











Общие вопросы парсинга
Руководство для защиты сайтов от парсинга данных

Май
(или, по крайней мере, руководство о том, как усложнить парсинг данных)
В сущности говоря, защита сайта от парсинга означает, что вам нужно сделать так, чтобы скриптам и роботам было сложно извлечь необходимые данные из вашего сайта, но при этом не усложняя настоящим пользователям (людям) и поисковикам доступ к данным.
К несчастью, добиться такого положения дел сложно, и вам придется выбирать между защитой от парсинга и ухудшением доступности данных для настоящих пользователей и поисковиков.


ИНТЕРНЕТ-МАГАЗИНЫ


ПРОИЗВОДИТЕЛИ




МЕДИЦИНСКИЕ КЛИНИКИ


РЕСТОРАНЫ И КАФЕ


Парсинг также известен как: веб-парсинг (webscraping), считывание данных с экрана (screenscraping), добыча веб-данных (web data mining), сбор веб-данных (web harvesting) или извлечение веб-данных (web data extraction). Чтобы препятствовать парсингу, полезно знать, как работают парсеры и что мешает им работать эффективно — об этом и пойдет речь в данной статье.
Как правило, эти программы для парсинга данных разработаны для извлечения определенной информации из вашего сайта, как например: статей, результатов поиска, подробных данных о товарах или информации об альбомах и артистах. Обычно люди парсят сайты ради получения определенных данных, чтобы повторно использовать их на своем собственном сайте (и таким образом делать деньги на вашем контенте!), разработать альтернативную клиентскую часть (так называемый «фронтенд») или даже просто для частного исследования или в целях анализа данных.
По сути дела, есть разнообразные типы парсеров, и каждый работает по-разному:
- Программы-обходчики, или «пауки», как например поисковый робот Google, или программы вроде HTtrack для копирования сайтов, которые посещают ваш сайт и рекурсивно переходят по ссылкам на другие страницы, чтобы собирать на них данные. Программы-обходчики иногда используются для целенаправленного парсинга определенных данных зачастую в сочетании со средством анализа HTML-кода для извлечения требующихся данных из каждой веб-страницы.
- Скрипты командной оболочки: иногда популярные инструменты для Unix используются для парсинга: Wget или Curl — для скачивания веб-страниц, а Grep (Regex) — для извлечения нужных данных. Обычно для этих целей пишется скрипт командной оболочки. Они представляют собой простейший тип парсеров. Но при этом и самый ненадежный тип, поэтому никогда не пытайтесь анализировать HTML-код с помощью регулярных выражений для извлечения необходимых данных! Таким образом, скрипты относятся к такому типу парсеров, с которыми легче всего бороться, ломать и даже обманывать их.
- Многочисленные HTML-парсеры и HTML-анализаторы, как например основанные на Jsoup, Scrapy и других программных средствах. Подобно парсерам на основе регулярных выражений и скриптов командной оболочки, такие парсеры работают посредством извлечения данных из ваших веб-страниц, ориентируясь на шаблоны в HTML-коде и игнорируя всё остальное.
Таким образом, например, если на вашем сайте есть функция поиска, такой парсер может отправить HTTP-запрос для поиска данных, а затем получить все ссылки и заголовки из HTML-кода страницы с результатами поиска. Он может делать это сотни раз, отправляя разные поисковые запросы, чтобы получить только ссылки и заголовки результатов поиска. Подобные парсеры — самые распространенные.
- Экранные парсеры, как например основанные на Selenium или PhantomJS, которые фактически открывают ваш сайт в настоящем браузере, запускают JavaScript, отправляют AJAX-запросы и выполняют прочие действия, а затем получают из веб-страницы необходимый текст, обычно используя для этого следующие операции:
- Получение HTML-кода из браузера после завершения загрузки вашей веб-страницы и выполнения JavaScript-кода с последующим применением анализатора HTML-кода для извлечения необходимых данных или текста. Это наиболее распространенные операции, и поэтому многие методы вывода HTML-анализаторов из строя в этом случае тоже применимы.
- Формирование снимка экрана, на котором отображаются полностью загруженные в браузере («отрендеренные») веб-страницы, и последующие использование OCR для извлечения необходимого текста из снимка. Такой подход используется редко и только специализированные парсеры с подобным функционалом могут вам это устроить.
С экранными парсерами на основе браузера справиться трудно, поскольку они выполняют скрипты, формируют HTML-код и могут вести себя как живые люди, просматривающие ваш сайт.
- Веб-сервисы для парсинга данных из сайтов, как например ScrapingHub или Kimono. Фактически есть люди, работа которых — разобраться в том, как собрать данные на вашем сайте и вытащить контент для дальнейшего использования другими людьми. Эти веб-сервисы иногда применяют крупные сети прокси-серверов и постоянно меняют IP-адреса, чтобы обходить ограничения и запреты доступа, поэтому защищаться от них особенно проблематично.
Неудивительно, что противодействовать профессиональным веб-сервисам для парсинга данных сложнее всего, но если вы сделаете так, чтобы разобраться в том, как парсить ваш сайт, было бы тяжело и затратно по времени, то такие онлайн-сервисы (и люди, которые платят им за парсинг данных) вряд ли возьмутся за сбор данных на вашем сайте.
- Встраивание вашего сайта в веб-страницы другого сайта с помощью фреймов и встраивание вашего сайта в мобильные приложения.
Хотя технически это не парсинг, но всё равно проблема, так как мобильные приложения (для Android и iOS) могут встраивать ваш сайт и даже внедрять свой код на языках CSS и JavaScript, таким образом полностью меняя внешний вид вашего сайта и показывая только нужную им информацию, как например сам контент статьи или список результатов поиска, и скрывая такие элементы, как например заголовки, подвалы или рекламные объявления.
- Копирование и вставка руками человека: люди могут копировать и вставлять ваш контент, чтобы использовать его где угодно. К сожалению, с этим мало что можно сделать.
У этих разных типов парсеров есть много общего, и многие парсеры будут вести себя схожим образом, даже несмотря на то, что они используют разные технические приемы и подходы для сбора вашего контента.
Как защищаться от парсинга
Вот несколько общих подходов для обнаружения парсеров и противодействия им:
Отслеживайте свои журнальные записи (логи) и шаблоны трафика; ограничивайте доступ, если видите необычную активность
Регулярно проверяйте свои логи и в случае необычной активности, свидетельствующей об автоматическом доступе к данным, то есть о работе парсеров, как например многочисленные схожие операции из одного и того же IP-адреса, вы сможете запретить или ограничить доступ к данным.
А именно следующие идеи:
- Ограничение скорости получения данных:
Разрешайте пользователям (и парсерам) выполнять ограниченное количество действий за определенное время. Например, разрешайте какому-либо конкретному пользователю или посетителю с каким-либо конкретным IP-адресом искать что-либо только несколько раз в секунду. Это замедлит парсеры и сделает их неэффективными. Также вы могли бы отображать капчу, если действия осуществляются слишком быстро или быстрее, чем мог бы их совершать настоящий пользователь.
- Обнаруживайте необычную активность:
Если вы видите необычную активность, как например: много похожих друг на друга запросов из определенного IP-адреса, кто-то просматривает чрезмерное количество веб-страниц или пользуется поиском подозрительно часто, то вы можете закрыть доступ к данным или показывать капчу при обработке последующих запросов.
- Не просто отслеживайте активность и ограничивайте скорость доступа по IP-адресу, а используйте и другие показатели
Если вы действительно блокируйте подозрительные источники запросов к сайту или ограничиваете скорость, то делайте это не просто применительно к IP-адресу — вы можете использовать другие показатели и методы распознавания определенных пользователей или парсеров. Среди некоторых показателей, которые могут помочь вам обнаружить определенных пользователей или парсеры, присутствуют:
- Насколько быстро пользователи заполняют формы и в какое место на кнопке они щелкают.
- Вы можете собирать много информации с помощью JavaScript, как например: размер или разрешение экрана, часовой пояс, установленные шрифты. Всё это вы можете использовать для обнаружения пользователей.
- HTTP-заголовки и их порядок, особенно заголовок User-Agent.
Например, если вы получаете много запросов из одного IP-адреса, во всех из которых используется один и тот же User-Agent и размер экрана (определяется с помощью JavaScript), а пользователь (в этом случае — парсер) всегда щелкает по кнопке в одном и том же месте и через равные промежутки времени, то, скорее всего, это экранный парсер, и вы можете временно заблокировать подобные запросы, то есть заблокировать все запросы с таким пользовательским агентом и размером экрана, которые отправляются из этого конкретного IP-адреса. Так вы не доставите неудобств настоящим пользователям, у которых тот же IP-адрес, потому что, например, эти люди пользуются общим интернет-соединением.
Кроме того, можно пойти еще дальше, поскольку вы можете обнаружить схожие запросы, даже если они исходят из разных IP-адресов, а значит имеет место распределенный парсинг данных (парсер, использующий бот-сеть или сеть прокси-серверов). Если вы получаете много запросов, приходящих из разных IP-адресов, но идентичных по всем остальным признакам, то можете заблокировать их. Опять же, будьте осторожны и случайно не заблокируйте настоящих пользователей сайта.
Это может быть эффективным против экранных парсеров, которые исполняют JavaScript-код, так как вы можете получить о них много сведений.
Вопросы на Security Stack Exchange, связанные с этой темой:
- Как однозначно обнаружить пользователей с одним и тем же внешним («белым») IP-адресом? — если хотите узнать больше.
- Почему люди используют блокировки IP-адресов («баны»), если IP-адреса часто меняются? — если хотите узнать о ограничениях этих методов.
Простым способом реализации ограничения скорости может быть временный запрет доступа на определенное время, однако использование капчи может быть более удачным вариантом — посмотрите ниже по тексту параграф про капчи.
Требуйте от пользователей проходить регистрацию и авторизацию, то есть вход на сайт
Требуйте создания учетных записей для получения возможности просматривать ваш контент, если это осуществимо на вашем сайте. Такое условие — хорошее препятствие для парсеров, но и для настоящих пользователей тоже.
- Если вы требуете от посетителей сайта создавать учетные записи и проходить процедуру входа на сайт, то сможете отслеживать действия пользователей и парсеров. Таким образом, вы сможете легко замечать, когда определенная учетная запись используется для парсинга данных, и блокировать («банить») ее. Такие приемы, как ограничение скорости или обнаружение чрезмерного обращения к сайту (наподобие использования функции поиска огромное количество раз за короткое время) становится проще использовать, поскольку вы можете обнаруживать конкретные парсеры, а не просто IP-адреса.
Чтобы скрипты не могли создавать много учетных записей, рекомендуется:
- Требовать адрес электронной почты при регистрации и проверять этот адрес, отправляя на него ссылку, по которой нужно перейти для активации учетной записи. Допускать создание только одной учетной записи на один адрес электронной почты.
- Требовать от пользователя решить капчу при регистрации или создании учетной записи, чтобы опять же мешать скриптам создавать учетные записи.
Требование создавать учетную запись для получения возможности просматривать контент приведет к тому, что пользователи и поисковые системы будут покидать ваш сайт. Если вы введете такое требование, то пользователи пойдут на какой-нибудь другой сайт.
Запрещайте доступ к сайту, если запросы идут из облачного хостинга и IP-адресов парсинговых веб-сервисов
Иногда парсеры будут размещаться и функционировать на веб-хостингах, например на Amazon Web Services, Google app Engine или виртуальных выделенных серверах (VPS). Ограничивайте доступ к вашему сайту или показывайте капчу для запросов, которые исходят из IP-адресов, используемых такими веб-сервисами облачного хостинга. Также вы можете запрещать доступ к сайту IP-адресам, используемым веб-сервисами парсинга данных.
Аналогичным образом вы также можете ограничивать доступ IP-адресам, используемым поставщиками виртуальных частных сетей или прокси-серверов, так как парсеры могут использовать такие прокси-сервера с целью избежания того, чтобы их многочисленные запросы были замечены администраторами или владельцами сайтов.
Учитывайте, что, запрещая доступ к сайту прокси-серверам и виртуальным частным сетям, вы негативно повлияете на настоящих пользователей.
Сделайте свое сообщение об ошибке неявным, если действительно запрещаете доступ к сайту
Если вы в самом деле запрещаете или ограничиваете доступ, то следует убедиться, что вы при этом не сообщаете парсеру о причинах блокировки, таким образом подсказывая разработчикам парсера как починить его. Поэтому было бы плохой идеей показывать веб-страницы с ошибкой с текстом наподобие:
- Из вашего IP-адреса поступает слишком много запросов, пожалуйста, повторите попытку позже.
- Ошибка, заголовок User-Agent отсутствует!
Вместо этого показывайте дружелюбное сообщение об ошибке, которое не сообщает парсеру о причинах ее появления. Гораздо лучше написать что-нибудь вроде:
- Извините, что-то пошло не так. Вы можете связаться со службой поддержки через helpdesk@example.com в случае, если проблема никуда не уйдет.
Также такое сообщение гораздо более понятное для настоящих пользователей, если они когда-либо увидят такую веб-страницу с ошибкой. Кроме того, подумайте том, чтобы показывать капчу при последующих запросах, вместо того чтобы жестко запрещать доступ, если вдруг настоящий пользователь увидит сообщение об ошибке. Благодаря этому вы не запретите добропорядочным пользователям доступ к сайту, и поэтому не будете вынуждать их связываться с вами.
Используйте капчи, если подозреваете, что к вашему сайту обращается парсер
Капчи («Completely Automated Test to Tell Computers and Humans apart» — «Полностью автоматизированный публичный тест Тьюринга для различения компьютеров и людей») очень эффективны против парсеров. К несчастью, они при этом очень эффективно раздражают пользователей.
В связи с этим они полезны, когда вы подозреваете, что за каким-либо посетителем сайта, возможно, скрывается парсер, и хотите остановить парсинг, не прибегая к запрету доступа к данным, чтобы ненароком не запретить доступ настоящему пользователю, если ваши подозрения оказались напрасны. Вы могли бы подумать о том, чтобы показывать капчу перед предоставлением доступа к контенту, если подозреваете, что имеете дело с парсером.
Моменты, о которых нужно помнить при использовании капч:
- Не изобретайте «велосипед», а используйте что-нибудь вроде reCaptcha от Google: это будет гораздо проще, чем реализовывать капчу самостоятельно, и гораздо удобнее для пользователей, чем решение на основе размытого и искаженного текста, которое вы могли бы создать сами. Кроме того, разработчику скриптов гораздо сложнее решить готовую стороннюю капчу, чем простое изображение, формируемое и отправляемое вашим сайтом.
- Не включайте решение капчи (ответ на нее) в HTML-разметку. Например, во Всемирной паутине есть сайт, на котором решение капчи находится на самой веб-странице. Хотя оно довольно хорошо спрятано, такой подход делает капчу в значительной степени бесполезной. Не делайте что-нибудь вроде этого. Опять же, используйте веб-сервис наподобие reCaptcha, и вы не столкнетесь с такого рода проблемой, если конечно будете пользоваться им правильно.
- Решение капч может быть поставлено на поток: существуют веб-сервисы для решения капч, где реальные люди решают капчи в больших количествах и за небольшую плату. С другой стороны, в этом случае использование reCaptcha — хорошая идея, поскольку у них есть средства защиты, как например относительно короткий промежуток времени, который есть у пользователя на решение капчи. Маловероятно, что подобного рода веб-сервис кто-то будет использовать применительно к вашему сайту, если только ваши данные не представляют большую ценность.
Отправляйте свой текстовый контент в виде изображения
Вы можете преобразовывать текст в изображение на стороне сервера, а затем отправлять и отображать его посетителю, что будет препятствовать работе простых парсеров, извлекающих текст.
Однако такой подход плох с точки зрения программ для чтения с экрана, поисковых систем, производительности и, скорее всего, всего остального. Кроме того, поступать так не всегда законно из-за проблем с доступностью контента, например в связи с Законом об американцах с ограниченными возможностями (Americans with Disabilities Act). Также парсеры могут легко обойти такую защиту с помощью оптического распознавания символов, поэтому не используйте такой подход.
Вы можете осуществить что-то подобное с помощью CSS-спрайтов, но в этом случае имеют место быть те же проблемы.
Не давайте доступ ко всем своим данным
Если возможно, не давайте возможность скрипту или боту получить набор всех ваших данных. Например, допустим, что у вас есть новостной сайт с большим количеством отдельных статей. Вы могли бы сделать эти статьи доступными только через поиск по сайту и, если у вас нет списка всех статей сайта и их URL-адреса больше нигде не встречаются, кроме как в результатах поиска, то статьи будут доступны только через поиск по сайту. Такой подход означает, что скрипту, запрограммированному на получение всех статей с вашего сайта, придется искать все возможные фразы, которые могут появляться в ваших статьях, чтобы найти все статьи, что будет затратно по времени, чудовищно неэффективно и, хотелось бы надеяться, заставит парсер сдаться.
Это будет неэффективным, если:
- Бот или скрипт в любом случае не хочет получить весь набор ваших данных, или же такой набор ему не нужен.
- Ваши статьи передаются пользователям по URL-адресу, который выглядит наподобие example.com/article.php?articleId=12345. Такая подача статей (и схожих данных) позволит парсерам просто перебрать все articleId-ы, то есть идентификаторы статей, и таким образом запросить у сайта все статьи.
- Есть другие способы в конечном итоге найти все статьи, как например создание скрипта, который бы посещал ссылки в статье, которые ведут на другие статьи.
- Поиск чего-нибудь наподобие «и» или «это» позволяет найти почти всё что угодно, поэтому учтите этот момент. Однако вы можете защититься от такого приема, возвращая только 10 или 20 результатов.
- Вам нужно, чтобы поисковые системы находили ваш контент.
Не разглашайте сведения о ваших API, конечных точках обработки запросов и подобных вещах
Убедитесь, что вы не выставляете напоказ любые свои API, даже если делаете это непреднамеренно. Например, если вы используете AJAX или сетевые запросы из Adobe Flash или Java-приложения для загрузки своих данных, что крайне не рекомендуется, то постороннему не составит никакого труда посмотреть на сетевые запросы из веб-страницы и разобраться в том, куда эти запросы идут, а затем выполнить обратный инжиниринг и использовать эти конечные точки обработки запросов в парсере. Убедитесь, что ваши конечные точки обработки запросов трудны для понимания (обфусцированы), и усложните их использование посторонними, как это описано выше.
Что можно сделать для борьбы с HTML-анализаторами и парсерами
Так как HTML-анализаторы работают посредством извлечения контента из веб-страниц на основе поддающихся распознаванию шаблонов в HTML-коде, мы можем намеренно изменить эти шаблоны, чтобы сломать такие парсеры или даже обмануть их. Большинство из этих советов также применимы к другим парсерам наподобие «пауков» и экранных парсеров.
Часто редактируйте свой HTML-код
Парсеры, которые обрабатывают HTML-разметку напрямую, делают это при помощи извлечения контента из определенных распознаваемых частей вашей HTML-страницы. Например, если все веб-страницы на вашем сайте включают в себя тег div с идентификатором article-content, который содержит текст статьи, то тогда будет несложно написать скрипт, который бы посещал все веб-страницы статей вашего сайта и извлекал текстовое содержимое блока div с идентификатором article-content из каждой веб-страницы статьи, и вуаля — у такого парсера будут все статьи вашего сайта в формате, пригодном для любого использования.
Если вы будете часто менять HTML-код и структуру своих веб-страниц, то такие парсеры не смогут продолжить свою работу.
- Вы можете часто, может быть даже автоматически, менять идентификаторы и классы элементов в своей HTML-разметке. Таким образом, если ваш div.article-content станет чем-то вроде div.b1c32dea53faf8 и будет меняться каждую неделю, парсер сначала будет работать прекрасно, но через неделю сломается. Позаботьтесь о том, чтобы длина ваших идентификаторов или классов тоже менялась, ведь в противном случае парсер в качестве альтернативного подхода будет использовать шаблон div.[14-любых-символов] для поиска нужного div. Также опасайтесь других подобных уязвимостей в защите от парсинга…
- Если нет никакого способа найти необходимый контент в HTML-разметке, парсер сделает это, отталкиваясь от ее структуры. Таким образом, если все ваши веб-страницы со статьями структурно схожи в том отношении, что каждый div внутри другого div, идущего после тега h1, представляет собой контент статьи, то парсеры на основе этой структурной закономерности смогут заполучить контент статьи. С другой стороны, для борьбы с этим вы можете периодически или время от времени добавлять или удалять дополнительную разметку в своем HTML-коде. Например, добавлять дополнительные теги div или span. С современной обработкой HTML на стороне сервера эта задача не должна быть слишком сложной.
Нужно иметь в виду следующее:
- Такую защиту от парсинга будет утомительно и сложно реализовать, поддерживать и отлаживать.
- Вы будете препятствовать кэшированию. А именно, если вы меняете идентификаторы или классы своих HTML-элементов, то это потребует внесения соответствующих изменений в ваши файлы со стилями и в файлы с JavaScript-кодом, а значит, что каждый раз, когда вы редактируете их, браузеру придется скачать их повторно. Это приведет к более долгой загрузке веб-страниц у постоянных посетителей сайта и к возросшей нагрузке на сервер. Если вы меняете разметку только раз в неделю, то такая операция не приведет к появлению серьезной проблемы.
- Более продвинутые парсеры всё равно смогут заполучить ваш настоящий контент, делая выводы о том, где он находится. Например, зная, что крупный и единственный блок текста на странице, скорее всего, и есть настоящая статья. Такой прием делает всё же возможным обнаружение и извлечение необходимых данных из вашей веб-страницы. Boilerpipe занимается именно такими вещами.
Главное — проследите за тем, что скрипту было нелегко найти настоящий и необходимый ему контент на любой из схожих веб-страниц.
Кроме того, обратите внимание на вопрос Как помешать зависимым от XPath сборщикам данных собирать контент веб-страниц, чтобы подробно узнать о том, как это можно реализовать на PHP.
Редактируйте свою HTML-разметку на основе местоположения пользователя
Этот совет похож на предыдущий. Если вы отправляете посетителям сайта разную HTML-разметку в зависимости от местоположения или страны (это определяется по IP-адресу), то такой подход может сломать парсеры, которые доставляют собранный контент каким-либо пользователям. Например, если кто-то разрабатывает мобильное приложение, которое собирает данные на вашем сайте, то поначалу оно будет работать отлично, но сломается на этапе его распространения пользователям, так как эти пользователи могут находиться в другой стране и поэтому получат другую HTML-разметку, на работу с которой встроенный парсер не рассчитан.
Часто редактируйте свою HTML-разметку и таким образом активно обманывайте парсеры!
Пример: на вашем сайте есть функция поиска, расположенная по URL-адресу example.com/search?query=somesearchquery и возвращающая следующий HTML-код:

Как вы могли догадаться, из такой разметки легко извлечь данные: всё, что нужно сделать парсеру — это отправить на URL-адрес поиска запрос и извлечь необходимые данные из полученного HTML-кода. Помимо описанного выше периодического редактирования HTML-кода, вы можете также оставить старую разметку со старыми идентификаторами и классами внутри нее, скрыть ее с помощью CSS и заполнить поддельными данными, таким образом делая непригодными собранные парсером данные. Вот так можно было бы изменить веб-страницу с результатами поиска:
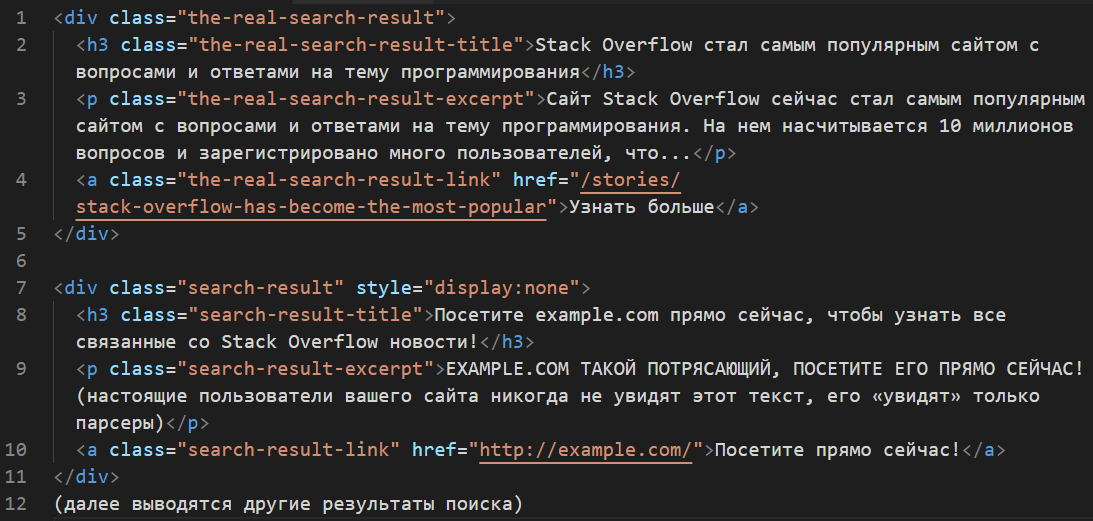
Такое изменение HTML-кода означает, что парсеры, написанные для извлечения данных из HTML-кода на основе классов или идентификаторов, с виду будут продолжать работать, но получат поддельные данные или даже рекламные объявления, то есть данные, которые настоящие пользователи никогда не увидят, поскольку они скрыты при помощи CSS.
Обманывайте парсер: вставляйте поддельные скрытые данные в свою веб-страницу в качестве приманки
В дополнение к предыдущему примеру вы можете добавить невидимые элементы-приманки в свою HTML-разметку, чтобы «ловить» парсеры. Пример разметки, которую можно было бы добавить к описанной ранее веб-странице с результатами поиска:

Парсер, разработанный для получения всех результатов поиска, соберет и этот результат, как и любой из других, настоящих результатов на веб-странице, а затем перейдет по ссылке в поисках необходимого ему контента. Реальный человек никогда не увидит этот располагающийся в начале результат-ловушку благодаря тому, что он скрыт с помощью CSS, и не перейдет по ссылке. Настоящая программа-обходчик, работа которого вами приветствуется, как например поисковый робот Google, тоже не будет переходить по такой ссылке, потому что вы можете запретить доступ к /scrapertrap/ в своем файле robots.txt. Но только не забудьте сделать это!
Вы можете запрограммировать scrapertrap.php на что-нибудь вроде запрета доступа к данным для IP-адреса, который перешел по такой ссылке, или вынуждать решать капчу при обработке всех последующих запросов, приходящих из этого IP-адреса.
- Не забывайте запретить доступ к своей приманке (/scrapertrap/) в своем файле robots.txt, чтобы поисковые роботы не попадали в нее.
- Вы можете или даже должны сочетать этот совет с предыдущим, связанным с частым редактированием HTML-кода.
- В данном случае частое изменение тоже актуально, так как парсеры в конечном счете научатся обходить такую защиту. Меняйте URL-адрес и текст ловушки. Кроме того, стоит подумать об изменении встроенного CSS, применяемого для сокрытия ловушки, и вместо этого использовать атрибут id и внешний файл со стилями, поскольку парсеры научатся избегать любого элемента с атрибутом style, в котором прописан CSS для сокрытия контента. Также попробуйте включать эту ловушку время от времени, чтобы парсер поначалу работал, но через некоторое время ломался. К тому же это применимо и к предыдущему совету.
- Остерегайтесь того, что злоумышленники могут публиковать на форуме или где угодно что-нибудь вроде [img]http://yoursite.com/scrapertrap/scrapertrap.php[img] и таким образом атаковать добропорядочных пользователей, когда они посещают такой форум и их браузер переходит по URL-адресу вашей ловушки, из-за чего ваш сайт будет отказывать пользователям в обслуживании и испытывать повышенную нагрузку. Поэтому предыдущий совет об изменении URL-адреса важен вдвойне. Также вы можете проверить заголовок Referer.
Отправляйте поддельные и бесполезные данные, если обнаружите парсер
Если вы обнаружили, что какие-либо запросы к сайту явно исходят от парсера, вы можете предоставлять ему фальшивые и бесполезные данные, благодаря чему данные, которые парсер получает из вашего сайта, будут испорчены. Также рекомендуется сделать невозможным выявление отличий между такими поддельными данными и настоящими данными, чтобы парсеры не знали, что их обманывают.
К примеру, допустим, у вас есть новостной сайт. Если вы обнаружили, что его посещает парсер, то вместо запрета доступа к данным просто предоставляйте поддельные сгенерированные случайным образом статьи — это сделает малопригодными данные, которые собирает парсер. Если вы сделаете свои поддельные данные или статьи неотличимыми от оригинала, то усложните парсерам процесс получения необходимых им данных, а именно подлинных, настоящих статей.
Не принимайте запросы, если User-Agent пустой или отсутствует
Зачастую недостаточно качественно разработанные парсеры не будут отправлять заголовок User-Agent в своих запросах, в то время как все браузеры и поисковые роботы делают это.
Если вы получаете запрос, в котором отсутствует заголовок User-Agent, то можете отображать капчу, просто запрещать или ограничивать доступ, отправлять фальшивые данные, как описано выше, или поступать как-то иначе.
Данный заголовок не составит труда подделать, но в качестве меры защиты от некачественно написанных парсеров эту проверку стоит реализовать.
Не принимайте запросы, если их User-Agent используется одним из популярных парсеров; заносите такие характерные для парсеров заголовки в черный список
В некоторых случаях парсеры будут использовать User-Agent, который не использует ни один реальный браузер или поисковый робот, как например:
- «Mozilla». Именно так — больше никаких других символов. Реальный браузер никогда не будет использовать просто «Mozilla» в пользовательском агенте.
- «Java 1.7.43_u43». По умолчанию HttpUrlConnection, доступный в языке программирования Java, использует что-то наподобие такого User-Agent.
- «BIZCO EasyScraping Studio 2.0»
- «wget», «curl», «libcurl» и прочие. Wget и cURL иногда используются для примитивного парсинга данных.
Если вы обнаружите, что определенная строка пользовательского агента используется на вашем сайте парсерами, и ее не используют настоящие браузеры или «добропорядочные» программы-обходчики, то вы можете тоже добавить такой User-Agent в свой черный список.
Проверьте заголовок Referer
В дополнение к предыдущему параграфу вы можете также проверить заголовок Referer (да, именно Referer, а не Referrer), так как некачественные парсеры могут не отправлять его или всегда отправлять один и тот же — иногда это может быть «google.com». К примеру, если пользователь приходит на веб-страницу статьи со страницы результатов поиска по сайту, проверьте, что заголовок Referer присутствует и указывает на эту страницу с результатами поиска.
Обратите внимание, что:
- Реальные браузеры тоже не всегда его отправляют.
- Его несложно подделать.
Но в качестве дополнительной меры против некачественных парсеров, возможно, стоит реализовать проверку этого заголовка.
Если пользователь сайта не запрашивает ресурсы (CSS, изображения), то, возможно, его нельзя считать реальным браузером
Реальный браузер почти всегда будет запрашивать и скачивать ресурсы, как например изображения и файлы со стилями. HTML-анализаторы и парсеры не будут это делать, так как их интересуют только сами веб-страницы и их контент.
Вы можете журналировать запросы к своим ресурсам, и если увидите много запросов на получение только HTML-кода, то, возможно, их отправляет парсер.
Учтите, что поисковые роботы, старые мобильные устройства, программы для чтения с экрана и неправильно настроенные устройства тоже могут не запрашивать ресурсы.
Для просмотра вашего сайта вы можете требовать от пользователей, чтобы у них была включена поддержка файлов cookie Такой подход отпугнет неопытных и начинающих разработчиков парсеров, однако парсер легко может отправлять файлы cookie. Если вы действительно будете использовать эти файлы и требовать включения их поддержки на стороне пользователя, то сможете благодаря ним отслеживать действия пользователей и парсеров и таким образом реализовывать ограничение скорости, запрет доступа или отображение капч применительно к пользователю, а не IP-адресу.
Например, когда пользователь выполняет поиск, вы можете установить куки, идентифицирующий пользователя. Когда пользователь просмотрит страницы с результатами поиска, вы сможете проверить этот куки. Если пользователь открывает все результаты поиска (вы сможете определить это благодаря куки), то, скорее всего, это парсер.
Использование куки может быть неэффективным, так как парсеры тоже могут вместе со своими запросами отправлять куки и при необходимости избавляться от них. Кроме того, вы помешаете настоящим пользователям, у которых отключены куки, получать доступ к вашему сайту, если без них он не функционирует.
Обратите внимание, что если вы используете JavaScript для установки и извлечения куки, то таким образом вы заблокируете парсеры, которые не исполняют JavaScript-код, поскольку они не могут извлекать и отправлять куки в своих запросах.
Используйте JavaScript и AJAX для загрузки своего контента
Вы можете использовать JavaScript в сочетании с AJAX для загрузки своего контента после загрузки самой веб-страницы. Такой прием сделает контент недоступным для HTML-анализаторов, которые не исполняют JavaScript-код. Зачастую это эффективный способ борьбы с начинающими и неопытными разработчиками парсеров.
Имейте в виду, что:
- Использование JavaScript для загрузки фактического контента ухудшит пользовательский опыт работы с сайтом и его производительность.
- Поисковые системы тоже могут не исполнять JavaScript-код, в связи с чем они не смогут индексировать ваш контент. Возможно, это не проблема для страниц с результатами поиска по сайту, но может стать проблемой для каких-то других веб-страниц, как например для страниц со статьями.
- Программист, разрабатывающий парсер и знающий свое дело, может обнаружить и использовать в своих целях конечные точки обработки запросов, из которых загружается контент.
Сделайте запутанными и непонятными свою HTML-разметку, сетевые запросы, отправляемые с помощью скриптов, и всё остальное
Если вы используете AJAX и JavaScript для загрузки своих данных, то сделайте передаваемыми данные непонятными для постороннего, то есть обфусцируйте их. Например, вы можете закодировать свои данные на сервере при помощи чего-нибудь простого наподобие base64 или более сложного с несколькими слоями обфускации, побитовым сдвигом и, возможно, даже шифрованием, а затем декодировать и отобразить эти данные клиенту после их извлечения из сервера с помощью AJAX. Благодаря такому подходу кто-либо, изучающий сетевой трафик, не сразу разберется в том, как работает ваша веб-страница и как загружаются данные. Кроме того, посторонним будет труднее напрямую запрашивать данные из ваших конечных точек обработки запросов, потому что им придется заниматься обратным инжинирингом вашего алгоритма дешифрования.
- Если вы используете AJAX для загрузки данных, то рекомендуется усложнить использование конечных точек обработки запросов без предварительной загрузки веб-страницы. Сделать это можно, например, при помощи запрашивания сеансового ключа в качестве параметра, который вы можете встроить в свой JavaScript-код или HTML-разметку.
- Кроме того, во избежание отправки дополнительных сетевых запросов вы можете встраивать свои запутанные (обфусцированные) данные прямо в исходную HTML-страницу и использовать JavaScript для приведения данных в нормальное состояние и их отображения пользователю. Используя такой прием, вы существенно усложните извлечение данных, осуществляемое при помощи парсера, который работает только с HTML-кодом и не выполняет JavaScript-код, так как разработчику парсера придется выполнять обратный инжиниринг вашего JavaScript-кода, а его вам тоже рекомендуется сделать запутанным и непонятным.
- Возможно, вам захочется регулярно менять свои методы обфускации, чтобы ломать парсеры, которые уже разгадали ваши нынешние методы.
Однако у подобных приемов есть несколько недостатков:
- Такую защиту от парсинга будет утомительно и сложно реализовать, поддерживать и отлаживать.
- Это будет неэффективно против парсеров, в том числе экранных, которые действительно выполняют JavaScript-код и затем извлекают данные. Хотя большинство простых HTML-парсеров не выполняют JavaScript-код.
- Это сделает ваш сайт неработоспособным для реальных пользователей, если они отключили JavaScript в своем браузере.
- Пострадает производительность и увеличится время загрузки веб-страниц.
Советы нетехнического характера
Возможно, что ваш поставщик хостинга предоставляет защиту от роботов и парсеров
Например, CloudFlare, как и AWS, предоставляет защиту от роботов и парсинга, которую вам нужно всего лишь активировать. Также есть mod_evasive — модуль для Apache, который позволяет вам с легкостью реализовать ограничение скорости, с которой пользователи запрашивают данные.
Попросите людей не собирать данные, и некоторые отнесутся к этому с уважением
Вам стоит попросить людей, например в условиях вашего пользовательского соглашения, не парсить ваш сайт. Некоторые люди действительно прислушаются к вашим словам и не будут без разрешения собирать данные на вашем сайте.
Найдите адвоката
Адвокаты знают, как бороться с нарушением авторских прав, и могут отправить соответствующее письменное предупреждение. DMCA тоже полезен в решении этого вопроса.
Этот подход используют Stack Overflow и Stack Exchange.
Сделайте свои данные доступными — предоставьте API
Такая идея может показаться неразумной, но вы можете сделать свои данные легкодоступными и требовать, чтобы при использовании ваших данных был указан их источник и ссылка на ваш сайт. Может быть, даже брать за это деньги…
Более того, Stack Exchange предоставляет API, но требует указывать источник данных.
Прочие советы
- Найдите баланс между удобством использования сайта реальными пользователями и защитой от парсеров: всё, что вы делаете, так или иначе негативно повлияет на пользовательский опыт, поэтому вам нужно будет находить компромиссы.
- Не забывайте про свой сайт и приложение для мобильных устройств: если у вас есть мобильная версия вашего сайта, остерегайтесь того, что парсеры могут собирать на ней данные. Если у вас есть мобильное приложение, оно тоже может стать целью парсинга, и посторонние могут изучить сетевой трафик, чтобы разобраться в конечных точках обработки запросов, которые связаны с REST и используются приложением.
- Если вы поддерживаете специальную версию своего сайта для определенных браузеров, например «урезанную» версию для ранних версий Internet Explorer, то не забывайте о том, что парсеры также могут собирать там данные.
- Используйте эти советы в сочетании друг с другом и выберите те из них, которые лучше всего вам подходят.
- Парсеры могут собирать данные у других парсеров: если существует сайт, который показывает контент, собранный на другом сайте, то другие парсеры тоже могут собирать данные на сайте этого парсера.
Какой способ — самый эффективный?
Наиболее эффективными методами считаются:
- Частое изменение HTML-разметки.
- Ловушки и поддельные данные.
- Использование запутанных и трудных для понимания JavaScript-скриптов, AJAX-запросов и файлов cookie.
- Ограничение скорости получения данных, а также обнаружение парсеров и последующий запрет доступа к данным.
ПОХОЖИЕ ПУБЛИКАЦИИ:
 Топ-12 облачных средств защиты от DDoS-атак для сайтов малого и среднего бизнеса
Топ-12 облачных средств защиты от DDoS-атак для сайтов малого и среднего бизнеса  Руководство по лучшим инструментам визуализации данных в 2023 году
Руководство по лучшим инструментам визуализации данных в 2023 году  Лучшие инструменты для парсинга данных (Обзор ТОП-10)
Лучшие инструменты для парсинга данных (Обзор ТОП-10)  12 лучших инструментов веб-парсинга в 2023 году для извлечения онлайн-данных Лучшие бесплатные и платные инструменты для парсинга сайтов и товаров… 12 лучших инструментов и программного обеспечения для парсинга сайтов и мониторинга цен
12 лучших инструментов веб-парсинга в 2023 году для извлечения онлайн-данных Лучшие бесплатные и платные инструменты для парсинга сайтов и товаров… 12 лучших инструментов и программного обеспечения для парсинга сайтов и мониторинга цен  Лучшие инструменты для парсинга веб-сайтов — исчерпывающий список
Лучшие инструменты для парсинга веб-сайтов — исчерпывающий список  Лучшие книги для изучения парсинга сайтов
Лучшие книги для изучения парсинга сайтов  Подборка более 22 лучших инструментов для парсинга сайтов
Подборка более 22 лучших инструментов для парсинга сайтов
АПТЕКИ
БАЗА ПРОИЗВОДИТЕЛЕЙ И ПРОДАВЦОВ МЕДТЕХНИКИ И МЕДИЦИНСКИХ ИЗДЕЛИЙ
DIY
Аксон
ТРАНСПОРТНЫЕ УСЛУГИ
База всех компаний в категории: КАРШЕРИНГ
ПРОИЗВОДСТВЕННЫЕ УСЛУГИ
База всех компаний в категории: ПЕЧАТИ И ШТАМПЫ ИЗГОТОВЛЕНИЕ
ИСКУССТВО И КУЛЬТУРА
База всех компаний в категории: ОРГАНИЗАЦИЯ МАОРИ
ТОРГОВЫЕ УСЛУГИ
База всех компаний в категории: ЭЛЕКТРОСАМОКАТЫ ГИРОСКУТЕРЫ МОНОКОЛЁСА
ПРОИЗВОДСТВЕННЫЕ УСЛУГИ
База всех компаний в категории: ПРОДУКТЫ ГЛУБОКОЙ ЗАМОРОЗКИ
СФЕРА РАЗВЛЕЧЕНИЙ
База всех компаний в категории: ВОДОПАДЫ