прав, если владелец платформы понес существенные затраты на ее создание и поддержку. Это напрямую относится к маркетплейсам, классифайдам и агрегаторам.54
- Неопределенность понятия «извлечение»: Дело показало, что в российском праве нет четкого определения, что считать «незаконным извлечением». «Дабл Дата» апеллировала к тому, что их поисковый робот работает по тому же принципу, что и «Яндекс», и не создает конкурирующий продукт, а значит, не наносит прямого вреда «ВКонтакте».54
- Важность фактора вреда: Хотя в российском праве это не закреплено, в мировой практике все большее значение приобретает принцип «нет вреда — нет нарушения». Если парсинг не мешает работе сайта, не используется для создания клона-конкурента и не нарушает другие законы (о персональных данных, об авторском праве), доказать в суде неправомерность таких действий и реальный ущерб становится крайне сложно.54
Наш вывод для клиента: Спор «ВК vs Дабл» касался очень чувствительной темы — парсинга персональных данных и создания на их основе коммерческого продукта. Наш случай — парсинг обезличенных фактических данных (цен) для внутреннего анализа — несет в себе несравнимо меньшие юридические риски.
Этический кодекс парсинга: как оставаться «хорошим парнем»
Чтобы минимизировать любые риски и обеспечить долгосрочный и стабильный сбор данных, мы придерживаемся свода неписаных правил этичного парсинга:
- Уважать robots.txt: Мы всегда проверяем этот файл. Хотя его директивы носят рекомендательный характер, мы стараемся им следовать, чтобы продемонстрировать уважение к владельцу ресурса.9
- Не нагружать сервер: Мы используем адекватные задержки между запросами и, по возможности, настраиваем парсинг на непиковые часы (например, ночью), чтобы не мешать работе сайта и его реальным посетителям.9
- Четко представляться: В User-Agent нашего парсера мы можем указать название нашей компании и контактные данные. Это позволяет владельцу сайта понять, кто собирает данные, и связаться с нами в случае возникновения проблем.
- Использовать API, если он есть: Если сайт предоставляет официальный API (программный интерфейс) для получения данных, мы всегда будем предпочитать его «сырому» парсингу HTML-страниц. Это самый цивилизованный и надежный способ получения информации.51
- Собирать только необходимое: Мы настраиваем парсер так, чтобы он забирал только нужные данные (цены, наличие, названия) и не копировал уникальный контент (описания, статьи, фото), который может быть защищен авторским правом.50
Таким образом, юридическая безопасность парсинга строится на трех китах: ЧТО мы парсим, КАК мы это делаем и ЗАЧЕМ.
- ЧТО: Мы парсим только общедоступные, обезличенные фактические данные (цены, наличие), избегая персональных данных и авторского контента.
- КАК: Мы действуем аккуратно, имитируя поведение обычного пользователя и не создавая избыточной нагрузки, которая могла бы нарушить работу сайта.
- ЗАЧЕМ: Данные используются для внутреннего анализа, формирования собственной ценовой стратегии и принятия взвешенных бизнес-решений, а не для создания продукта-клона или недобросовестной конкуренции.
При таком подходе парсинг цен конкурентов является законной и этичной практикой конкурентной разведки. Наша задача как экспертов — обеспечить, чтобы по всем трем параметрам деятельность нашего клиента оставалась в правовом поле.
Бизнес-результаты: как парсинг цен помогает расти
Теория и технологии важны, но в конечном счете бизнес интересует только одно — результат. Парсинг — это не сбор данных ради данных. Это инструмент для получения конкретных, измеримых преимуществ на высококонкурентном рынке e-commerce.5 Правильно собранная и проанализированная информация о ценах конкурентов напрямую влияет на выручку и маржинальность.
Вот ключевые бизнес-задачи, которые решает автоматизированный мониторинг цен:
- Динамическое ценообразование: Вручную отслеживать цены даже у 5-10 конкурентов по сотням позиций невозможно. Автоматический парсинг позволяет в реальном времени видеть изменения на рынке и мгновенно на них реагировать: снижать цену, если конкурент запустил акцию, или повышать, если у всех конкурентов товар закончился, а у вас он есть.3
- Анализ ассортиментной матрицы: Парсинг помогает понять, какие товары или бренды есть у конкурентов, но отсутствуют у вас. Это позволяет находить «дыры» в собственном ассортименте и выявлять новые точки роста.
- Контроль РРЦ (рекомендованной розничной цены): Для производителей и дистрибьюторов парсинг — незаменимый инструмент для автоматического контроля за тем, как их партнеры-ритейлеры соблюдают ценовую политику. Это помогает поддерживать имидж бренда и избегать ценовых войн.
- Оптимизация промо-акций: Анализируя скидки и акции конкурентов, вы можете планировать собственные маркетинговые кампании более эффективно: запускать акции на те же товары с лучшим предложением или, наоборот, избегать прямого столкновения, предлагая скидки в других категориях.
Успешные кейсы: реальные примеры из российской практики
Давайте рассмотрим, как это работает на примере реальных российских компаний, которые уже используют сервисы мониторинга цен.
Кейс 1: Маркетплейс Securmarket — Контроль цен у тысяч продавцов
- Проблема: Отраслевому маркетплейсу систем безопасности Securmarket, на котором представлено более 14 000 товаров от разных продавцов, было физически невозможно вручную контролировать адекватность цен и помогать партнерам формировать конкурентоспособные предложения.59
- Решение: Было внедрено автоматическое решение для парсинга цен с помощью сервиса Priceva. Это позволило в режиме реального времени собирать и анализировать рыночные данные по всему ассортименту.
- Результат: Маркетплейс получил возможность видеть полную картину рынка, отслеживать ценовые тенденции и оперативно предоставлять своим продавцам экспертные рекомендации по ценообразованию. Это повысило общую конкурентоспособность площадки и лояльность продавцов.59
Кейс 2: «ТехноНИКОЛЬ» — Увеличение доли продаж в рознице
- Проблема: Крупный производитель строительных материалов «ТехноНИКОЛЬ» поставил цель увеличить свою долю продаж в розничном сегменте. Для этого требовалось перейти от статичных прайс-листов к более гибкому и рыночному ценообразованию, учитывающему действия конкурентов.60
- Решение: Компания внедрила автоматизированный мониторинг цен конкурентов. Это позволило получать точные и своевременные данные для принятия обоснованных решений по корректировке собственных цен.
- Результат: Благодаря внедрению эффективной работы с ценами, основанной на данных парсинга, «ТехноНИКОЛЬ» смогла увеличить долю продаж в рознице на 12%.60
Кейс 3: «ЭТК Энергия» — Ускорение контроля дилерских цен
- Проблема: Компания «ЭТК Энергия» столкнулась с тем, что ручной контроль цен у дилеров был крайне медленным и трудоемким процессом. Это не позволяло оперативно реагировать на нарушения РРЦ и ограничивало объем анализируемой информации.60
- Решение: Была внедрена автоматизированная система парсинга, которая взяла на себя всю рутинную работу по сбору и сопоставлению цен у дилеров.
- Результат: Скорость контроля дилерских цен выросла в 4 раза, а объем обрабатываемой информации — в 15 раз. Это привело к более эффективному управлению ценовой политикой, своевременному выявлению демпинга и, как следствие, к стабилизации рынка для бренда.60
Эти примеры наглядно показывают, что парсинг — это не просто техническая возможность, а мощный стратегический инструмент, который при правильном применении приносит бизнесу реальные, измеримые и финансово значимые результаты.
Заключение: парсинг как управляемый и стратегический ресурс
Мы прошли долгий путь: от разбора базовых методов защиты сайтов до анализа сложнейших систем на базе искусственного интеллекта; от выбора правильных прокси-серверов до юридических тонкостей российского законодательства. Теперь можно с уверенностью сделать несколько ключевых выводов.
Во-первых, современные системы защиты от парсинга действительно сложны, но они не являются непреодолимой преградой. Для каждой технологии защиты существует своя технология обхода. Успех заключается не в одном «волшебном» инструменте, а в построении комплексной и гибкой инфраструктуры, способной имитировать поведение реального человека и адаптироваться к меняющимся условиям.
Во-вторых, парсинг открытых, общедоступных цен в России является законным при соблюдении четких и понятных правил. Главное — не пересекать «красные линии»: не собирать персональные данные, не нарушать авторские права и не мешать работе сайтов-источников. Этичный подход не только обеспечивает юридическую безопасность, но и гарантирует долгосрочную и стабильную работу по сбору данных.
И в-третьих, главная ценность парсинга — не в самих данных, а в тех бизнес-решениях, которые на их основе принимаются. Динамическое ценообразование, оптимизация ассортимента, контроль РРЦ — все это прямые пути к увеличению выручки и маржинальности.
Наша компания берет на себя всю техническую сложность и рутину этого процесса. Вам как клиенту не нужно разбираться в типах прокси, тонкостях настройки headless-браузеров или нюансах судебной практики. Вы ставите нам понятную бизнес-задачу — например, «я хочу знать цены на эти 500 товаров у этих 10 конкурентов каждый день», — и получаете готовый, чистый и структурированный отчет для принятия решений. Мы — ваш надежный партнер в мире конкурентной разведки, превращающий сложные технологии в ваш простой и понятный стратегический ресурс.
FAQ: Ответы на часто задаваемые вопросы
Вопрос 1: Это вообще законно — парсить цены конкурентов?
Ответ: Да, при соблюдении трех ключевых условий: 1) вы собираете только открытые фактические данные (цены, названия товаров, наличие), а не персональные данные или контент, защищенный авторским правом (уникальные описания, фото); 2) ваш парсер работает аккуратно и не нарушает работу сайта-источника (не создает DDoS-нагрузку); 3) вы используете полученные данные для внутреннего анализа и формирования собственной ценовой стратегии, а не для создания точной копии сайта конкурента.
Вопрос 2: Что будет, если сайт, который мы парсим, включит защиту от Cloudflare/DataDome?
Ответ: Для нас это штатная рабочая ситуация. Мы модифицируем нашу стратегию сбора данных: перейдем на более качественные резидентные или мобильные прокси, задействуем headless-браузеры с продвинутыми механизмами маскировки цифрового отпечатка и, при необходимости, интегрируем сервисы автоматического решения CAPTCHA. Для вас как для клиента ничего не изменится — вы продолжите получать данные в оговоренные сроки.
Вопрос 3: Мой штатный программист может написать парсер. Зачем мне обращаться к вам?
Ответ: Написать простой парсер для незащищенного сайта действительно несложно. Однако поддержка его работоспособности в долгосрочной перспективе — это постоянная и ресурсоемкая задача. Сайты меняют верстку, усиливают защиту, добавляют новые проверки. Вам потребуется содержать сложную инфраструктуру (пулы прокси, серверы для headless-браузеров) и выделять время разработчика на постоянную доработку кода. Мы же предоставляем парсинг как услугу: вы платите за готовый результат (чистые данные) и полностью избавляетесь от технических проблем и головной боли.
Вопрос 4: Как быстро я могу начать получать данные?
Ответ: Сроки зависят от сложности защиты сайта-источника. Для сайтов с базовой защитой мы можем настроить сбор данных за 1-2 рабочих дня. Для ресурсов, использующих продвинутые системы вроде Kasada или DataDome, может потребоваться до одной недели на исследование, разработку и тестирование индивидуальной стратегии обхода.
Вопрос 5: Какие гарантии вы даете, что меня не заблокируют?
Ответ: Мы гарантируем, что будем использовать весь арсенал современных технологий для минимизации рисков и обеспечения стабильного потока данных. Блокировка отдельных IP-адресов из пула прокси — это нормальная часть процесса; наша система автоматически обнаруживает и заменяет их. Мы выстраиваем процесс парсинга таким образом, чтобы он был максимально незаметным и не приводил к полной блокировке доступа к сайту.
Вопрос 6: Могу ли я парсить данные из личного кабинета или после авторизации?
Ответ: Технически это возможно. Однако с юридической точки зрения это «серая зона», которая может быть расценена как нарушение пользовательского соглашения сайта (Terms of Service) или даже как неправомерный доступ к информации. Мы подходим к таким задачам с особой осторожностью и беремся за них только после тщательного анализа рисков. Парсинг общедоступных цен, не требующий авторизации, — гораздо более безопасный и однозначный с точки зрения закона процесс.
Вопрос 7: Что такое robots.txt и почему это важно?
Ответ: Это текстовый файл на сайте, в котором его владелец указывает рекомендации для автоматических роботов (например, поисковиков), какие страницы не следует сканировать. Это не технический запрет, а скорее просьба или «правило хорошего тона». Мы всегда изучаем robots.txt и стараемся следовать его указаниям. Это часть нашего этичного подхода к парсингу, который помогает избегать конфликтов с владельцами сайтов и обеспечивает долгосрочную стабильность сбора данных.
Источники
- Строим защиту от парсинга. Часть 1: основные принципы предотвращения парсинга, дата последнего обращения: августа 27, 2025, https://www.securitylab.ru/analytics/541667.php
- Как защитить свой сайт от парсинга данных. Практические советы — Сервисы на vc.ru, дата последнего обращения: августа 27, 2025, https://vc.ru/services/262190-kak-zashitit-svoi-sait-ot-parsinga-dannyh-prakticheskie-sovety
- Парсинг цен конкурентов 2025 — решения от Price Control, дата последнего обращения: августа 27, 2025, https://pricecontrol.biz/9-prepyatstvij-pri-parsinge-sajtov/
- Что такое парсинг и что о нём обязательно нужно знать маркетологу — Skillbox, дата последнего обращения: августа 27, 2025, https://skillbox.ru/media/marketing/chto-takoe-parsing-i-chto-o-nyem-obyazatelno-nuzhno-znat-marketologu/
- Как заработать на парсинге сайтов: успехи, провалы, советы, готовый гайд — VC.ru, дата последнего обращения: августа 27, 2025, https://vc.ru/marketing/955378-kak-zarabotat-na-parsinge-saitov-uspehi-provaly-sovety-gotovyi-gaid
- Как защитить свой сайт от парсинга — Shop Manager, дата последнего обращения: августа 27, 2025, https://www.shopmanager.by/blog/2024/04/protect-website-from-scraping/
- Как обойти блокировки сайтов при парсинге? — parsing-cloud.ru, дата последнего обращения: августа 27, 2025, https://parsing-cloud.ru/articles/parsing-saitov-kak-oboiti-blokirovki
- Веб-скрапинг без блокировки Руководство — Bright Data, дата последнего обращения: августа 27, 2025, https://ru-brightdata.com/blog/web-data-ru/web-scraping-without-getting-blocked
- Web Scraping Best Practices and Tools 2025 — ZenRows, дата последнего обращения: августа 27, 2025, https://www.zenrows.com/blog/web-scraping-best-practices
- DOs and DON’Ts of Web Scraping 2025: Best Practices | Medium, дата последнего обращения: августа 27, 2025, https://medium.com/@datajournal/dos-and-donts-of-web-scraping-e4f9b2a49431
- Гайд по успешному веб-скрапингу без блокировок — Blog Froxy, дата последнего обращения: августа 27, 2025, https://blog.froxy.com/ru/the-essential-guide-to-successful-web-scraping
- What is bot management? | How bot managers work — Cloudflare, дата последнего обращения: августа 27, 2025, https://www.cloudflare.com/learning/bots/what-is-bot-management/
- What is Datadome and how to bypass it when web scraping?, дата последнего обращения: августа 27, 2025, https://scrapeway.com/anti-bot-services/datadome?key=anubis123%21
- Cloudflare Bot Management & Protection, дата последнего обращения: августа 27, 2025, https://www.cloudflare.com/application-services/products/bot-management/
- Multi-Layered AI: A New Requirement for Sophisticated Bot Protection — DataDome, дата последнего обращения: августа 27, 2025, https://datadome.co/bot-management-protection/multi-layered-machine-learning-a-new-requirement-for-sophisticated-bot-protection/
- How to Bypass Kasada in 2025 — ZenRows, дата последнего обращения: августа 27, 2025, https://www.zenrows.com/blog/kasada-bypass
- How to Bypass DataDome: Complete Guide 2025 — ZenRows, дата последнего обращения: августа 27, 2025, https://www.zenrows.com/blog/datadome-bypass
- How to Bypass Kasada Anti-Bot When Web Scraping in 2025 — Scrapfly, дата последнего обращения: августа 27, 2025, https://scrapfly.io/blog/posts/how-to-bypass-kasada-anti-scraping-waf
- Get started with Bot Fight Mode — Cloudflare Docs, дата последнего обращения: августа 27, 2025, https://developers.cloudflare.com/bots/get-started/bot-fight-mode/
- Overview · Cloudflare bot solutions docs, дата последнего обращения: августа 27, 2025, https://developers.cloudflare.com/bots/
- Bot Management · Cloudflare bot solutions docs, дата последнего обращения: августа 27, 2025, https://developers.cloudflare.com/bots/get-started/bot-management/
- Bot Protection for Websites, Mobile Apps, & APIs — DataDome, дата последнего обращения: августа 27, 2025, https://datadome.co/products/bot-protection/
- What Is Kasada? — Decodo, дата последнего обращения: августа 27, 2025, https://decodo.com/glossary/kasada
- Веб-скрейпинг: что это такое и зачем он нужен, чем отличается от парсинга и как безопасно извлечь данные с сайта с помощью сервисов — Топвизор–Журнал, дата последнего обращения: августа 27, 2025, https://journal.topvisor.com/ru/seo-kitchen/web-scraping/
- Руководство по веб-скрейпингу на Python — Habr, дата последнего обращения: августа 27, 2025, https://habr.com/ru/companies/ruvds/articles/796885/
- Серверные прокси vs. резидентные прокси — Полное руководство, дата последнего обращения: августа 27, 2025, https://ru-brightdata.com/blog/proxy-101-ru/differences-between-datacenter-and-residential-proxies
- Что такое серверные прокси и когда они могут вам пригодиться — Blog Froxy, дата последнего обращения: августа 27, 2025, https://blog.froxy.com/ru/datacenter-proxies
- Серверные vs. Резидентные прокси: что лучше? — Vadim Kushnir на DTF, дата последнего обращения: августа 27, 2025, https://dtf.ru/id607937/1437121-servernye-vs-rezidentnye-proksi-chto-luchshe
- Резидентные, мобильные или серверные прокси? Взгляд дилетанта — Habr, дата последнего обращения: августа 27, 2025, https://habr.com/ru/articles/796507/
- Мобильные и редитентные прокси: в чем разница? | Блог LTESocks, дата последнего обращения: августа 27, 2025, https://ltesocks.io/ru/blog-ru/otlichie-mobilnyh-i-rezidentnyh-proksi/
- Лучшие сайты для покупки прокси: топ-10, рейтинг 2024 — DTF, дата последнего обращения: августа 27, 2025, https://dtf.ru/topraiting/3251206-luchshie-saity-dlya-pokupki-proksi-top-10-reiting-2024
- Девять лучших прокси-провайдеров 2025 года: сравнение всех функций — Bright Data, дата последнего обращения: августа 27, 2025, https://ru-brightdata.com/blog/proxy-101-ru/best-proxy-providers
- Лучшие прокси сервера: 10 надежных сервисов — Проверено на vc.ru, дата последнего обращения: августа 27, 2025, https://vc.ru/provereno/2151403-nadezhnye-proksi-servera-10-luchshikh-servisov
- Best Headless Browsers for Web Scraping: Tools and Examples — Latenode, дата последнего обращения: августа 27, 2025, https://latenode.com/blog/best-headless-browsers-for-web-scraping-tools-and-examples
- Python Selenium: парсинг динамических сайтов на примерах — Timeweb Cloud, дата последнего обращения: августа 27, 2025, https://timeweb.cloud/tutorials/python/selenium-parsing-dinamicheskih-sajtov
- Puppeteer vs Selenium vs Playwright: Best Web Scraping Tool?, дата последнего обращения: августа 27, 2025, https://www.promptcloud.com/blog/puppeteer-vs-selenium-vs-playwright-for-web-scraping/
- 10 лучших безголовых браузеров для парсинга: плюсы и минусы, дата последнего обращения: августа 27, 2025, https://blog.adspower-ru.com/docs/best-headless-browsers-web-scraping-pros-cons
- Which to Choose for Web Scraping: Selenium vs Puppeteer vs Playwright — Medium, дата последнего обращения: августа 27, 2025, https://medium.com/@browserscan/which-to-choose-for-web-scraping-selenium-vs-puppeteer-vs-playwright-d007f5ec938e
- Dynamic Web Scraping tools Comparison: Selenium vs Puppeteer vs Playwright, дата последнего обращения: августа 27, 2025, https://www.vocso.com/blog/dynamic-web-scraping-tools-comparison-selenium-vs-puppeteer-vs-playwright/
- Антикапча — лучшие сервисы автоматического распознавания и …, дата последнего обращения: августа 27, 2025, https://seo.ru/blog/10-luchshih-servisov-dlya-raspoznavaniya-kapchi/
- 12 лучших сервисов/API для решения проблемы Captcha для веб-скрапинга и автоматизации — Защита от скликивания рекламы — Clickfraud, дата последнего обращения: августа 27, 2025, https://clickfraud.ru/12-luchshih-servisov-api-dlya-resheniya-problemy-captcha-dlya-veb-skrapinga-i-avtomatizaczii/
- Как обойти капчу при парсинге сайтов? — xmldatafeed.com, дата последнего обращения: августа 27, 2025, https://xmldatafeed.com/kak-obojti-kapchu-pri-parsinge-sajtov/
- Законно ли парсить сайты в России? Даем правовое основание — xmldatafeed.com, дата последнего обращения: августа 27, 2025, https://xmldatafeed.com/zakon/
- Парсинг сайтов — законно ли? — Веб-студия Яворского, дата последнего обращения: августа 27, 2025, https://yavorsky.ru/stati/parsingsaitovzakonno/
- Легально ли брать контент из базы данных? — Habr, дата последнего обращения: августа 27, 2025, https://habr.com/ru/companies/onlinepatent/articles/681090/
- Парсинг общедоступных данных запрещен с 1 марта — Habr, дата последнего обращения: августа 27, 2025, https://habr.com/ru/articles/544788/
- Что такое парсинг, зачем он нужен и законно ли парсить данные | Unisender, дата последнего обращения: августа 27, 2025, https://www.unisender.com/ru/glossary/chto-takoe-parsing/
- УК РФ Статья 272.1. Незаконные использование и (или) передача, сбор и (или) хранение компьютерной информации, содержащей персональные данные, а равно создание и (или) обеспечение функционирования информационных ресурсов, предназначенных для ее… \ КонсультантПлюс, дата последнего обращения: августа 27, 2025, https://www.consultant.ru/document/cons_doc_LAW_10699/deefead19003ba8266e85fbf42fc31f60ed3c698/
- Парсинг сайтов: законно или нет? Юридические способы защиты, дата последнего обращения: августа 27, 2025, https://ezybrand.ru/blog/kak-zashhitit-svoj-veb-resurs-ot-kopirovaniya/
- Парсинг сайтов: как с точки зрения закона выглядит один из самых полезных ИТ- инструментов по миру (и в России)? — Habr, дата последнего обращения: августа 27, 2025, https://habr.com/ru/articles/340302/
- Парсинг сайтов. Россия и мир. Как с точки зрения закона выглядит один из самых полезных инструментов? — Право на vc.ru, дата последнего обращения: августа 27, 2025, https://vc.ru/legal/64328-parsing-saitov-rossiya-i-mir-kak-s-tochki-zreniya-zakona-vyglyadit-odin-iz-samyh-poleznyh-instrumentov
- Правовое обоснование парсинга открытых данных в России: подробный анализ, дата последнего обращения: августа 27, 2025, https://xmldatafeed.com/pravovoe-obosnovanie-parsinga-otkrytyh-dannyh-v-rossii-podrobnyj-analiz/
- Парсинг: законно ли им пользоваться — Altcraft CDP, дата последнего обращения: августа 27, 2025, https://altcraft.com/ru/glossary/parsing-chto-eto-takoe-i-mogut-li-za-nego-oshtrafovat
- Дело «ВКонтакте» vs «Дабл Дата» — Legal Insight, дата последнего обращения: августа 27, 2025, https://legalinsight.ru/articles/delo-vkontakte-vs-dabl-data/
- Парсинг данных: что это и все, что нужно знать о парсер — IT рейтинг UA, дата последнего обращения: августа 27, 2025, https://it-rating.ua/parsing-dannyih-chto-eto-i-vse-chto-nujno-znat-o-nem
- Парсинг данных в России: этические аспекты и законодательство, дата последнего обращения: августа 27, 2025, https://dataparsing.pro/dataparsing-blog/parsing-dannyh-v-rossii-eticheskie-aspekty-i-zakonodatelstvo/
- Ethical Web Scraping: Principles and Practices — DataCamp, дата последнего обращения: августа 27, 2025, https://www.datacamp.com/blog/ethical-web-scraping
- Что такое парсинг и что можно парсить для маркетинга — UIS, дата последнего обращения: августа 27, 2025, https://www.uiscom.ru/blog/chto-takoe-parsing-i-chto-mozhno-parsit-dlya-marketinga/
- Кейсы мониторинга цен конкурентов для магазинов — Priceva, дата последнего обращения: августа 27, 2025, https://priceva.ru/blog/category/kejsy/price_tracking
- Сервис мониторинга цен Priceva. Репрайсинг. Мониторинг РРЦ., дата последнего обращения: августа 27, 2025, https://priceva.ru/
ПОХОЖИЕ ПУБЛИКАЦИИ:
 Headless-браузеры для парсинга: Полное руководство по автоматизации, обходу блокировок и масштабированию
Headless-браузеры для парсинга: Полное руководство по автоматизации, обходу блокировок и масштабированию  Полное руководство по мониторингу цен конкурентов на Wildberries и Ozon
Полное руководство по мониторингу цен конкурентов на Wildberries и Ozon  Мониторинг цен конкурентов: полное руководство по парсингу, праву и стратегиям для бизнеса
Мониторинг цен конкурентов: полное руководство по парсингу, праву и стратегиям для бизнеса  Парсинг цен в российском e-commerce: полное руководство
Парсинг цен в российском e-commerce: полное руководство  Полное руководство по аналитике конкурентов на маркетплейах Wildberries, Ozon и Яндекс.Маркет
Полное руководство по аналитике конкурентов на маркетплейах Wildberries, Ozon и Яндекс.Маркет  Лучший парсер цен 2023 года (парсинг цен с сайтов электронной коммерции)
Лучший парсер цен 2023 года (парсинг цен с сайтов электронной коммерции)  101 Термин про парсинг сайтов: Полное руководство для экспертов и начинающих
101 Термин про парсинг сайтов: Полное руководство для экспертов и начинающих  Парсинг простых веб-страниц с Beautiful Soup: Полное руководство для начинающих и не только
Парсинг простых веб-страниц с Beautiful Soup: Полное руководство для начинающих и не только  Парсинг данных: Полное руководство от А до Я
Парсинг данных: Полное руководство от А до Я  10 лучших платформ для отслеживания и мониторинга цен конкурентов для бизнеса
10 лучших платформ для отслеживания и мониторинга цен конкурентов для бизнеса
МЕДИЦИНСКИЕ УСЛУГИ
База всех компаний в категории: ТАЙСКИЙ МАССАЖ
РЕКЛАМНЫЕ УСЛУГИ
База всех компаний в категории: ПОЛИГРАФИЧЕСКИЕ УСЛУГИ
ПРОИЗВОДСТВЕННЫЕ УСЛУГИ
База всех компаний в категории: ПОКРЫТИЕ МЕТАЛЛОМ
НАУЧНО ИССЛЕДОВАТЕЛЬСКАЯ ОРГАНИЗАЦИЯ
База всех компаний в категории: НАУЧНО ИССЛЕДОВАТЕЛЬСКАЯ ОРГАНИЗАЦИЯ
ПРОИЗВОДСТВЕННЫЕ УСЛУГИ
База всех компаний в категории: ПРОИЗВОДИТЕЛЬ АВТОМОБИЛЕЙ
ТОРГОВЫЕ УСЛУГИ
База всех компаний в категории: АВТОПОГРУЗЧИКИ
ПРОИЗВОДСТВЕННЫЕ УСЛУГИ
База всех компаний в категории: МЕХОВАЯ КОМПАНИЯ
ЗДРАВООХРАНЕНИЕ И СОЦИАЛЬНЫЕ УСЛУГИ
База всех компаний в категории: ОКВЭД 87.10 — ДЕЯТЕЛЬНОСТЬ ПО МЕДИЦИНСКОМУ УХОДУ С ОБЕСПЕЧЕНИЕМ ПРОЖИВАНИЯ