













Бизнес-аналитика,Закон и парсинг сайтов,Интернет,Общие вопросы парсинга,Программирование
Парсинг цен в российском e-commerce: полное руководство

Авг
Краткое содержание
В условиях жесткой конкуренции на российском рынке e-commerce, где цены могут меняться несколько раз в день, ручной мониторинг — это путь к поражению. Автоматизированный сбор данных, известный как парсинг или веб-скрейпинг, перестал быть просто технической задачей; он стал критически важным инструментом для динамического ценообразования, анализа ассортимента и понимания рыночных трендов.1
Однако парсинг — это не просто написание скрипта. Это навигация по сложному лабиринту из технических барьеров (динамическая загрузка контента через JavaScript, CAPTCHA, блокировки по IP) и, что более важно, серьезных юридических рисков, специфичных для российского законодательства. Неправильный подход может привести не к прибыли, а к судебным искам, блокировкам и финансовым потерям.
Это руководство — ваш исчерпывающий навигатор в мире сбора веб-данных. Мы проведем вас от базовых концепций до продвинутых техник обхода защиты и реверс-инжиниринга внутренних API сайтов. Мы детально разберем прецедентные судебные дела в России, чтобы вы могли действовать уверенно и минимизировать правовые риски. Мы предоставим работающие примеры кода на Python с использованием самых актуальных библиотек и фреймворков, а также поможем сделать главный стратегический выбор: создавать собственную систему парсинга или использовать готовые решения от специализированных провайдеров. Цель этого материала — превратить хаос веб-данных в ваше структурированное и устойчивое конкурентное преимущество.
Глава 1: Основы парсинга: от сбора данных к бизнес-стратегии
1.1. Что такое парсинг (веб-скрейпинг) простыми словами?
Парсинг (от английского to parse — разбирать, анализировать) — это автоматизированный процесс сбора общедоступной информации с веб-сайтов и ее последующего структурирования для анализа и использования.3 Программа, которая выполняет этот процесс, называется парсером или скрейпером.
Чтобы лучше понять суть, можно провести простую аналогию. Представьте, что вам нужно составить таблицу с ценами на 100 моделей смартфонов у пяти разных ритейлеров. Вручную это означало бы открыть 500 вкладок в браузере, найти на каждой странице цену, название товара, артикул и скопировать все это в Excel. Такая работа заняла бы несколько часов, была бы утомительной и наверняка содержала бы ошибки из-за человеческого фактора.

Парсер автоматизирует этот процесс. Вместо человека по сайтам «ходит» робот (программа), который выполняет ту же самую работу, но в тысячи раз быстрее и без ошибок. Этот робот и есть парсер.
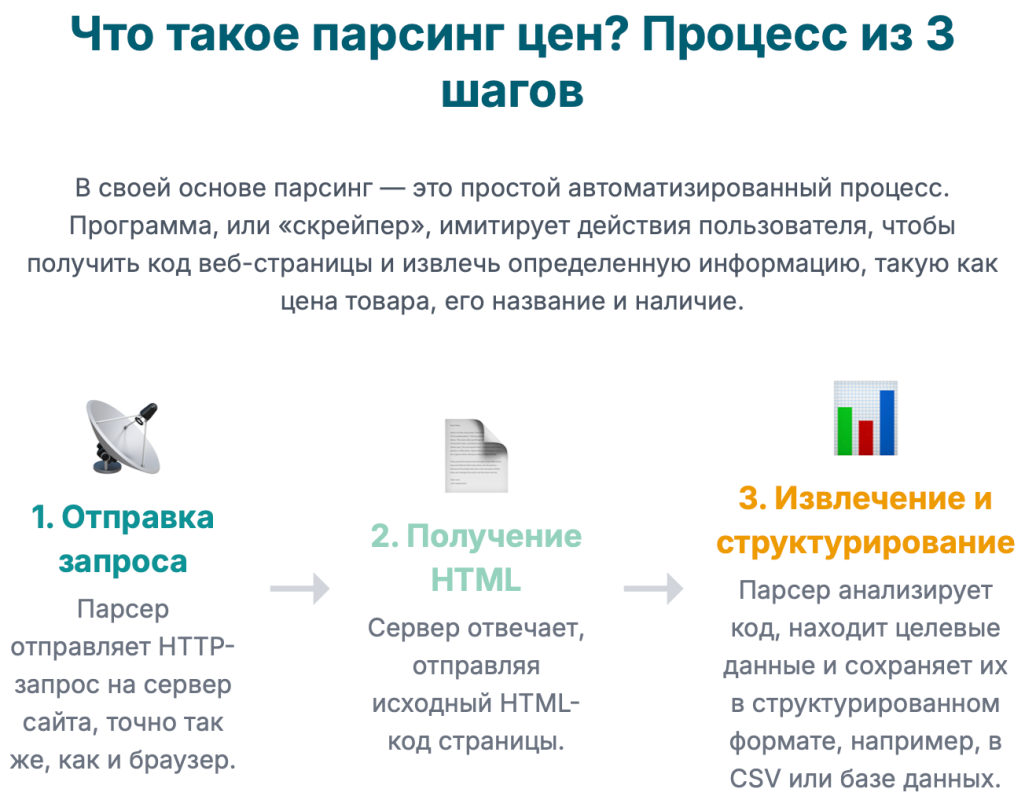
С технической точки зрения, базовый процесс парсинга состоит из трех простых шагов 3:
- Отправка запроса. Парсер отправляет HTTP-запрос (чаще всего типа GET) на указанный URL-адрес, точно так же, как это делает ваш браузер, когда вы вводите адрес сайта в адресную строку.
- Получение ответа. Веб-сервер, на котором расположен сайт, в ответ на запрос отправляет HTML-код страницы. Это тот самый код, который браузер использует для отрисовки веб-страницы, которую вы видите на экране.
- Извлечение и структурирование данных. Получив HTML-код, парсер начинает его анализировать. Он «прочесывает» этот код, как по карте, в поисках заранее определенных элементов. Например, он может искать цену товара, которая находится внутри HTML-тега <span class=»price»>19 990 ₽</span>. Найдя нужный фрагмент, парсер извлекает из него только полезную информацию (в данном случае, число 19990) и сохраняет ее в заранее определенном формате, например, в ячейку таблицы CSV, поле в базе данных или JSON-файл.
Таким образом, парсинг — это мощный инструмент для преобразования неструктурированной информации, представленной на веб-страницах, в структурированные данные, готовые для анализа и принятия решений.
1.2. Стратегическая ценность для интернет-магазина
В сфере электронной коммерции, где конкуренция максимальна, а маржинальность часто невысока, владение актуальной информацией о рынке перестает быть преимуществом и становится условием выживания. Парсинг данных предоставляет эту информацию, превращаясь из технического инструмента в стратегический актив. Вот ключевые направления, где парсинг приносит максимальную пользу интернет-магазину:
- Конкурентный анализ и динамическое ценообразование. Это основная и наиболее мощная область применения парсинга в e-commerce. Возможность в реальном времени отслеживать цены конкурентов на аналогичные товары позволяет реализовывать сложные ценовые стратегии. Например, можно автоматически устанавливать цену на 1% ниже, чем у ближайшего конкурента, чтобы всегда быть в топе ценовых агрегаторов. Или, наоборот, если конкурент поднял цену или у него закончился товар, система может автоматически увеличить вашу цену, чтобы максимизировать маржу.1 Регулярный мониторинг также помогает своевременно реагировать на акции и распродажи конкурентов, запуская контрпредложения.5
- Обогащение каталога и мониторинг ассортимента. Наполнение нового интернет-магазина товарами — колоссальная по объему ручная работа. Парсинг позволяет автоматизировать этот процесс, собирая информацию (названия, описания, технические характеристики, изображения) с сайтов поставщиков или производителей и автоматически создавая карточки товаров в вашем каталоге. Это экономит сотни, если не тысячи, человеко-часов.1 Кроме того, регулярный парсинг сайтов конкурентов позволяет отслеживать появление у них новых товаров или категорий, что помогает выявлять пробелы в собственном ассортименте и вовремя расширять его.
- Анализ рынка и выявление трендов. Какие товары сейчас в тренде? Какие получают больше всего положительных отзывов? На какие товары падает спрос? Ответы на эти вопросы можно получить, собирая и анализируя данные не только о ценах, но и о рейтингах, количестве отзывов, наличии товара и его позициях в категориях «бестселлеров» на крупных маркетплейсах.5 Эта информация является бесценным источником для принятия решений о закупках, формировании складских запасов и планировании маркетинговых кампаний.
- SEO-оптимизация и контент-маркетинг. Парсинг может быть использован для решения ряда задач в области поисковой оптимизации. Например, можно парсить сайты конкурентов для анализа их семантического ядра (ключевых слов, по которым они продвигаются), структуры сайта, а также для поиска популярных тем для статей в блоге. Кроме того, парсинг может помочь в проведении технического аудита собственного сайта, например, для поиска битых ссылок или мониторинга скорости загрузки страниц.8
В современном бизнесе данные о рынке, получаемые с помощью парсинга, становятся таким же важным источником для принятия решений, как и внутренние данные о продажах из CRM-системы или складские отчеты. Происходит фундаментальный сдвиг: парсинг перестает быть разовой IT-задачей по извлечению данных и превращается в непрерывный процесс, интегрированный в контур бизнес-аналитики и стратегического планирования. Ответственность за него смещается от чисто технических отделов к отделам маркетинга, продаж и развития продукта. Компании, которые продолжают рассматривать парсинг как вспомогательную техническую задачу, неизбежно проигрывают тем, кто встроил его в свои ежедневные бизнес-процессы и циклы принятия решений.7
2.1. Законен ли парсинг в России? Разбор «серой зоны»
Вопрос о законности парсинга — один из самых сложных и неоднозначных. На первый взгляд, все просто: сбор общедоступной информации не может быть незаконным. Если данные открыты для просмотра любому пользователю в браузере, то и программа-парсер, по сути, делает то же самое, просто автоматизируя процесс.8 В российском законодательстве нет прямого запрета на парсинг как на технологию.
Однако, как это часто бывает в юриспруденции, «дьявол кроется в деталях». Законность парсинга определяется не самим фактом сбора данных, а тремя ключевыми аспектами: что вы собираете, как вы это делаете и как вы потом используете собранную информацию. Нарушение любого из этих аспектов может перевести ваши действия из легальной «серой зоны» в область прямого правонарушения.
Существует несколько ключевых правовых рисков, которые необходимо учитывать при планировании любого проекта по парсингу в России 10:
- Нарушение авторских и смежных прав: Каталог товаров интернет-магазина может рассматриваться как база данных, защищенная законом.
- Нарушение законодательства о персональных данных: Сбор и обработка любой информации, позволяющей идентифицировать человека (ФИО, телефон, email), строго регулируется.
- Создание чрезмерной нагрузки на сервер: Слишком агрессивный парсинг может нарушить работу сайта, что может быть квалифицировано как неправомерный доступ к компьютерной информации.
- Нарушение условий использования сайта: Многие сайты в своих пользовательских соглашениях прямо запрещают автоматизированный сбор данных.
Каждый из этих рисков заслуживает отдельного и подробного рассмотрения.
2.2. Авторское право на базы данных: Статьи 1260 и 1334 ГК РФ
Это, пожалуй, самый значимый и наименее очевидный риск для тех, кто занимается парсингом в России. Многие ошибочно полагают, что если сами по себе данные (например, цена товара или его название) не являются объектом авторского права, то и собирать их можно без ограничений. Однако российское законодательство защищает не только сам контент, но и структуру, в которую он организован, то есть базу данных.
- Статья 1260 Гражданского кодекса РФ определяет базу данных как «представленную в объективной форме совокупность самостоятельных материалов…, систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью электронной вычислительной машины (ЭВМ)». Важно отметить, что в этой же статье интернет-сайт прямо упоминается как вид составного произведения, а его создателю принадлежат авторские права на осуществленные им «подбор или расположение материалов».12 Это означает, что сам по себе каталог товаров на сайте Ozon или Wildberries уже является объектом, защищенным авторским правом как результат творческого труда по его составлению.
- Статья 1334 Гражданского кодекса РФ вводит еще более мощный инструмент защиты — так называемое «смежное право изготовителя базы данных». Это право защищает не творческий вклад (оригинальность подбора материалов), а существенные финансовые, материальные, организационные или иные затраты, которые были вложены в создание базы данных. Изготовителю такой базы данных принадлежит исключительное право разрешать или запрещать извлечение из базы данных и последующее использование существенной части составляющих ее материалов.15
Именно статья 1334 ГК РФ представляет наибольшую угрозу для парсеров. Владелец любого крупного интернет-магазина может с легкостью доказать в суде, что он понес существенные затраты на создание своего каталога товаров. Эти затраты включают зарплаты контент-менеджеров, которые заполняли карточки товаров, оплату услуг фотографов, расходы на закупку данных у поставщиков и разработку самого сайта. Этот каталог, даже если он состоит из общеизвестных фактов (название товара, цена, вес), является базой данных, создание которой потребовало значительных инвестиций.17
Когда парсер извлекает «существенную часть» этого каталога (например, все цены на смартфоны или все товары определенного бренда), он, с точки зрения закона, обесценивает эти инвестиции, используя результат чужого труда без разрешения и без несения аналогичных затрат. Именно этот аргумент — защита инвестиций, а не креативности — стал центральным в знаковых судебных делах и сформировал правоприменительную практику в России. Следовательно, любой крупномасштабный парсинг каталога российского интернет-магазина несет в себе прямой риск нарушения смежных прав изготовителя базы данных.
2.3. Анализ прецедентной судебной практики
Теория права важна, но реальную картину формируют судебные решения. В России было несколько громких дел, которые стали прецедентными и определили ландшафт правовых рисков для парсинга.
- Дело «ВКонтакте vs. Double Data» (Дело № А40-18827/2017) 18
- Суть спора: IT-компания «Дабл» разработала продукт для банков, который оценивал кредитоспособность заемщиков на основе их профилей в социальных сетях. Для этого компания систематически парсила общедоступные данные пользователей с сайта «ВКонтакте» (имя, возраст, место учебы, друзья и т.д.).
- Позиция «ВКонтакте»: Социальная сеть заявила, что ее база данных пользователей, пусть и состоящая из общедоступной информации, является объектом смежных прав. В ее создание, поддержание и систематизацию были вложены колоссальные финансовые и организационные ресурсы. «Дабл», извлекая существенную часть этих данных, нарушает исключительное право «ВКонтакте» как изготовителя базы данных (ст. 1334 ГК РФ).
- Итог: После шести лет судебных разбирательств, прошедших через все инстанции, суды в конечном итоге встали на сторону «ВКонтакте». Это дело создало важнейший прецедент: было официально признано, что даже общедоступные данные, если они организованы в структурированную базу данных, создание которой потребовало существенных затрат, защищены от несанкционированного массового извлечения.
- Дело «HeadHunter vs. Стафори» («Робот Вера») 19
- Суть спора: Этот конфликт был более многогранным. Компания «Стафори» создала сервис «Робот Вера», который автоматизировал подбор персонала, в том числе взаимодействуя с базой резюме на сайте HeadHunter. HH обвинил «Стафори» в незаконном парсинге своей базы. Параллельно HH технически заблокировал работу «Робота Веры» на своей платформе, на что «Стафори» подала жалобу в Федеральную антимонопольную службу (ФАС).
- Двойственность исхода:
- Иск о нарушении прав на базу данных: HeadHunter проиграл этот суд. Причиной стало не то, что парсинг был признан законным, а отсутствие у HH убедительных доказательств того, что именно «Стафори» осуществляла парсинг в промышленных масштабах.19
- Жалоба в ФАС: А вот здесь ситуация развернулась в пользу «Стафори». ФАС признала, что HeadHunter, занимая доминирующее положение на рынке онлайн-рекрутинга, злоупотребил им, ограничив конкуренцию. Заблокировав сторонний сервис («Робот Вера») и одновременно предлагая клиентам свой собственный аналогичный продукт, HH создал недобросовестные преимущества для себя. ФАС выдала HeadHunter предписание «обеспечить недискриминационный доступ» к своему сервису.20
Этот второй исход создает интересную правовую коллизию. Крупный маркетплейс, такой как Ozon или Wildberries, очевидно, занимает доминирующее положение на рынке. Если такой маркетплейс блокирует сторонний сервис по мониторингу цен, одновременно предлагая продавцам свой собственный платный аналитический инструмент (что они и делают), его действия могут быть расценены ФАС как ограничение конкуренции. Возникает парадокс: с одной стороны, Гражданский кодекс защищает базу данных маркетплейса от парсинга, а с другой — Закон «О защите конкуренции» может запрещать ему блокировать доступ к этой базе для других игроков рынка. Это открывает для компаний, занимающихся парсингом, потенциальную возможность использовать антимонопольное законодательство как «щит» против блокировок, хотя это и является сложным и рискованным юридическим путем.
2.4. Другие риски: Персональные данные (ФЗ-152) и DDoS-атаки
Помимо споров о базах данных, существуют и другие, не менее серьезные риски.
- Персональные данные: Федеральный закон № 152-ФЗ «О персональных данных» — один из самых строгих в России. После поправок 2021 года даже сбор и обработка общедоступных персональных данных (например, ФИО, номер телефона или email, оставленные пользователем в публичном отзыве на товар) требуют получения отдельного согласия субъекта на их распространение.4 Очевидно, что при парсинге получить такое согласие невозможно. Поэтому сбор любой информации, которая может прямо или косвенно идентифицировать физическое лицо, является незаконным и чреват крупными штрафами.
- DDoS-атаки: Парсер по своей природе отправляет на сайт большое количество запросов за короткий промежуток времени. Если этот процесс не контролировать, он может создать чрезмерную нагрузку на сервер сайта-донора, замедлить его работу или даже привести к полной недоступности. Такие действия могут быть квалифицированы как неправомерный доступ к компьютерной информации (ст. 272 УК РФ) или как разновидность DDoS-атаки, что влечет за собой уже не административную, а уголовную ответственность.10
Таблица 2.1: Чек-лист юридической безопасности при парсинге в РФ
Для того чтобы систематизировать правовые риски и предоставить практический инструмент для самопроверки, можно использовать следующий чек-лист. Перед запуском любого проекта по парсингу цен рекомендуется честно ответить на эти вопросы.
| Вопрос для самопроверки | Риск | Рекомендация |
| Собираю ли я данные, составляющие «существенную часть» каталога конкурента? | Нарушение смежных прав изготовителя базы данных (ст. 1334 ГК РФ). | Ограничьте объем парсинга. Собирайте данные только по узкому сегменту товаров, необходимому для анализа, а не весь каталог целиком. |
| Попадают ли в собираемые данные ФИО, телефоны, email пользователей (например, из отзывов)? | Нарушение ФЗ-152 «О персональных данных». | Настройте парсер так, чтобы он целенаправленно исключал сбор полей, содержащих персональные данные. Если они все же попадают, анонимизируйте их на лету. |
| Создает ли мой парсер нагрузку, способную замедлить или «положить» сайт-донор? | Риск квалификации как DDoS-атаки (вплоть до уголовной ответственности). | Установите адекватные задержки между запросами (Crawl-delay). Используйте кэширование, чтобы не запрашивать одну и ту же страницу дважды. |
| Запрещает ли пользовательское соглашение (Terms of Service) сайта автоматический сбор данных? | Нарушение договорных обязательств. Хотя в РФ это редко доходит до суда, это дополнительный аргумент против вас в любом споре. | Внимательно изучите пользовательское соглашение сайта-донора. Если прямой запрет есть, вы действуете на свой страх и риск. |
| Копирую ли я уникальный контент (описания, статьи, фото) для публикации у себя? | Нарушение авторского права (копирайт). | Используйте парсинг для анализа (цены, наличие, характеристики), но не для прямого копирования и публикации на своем ресурсе защищенного контента без разрешения. |
Глава 3: Инструментарий парсера: от простых скриптов до мощных фреймворков
Выбор правильного инструмента — залог успеха любого проекта по парсингу. Инструментарий варьируется от простых библиотек для написания коротких скриптов до полноценных фреймворков, предназначенных для крупномасштабного сбора данных. Выбор зависит от сложности сайта-донора, объема данных и требуемой производительности.
3.1. Работа со статичными сайтами: requests + BeautifulSoup / lxml
Концепция: Этот подход является классическим и идеально подходит для «простых» сайтов, где весь необходимый контент (включая цены) загружается сразу вместе с HTML-страницей. Такие сайты называются статичными. Схема работы проста: библиотека requests получает HTML-код страницы, а библиотеки BeautifulSoup или lxml помогают его разобрать и извлечь нужные данные.23
- requests: Это де-факто стандартная библиотека в Python для отправки HTTP-запросов. Она чрезвычайно проста в использовании и позволяет получить HTML-код страницы буквально в одну строку: response = requests.get(url).23
- BeautifulSoup vs lxml: После получения HTML-кода его нужно проанализировать. Для этого используются HTML-парсеры.
- BeautifulSoup: Эта библиотека славится своей гибкостью и способностью работать даже с «битым» или некорректно сверстанным HTML-кодом, что часто встречается в реальном мире. Она имеет интуитивно понятный API и отлично подходит для новичков. BeautifulSoup позволяет находить элементы с помощью CSS-селекторов, что удобно для многих разработчиков.23
- lxml: Это высокопроизводительная библиотека, основанная на C-библиотеках libxml2 и libxslt. Она значительно быстрее, чем BeautifulSoup, но более строга к качеству HTML-разметки. lxml поддерживает не только CSS-селекторы, но и язык запросов XPath, который является более мощным и гибким инструментом для навигации по сложным HTML-документам.24
Пример кода (requests + BeautifulSoup)
Ниже представлен гипотетический пример скрипта на Python, который парсит название и цену товара с простой статичной страницы продукта.
# Гипотетический пример парсинга карточки товара
import requests
from bs4 import BeautifulSoup
import re
# URL целевой страницы
url = 'http://example-shop.ru/product/123'
# Важно всегда указывать заголовок User-Agent, чтобы имитировать запрос от реального браузера
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
try:
# Отправляем GET-запрос
response = requests.get(url, headers=headers)
response.raise_for_status() # Проверяем, что запрос прошел успешно (код 200)
# Создаем объект BeautifulSoup для парсинга HTML
soup = BeautifulSoup(response.text, 'html.parser')
# Находим название товара по его CSS-селектору (например, тег h1 с классом 'product-title')
title_element = soup.select_one('h1.product-title')
title = title_element.text.strip() if title_element else 'Название не найдено'
# Находим цену товара (например, в теге span с классом 'price-amount')
price_element = soup.select_one('span.price-amount')
price_str = price_element.text.strip() if price_element else '0'
# Очищаем цену от валютных символов и пробелов, затем преобразуем в число
# Используем регулярное выражение для извлечения только цифр
price_digits = re.findall(r'\d+', price_str)
price = float("".join(price_digits)) if price_digits else 0.0
print(f'Название: {title}')
print(f'Цена: {price} ₽')
except requests.exceptions.RequestException as e:
print(f"Ошибка при запросе к сайту: {e}")
except Exception as e:
print(f"Произошла ошибка: {e}")
Этот код демонстрирует базовый рабочий процесс: отправка запроса, парсинг ответа и извлечение данных с помощью CSS-селекторов.23
3.2. Вызов современности: парсинг сайтов с JavaScript
Проблема: Большинство современных e-commerce платформ, включая крупнейшие российские маркетплейсы, такие как Ozon, Wildberries и DNS-shop, являются динамическими. Это означает, что значительная часть контента, включая цены, наличие товара и отзывы, не содержится в исходном HTML-коде, который отдает сервер. Вместо этого, браузер сначала загружает «каркас» страницы, а затем выполняет JavaScript-код, который в фоновом режиме отправляет дополнительные запросы (XHR/Fetch) на сервер за данными и «вставляет» их в нужные места на странице.29 Если использовать для такого сайта простой
requests, то в ответ придет практически «пустая» страница без интересующей нас информации.
Решение: Для парсинга динамических сайтов необходим инструмент, который умеет эмулировать работу полноценного браузера: загрузить страницу, дождаться выполнения всех JavaScript-скриптов и только после этого отдать для анализа финальный, полностью отрисованный HTML-код.
Сравнение инструментов для автоматизации браузера:
- Selenium: Это «ветеран» и долгое время бывший стандартом в области автоматизации браузеров. Он поддерживает множество языков программирования (Python, Java, C# и др.) и все основные браузеры. Его главный недостаток — он считается относительно медленным и имеет более громоздкий API, требующий от разработчика вручную прописывать явные ожидания загрузки элементов (WebDriverWait), что усложняет код и делает его менее стабильным.31
- Playwright: Это современный фреймворк от Microsoft, разработанный командой, которая ранее создала Puppeteer в Google. Playwright быстро набрал популярность благодаря своей скорости, надежности и мощному API. Он поддерживает все современные браузеры (Chromium, Firefox, WebKit/Safari) и имеет официальные библиотеки для нескольких языков, включая Python. Его ключевое преимущество — механизм «auto-waiting». Playwright автоматически ждет, пока элемент станет видимым и доступным для взаимодействия, прежде чем выполнить команду. Это кардинально упрощает написание кода и делает парсеры гораздо более стабильными и устойчивыми к изменениям на сайте.31
- requests-html: Эта библиотека является надстройкой над requests и пытается объединить простоту requests с возможностью рендеринга JavaScript. Она «под капотом» использует headless-версию браузера Chromium. Для выполнения JS достаточно вызвать одну команду response.html.render(). Это делает requests-html очень удобным для простых задач на динамических сайтах, но для сложных сценариев, требующих взаимодействия со страницей (клики, прокрутка, заполнение форм), он менее гибок и мощен, чем Playwright.34
Для новых проектов, требующих работы с JavaScript, Playwright является предпочтительным выбором. Его архитектура изначально спроектирована для решения проблем, с которыми сталкивались пользователи Selenium, в первую очередь — нестабильности скриптов из-за асинхронной природы загрузки контента. Автоматические ожидания в Playwright избавляют разработчика от необходимости писать сложный код для синхронизации, что значительно ускоряет разработку и повышает надежность готового решения.37
3.3. Масштабирование с помощью фреймворков: введение в Scrapy
Когда задача выходит за рамки простого скрипта для одного сайта и превращается в крупномасштабный проект по сбору данных с десятков тысяч страниц, необходим более системный подход. Здесь на сцену выходят фреймворки, и самый известный из них в мире Python — это Scrapy.
Концепция: Scrapy — это не просто библиотека, а полноценный асинхронный фреймворк для создания веб-краулеров (пауков). Он предоставляет готовую архитектуру и множество встроенных компонентов для решения типичных задач парсинга: управление очередью URL-адресов, асинхронная отправка запросов, обработка данных, экспорт в различные форматы и многое другое.39
Ключевые преимущества Scrapy:
- Асинхронность «из коробки»: Scrapy построен на асинхронной библиотеке Twisted, что позволяет ему отправлять сотни и даже тысячи HTTP-запросов параллельно, не дожидаясь ответа на предыдущий. Это обеспечивает колоссальный прирост в скорости по сравнению с последовательными запросами в requests.40
- Модульная архитектура: Фреймворк навязывает четкое разделение логики. Spiders (Пауки) отвечают за логику обхода сайта и извлечение данных. Items описывают структуру данных, которые нужно собрать. Item Pipelines (Конвейеры) отвечают за постобработку собранных данных: очистку, валидацию, сохранение в базу данных или файл.39
- Расширяемость: Scrapy имеет мощную систему middleware (промежуточных обработчиков), которые позволяют встраивать дополнительную логику в процесс обработки запросов и ответов. Существует огромное количество готовых расширений для ротации прокси, управления User-Agent, обработки cookies, интеграции с Selenium/Playwright для рендеринга JavaScript и т.д.
Когда использовать Scrapy? Scrapy — это выбор для серьезных, долгосрочных проектов по сбору данных. Если вам нужно регулярно обходить большие сайты, управлять сложной логикой (например, обходить пагинацию, затем заходить в каждую карточку товара), обрабатывать большие объемы данных и делать это максимально быстро, то Scrapy будет лучшим решением.39
Таблица 3.1: Сравнительный анализ библиотек и фреймворков для парсинга
Чтобы помочь с выбором подходящего инструмента, ниже приведена сравнительная таблица, обобщающая ключевые характеристики рассмотренных технологий.
| Инструмент | Тип | Поддержка JS | Скорость | Порог входа | Масштабируемость | Идеально для… |
| requests + BeautifulSoup/lxml | Библиотеки | Нет | Очень высокая | Низкий | Низкая | Быстрых скриптов для простых, статичных сайтов и API. 23 |
| requests-html | Библиотека | Да (встроенный Chromium) | Средняя | Низкий | Низкая | Простых задач на динамических сайтах, где не нужна сложная логика взаимодействия. 34 |
| Selenium | Автоматизация браузера | Да | Низкая | Средний | Средняя | Тестирования и парсинга сложных сайтов, где требуется поддержка специфичных или устаревших браузеров. 32 |
| Playwright | Автоматизация браузера | Да | Высокая | Средний | Средняя | Парсинга большинства современных динамических сайтов; новый стандарт для этой задачи. 32 |
| Scrapy | Фреймворк | Нет (но интегрируется с Playwright/Selenium) | Очень высокая (асинхронный) | Высокий | Высокая | Крупномасштабного, регулярного парсинга множества страниц и доменов. 39 |
Глава 4: Искусство обхода блокировок: продвинутые техники
Как только ваш парсер начинает делать больше нескольких десятков запросов к одному сайту, он неизбежно сталкивается с системами защиты от ботов. Современные интернет-магазины активно защищают свои данные, и наивный скрипт будет заблокирован практически мгновенно. Успешный парсинг — это игра в «кошки-мышки», где ваша задача — сделать запросы парсера максимально неотличимыми от запросов обычного пользователя с браузером.
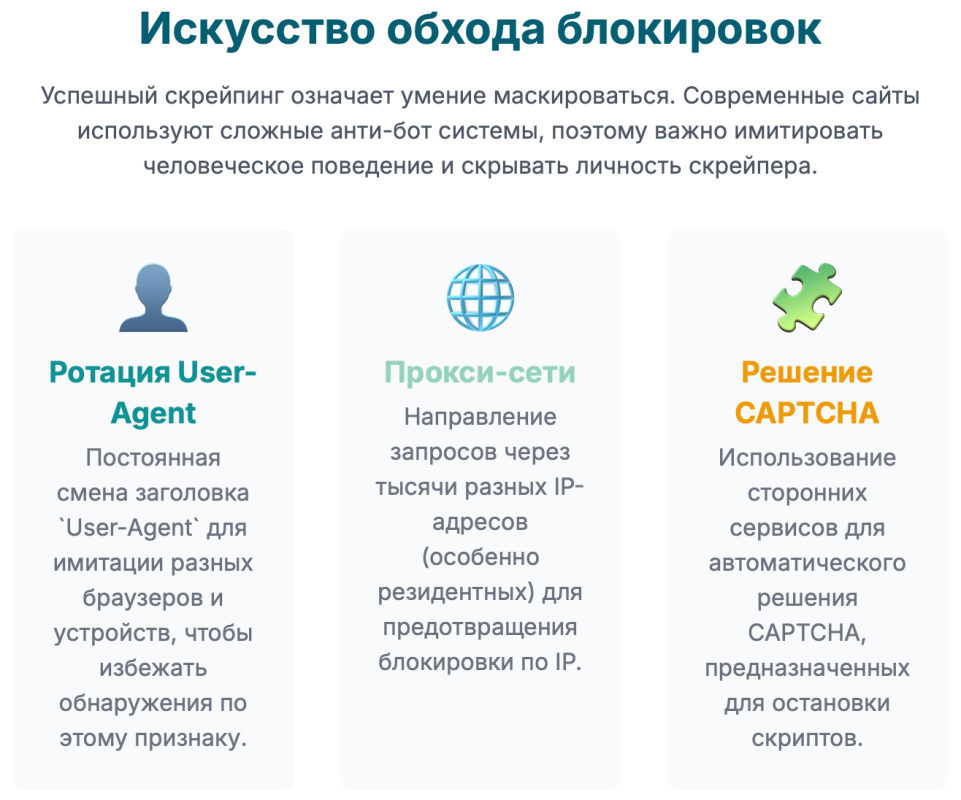
4.1. Маскировка под пользователя: ротация User-Agent и заголовков
Проблема: Каждый раз, когда ваш браузер запрашивает страницу, он отправляет на сервер HTTP-заголовки. Один из важнейших заголовков — User-Agent. Он содержит информацию о вашем браузере, операционной системе и их версиях (например, Mozilla/5.0 (Windows NT 10.0; Win64; x64)…). Скрипты на Python, использующие библиотеку requests по умолчанию, либо не отправляют этот заголовок вовсе, либо отправляют значение вроде python-requests/2.28.1. Для любой системы защиты это явный признак бота, и такой запрос немедленно блокируется.44
- Всегда устанавливайте User-Agent. Ваш парсер должен при каждом запросе представляться реальным браузером.
- Ротируйте User-Agent. Отправлять тысячи запросов с одним и тем же User-Agent — тоже подозрительно. Лучшей практикой является создание списка из нескольких десятков актуальных User-Agent’ов для разных браузеров и операционных систем и выбор случайного из этого списка для каждого нового запроса или сессии.44
Дополнительные заголовки: Помимо User-Agent, современные браузеры отправляют и другие заголовки, которые анализируются системами защиты. Чтобы маскировка была более полной, стоит имитировать и их:
- Accept: Типы контента, которые браузер готов принять.
- Accept-Language: Предпочитаемый язык (например, ru-RU,ru;q=0.9).
- Referer: URL страницы, с которой был совершен переход на текущую. Этот заголовок особенно важен для имитации навигации по сайту.
4.2. Прокси-серверы: ваш ключ к анонимности и масштабу
Проблема: Самый простой и эффективный способ для сайта заблокировать парсер — это заблокировать его IP-адрес. Если с одного IP-адреса поступает аномально большое количество запросов за короткое время, система защиты вносит его в черный список, и все последующие запросы с этого адреса будут отклонены.45
Решение: Использование прокси-серверов. Прокси-сервер — это промежуточный сервер между вашим парсером и целевым сайтом. Ваш запрос сначала идет на прокси, а уже прокси, от своего имени (и со своим IP-адресом), отправляет запрос на сайт. Таким образом, для целевого сайта каждый запрос приходит с нового IP-адреса, что делает невозможным блокировку по этому признаку.47
Типы прокси-серверов:
- Дата-центровые (Datacenter Proxies): Это IP-адреса, принадлежащие хостинг-провайдерам и дата-центрам. Они самые дешевые и быстрые, но их IP-диапазоны хорошо известны. Крупные сайты, такие как Ozon или Amazon, легко их определяют и часто блокируют превентивно.
- Резидентные (Residential Proxies): Это IP-адреса, выданные интернет-провайдерами обычным домашним пользователям. Запросы через такие прокси выглядят для сайта как трафик от реальных посетителей, поэтому они имеют очень высокий уровень доверия и крайне редко блокируются. Это лучший выбор для парсинга хорошо защищенных сайтов, но они значительно дороже.
- Мобильные (Mobile Proxies): Это IP-адреса, принадлежащие операторам мобильной связи. Они самые дорогие и самые надежные. Поскольку за одним мобильным IP-адресом могут одновременно находиться тысячи реальных пользователей, сайты крайне неохотно блокируют такие адреса, опасаясь затронуть легитимных посетителей.
Ключевой аспект успешного использования прокси — это их ротация. Необходимо иметь пул из десятков, сотен или даже тысяч прокси-адресов и постоянно их менять. Хорошие прокси-провайдеры предлагают так называемые «вращающиеся прокси» (rotating proxies), которые автоматически подставляют новый IP-адрес для каждого вашего запроса.45
4.3. Борьба с CAPTCHA
Проблема: CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) — это тест, предназначенный для того, чтобы отличить человека от бота. Современные системы, особенно reCAPTCHA от Google, являются серьезным препятствием для парсеров.
- Сервисы по распознаванию CAPTCHA: Наиболее распространенный подход — использование API специализированных сервисов (например, Anti-captcha, RuCaptcha, 2Captcha). Ваш скрипт, столкнувшись с капчей, отправляет ее параметры (например, картинку или специальный токен сайта) на такой сервис. Там задачу решает либо живой человек, либо обученная нейросеть. После решения сервис возвращает вашему скрипту ответ, который он вставляет в форму на сайте и продолжает работу.50
- Имитация человеческого поведения: Часто капча появляется не сразу, а как реакция на подозрительное, «роботизированное» поведение: мгновенные переходы по ссылкам, отсутствие движений мыши, линейная прокрутка страницы. При использовании инструментов автоматизации браузера, таких как Playwright, можно имитировать человеческое поведение (плавные и слегка случайные движения курсора, естественная скорость набора текста, нелинейная прокрутка), что может помочь избежать появления капчи.
- Использование качественных прокси: Как уже упоминалось, резидентные и мобильные прокси с хорошей «репутацией» IP-адреса значительно реже сталкиваются с проверками CAPTCHA, чем IP-адреса дата-центров.
Проблема: Многие сайты используют cookies для отслеживания сессии пользователя. Например, после входа в систему сервер отправляет браузеру cookie с идентификатором сессии. Браузер затем прикрепляет этот cookie ко всем последующим запросам, позволяя серверу «узнавать» пользователя. Если парсер не умеет работать с cookies, он не сможет парсить страницы, требующие авторизации, или будет постоянно «терять» сессию.
- При использовании библиотеки requests необходимо использовать объект requests.Session. Этот объект автоматически управляет cookies: он сохраняет все cookies, полученные от сервера, и автоматически прикрепляет их ко всем последующим запросам в рамках этой сессии. Это полностью имитирует поведение браузера.51
- При работе с инструментами автоматизации браузера, такими как Playwright, управление cookies происходит автоматически в рамках одного «контекста браузера». Контекст хранит все cookies, localStorage и другие данные сессии, изолируя их от других контекстов.37
4.5. Этичный парсинг: уважение к ресурсу
Помимо технических методов обхода блокировок, существуют общепринятые «правила хорошего тона», соблюдение которых не только этично, но и прагматично, так как снижает риск привлечь к себе излишнее внимание администраторов сайта.
- Изучите robots.txt: Перед началом парсинга любого сайта стоит заглянуть в файл http://<имя_сайта>/robots.txt. Этот файл содержит директивы для поисковых роботов, указывающие, какие разделы сайта его владелец просит не индексировать (Disallow). Хотя с юридической точки зрения парсер не обязан следовать этим правилам, их игнорирование является явным сигналом о ваших намерениях и может спровоцировать блокировку.53
- Соблюдайте Crawl-delay: Иногда в robots.txt можно найти директиву Crawl-delay: N, которая просит роботов делать паузу в N секунд между запросами. Соблюдение этого интервала — лучший способ показать, что вы не пытаетесь создать чрезмерную нагрузку на сервер.44 Если такой директивы нет, хорошей практикой является установка случайной задержки от 2 до 10 секунд между запросами.
- Используйте кэширование: Не запрашивайте одну и ту же страницу многократно в процессе разработки и отладки. После первого успешного запроса сохраните (кэшируйте) полученный HTML-код локально. Все последующие запуски скрипта для отладки логики извлечения данных можно производить уже с локальной копией, не нагружая сервер сайта-донора.55
Глава 5: Самый эффективный путь: реверс-инжиниринг внутренних API
Парсинг HTML-страниц, особенно с рендерингом JavaScript, — это мощный, но зачастую избыточный и хрупкий метод. Существует более элегантный, быстрый и надежный способ получения данных, который используют сами сайты для динамической загрузки контента — их внутренние (или «скрытые») API.
5.1. Почему API-запросы эффективнее парсинга HTML
Когда вы открываете страницу товара на современном маркетплейсе, ваш браузер не получает сразу весь готовый HTML. Он загружает лишь «скелет» страницы, а затем JavaScript-код отправляет фоновые запросы к внутренним API сайта, чтобы получить актуальные данные о цене, наличии, отзывах и т.д., и уже потом вставляет их в HTML.56 Если мы сможем «подсмотреть» эти запросы и научимся их повторять, мы получим огромные преимущества:
- Скорость и эффективность: Вместо того чтобы загружать и рендерить «тяжелую» HTML-страницу размером в несколько мегабайт со всеми стилями, скриптами и изображениями, мы делаем один легкий API-запрос и получаем в ответ несколько килобайт чистого текста с данными. Это в десятки, а то и в сотни раз быстрее и требует значительно меньше сетевого трафика и вычислительных ресурсов.57
- Структурированные данные: Ответ от API почти всегда приходит в удобном для машинной обработки формате, как правило, JSON (JavaScript Object Notation). Эти данные уже идеально структурированы. Вам не нужно писать сложные правила с CSS-селекторами или XPath, чтобы «выковырять» цену из лабиринта HTML-тегов. Вы просто обращаетесь к нужному полю в JSON-объекте, например, data[‘price’].58
- Надежность и стабильность: Внешний вид сайта (HTML-разметка и CSS-классы) меняется очень часто в результате редизайна, A/B-тестирования или просто обновлений. Любое такое изменение может «сломать» ваш парсер, основанный на анализе HTML. Внутренние API, на которых держится логика сайта, меняются гораздо реже и более предсказуемо. Парсер, работающий через API, будет на порядок более стабильным в долгосрочной перспективе.
5.2. Пошаговое руководство: как найти «скрытые» API
Процесс поиска внутренних API называется реверс-инжинирингом и доступен любому, у кого есть современный браузер. Для этого используются «Инструменты разработчика».
- Шаг 1: Открыть Инструменты разработчика. На интересующей вас странице интернет-магазина нажмите клавишу F12 или комбинацию Ctrl+Shift+I (Cmd+Option+I на Mac). В правой или нижней части экрана откроется панель инструментов.59
- Шаг 2: Перейти на вкладку «Network» (Сеть). Эта вкладка является своего рода «черным ящиком» вашего браузера. Она записывает абсолютно все сетевые запросы, которые страница отправляет на серверы: загрузку HTML, CSS, изображений, скриптов и, что самое важное для нас, данных.59
- Шаг 3: Отфильтровать запросы по типу «Fetch/XHR». Чтобы не утонуть в потоке запросов, нужно отфильтровать лишние. Нажмите на кнопку фильтра Fetch/XHR. Это оставит в списке только асинхронные запросы за данными, которые JavaScript делает в фоновом режиме.59
- Шаг 4: Выполнить действие на сайте и наблюдать. Теперь, когда «ловушка» настроена, совершите на странице действие, которое должно привести к загрузке новых данных. Это может быть:
- Переход на следующую страницу каталога (пагинация).
- Применение фильтра (по бренду, цене).
- Прокрутка страницы вниз (если сайт использует «бесконечную» прокрутку).
- Выбор другого цвета или размера товара.
В момент совершения действия в списке на вкладке Network появится один или несколько новых запросов. - Шаг 5: Изучить запрос и ответ. Внимательно посмотрите на имена появившихся запросов. Часто они бывают «говорящими», например, search?query=…, get_products?category=… или api/v2/catalog. Кликните на самый подозрительный запрос, чтобы изучить его детали:
- Вкладка Headers (Заголовки): Здесь вы найдете полный URL-адрес запроса (Request URL), метод (Request Method: GET или POST) и все заголовки, которые отправил браузер.
- Вкладка Payload (для POST) или Params (в URL для GET): Здесь показаны параметры, которые были отправлены на сервер. Например, page: 2 или sort: price_asc.
- Вкладка Response (Ответ) или Preview (Предпросмотр): Это самое интересное. Здесь вы увидите данные, которые сервер прислал в ответ. Если вы видите там структурированный JSON-объект со списком товаров, их ценами, названиями и характеристиками — поздравляем, вы нашли искомый API-эндпоинт!.60
5.3. Пример запроса и обработки JSON-ответа на Python
После того как вы нашли API-запрос в Инструментах разработчика, ваша задача — воспроизвести его в своем Python-скрипте.
- Скопируйте необходимые данные:
- Из вкладки Headers скопируйте Request URL.
- Также из Headers скопируйте значения ключевых заголовков, как минимум User-Agent, а иногда и Authorization или x-api-key, если они есть.
- Из вкладки Payload/Params посмотрите, какие параметры передаются.
Пример кода:
import requests
import json
# URL API-эндпоинта, найденный в Инструментах разработчика
api_url = 'https://api.example-shop.ru/v2/catalog/search'
# Параметры запроса (для GET-запросов)
params = {
'query': 'смартфон',
'page': 1,
'sort': 'popularity'
}
# Заголовки, скопированные из браузера.
# Иногда для доступа к API требуется специальный токен авторизации.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Accept': 'application/json, text/plain, */*',
'Authorization': 'Bearer some_public_token_if_needed'
}
try:
# Отправляем GET-запрос к API
response = requests.get(api_url, params=params, headers=headers)
response.raise_for_status() # Проверяем на ошибки (статус-коды 4xx или 5xx)
# Преобразуем JSON-ответ в словарь Python
data = response.json()
# Проходим по списку товаров в полученных данных
# Структура JSON (ключи 'data', 'items') будет уникальной для каждого сайта
if 'data' in data and 'items' in data['data']:
for product in data['data']['items']:
# Извлекаем нужные поля
name = product.get('name', 'N/A')
price = product.get('price', {}).get('current', 0)
product_id = product.get('id', 'N/A')
print(f"ID: {product_id}, Название: {name}, Цена: {price}")
else:
print("Не удалось найти список товаров в ответе API.")
except requests.exceptions.RequestException as e:
print(f"Ошибка сетевого запроса: {e}")
except json.JSONDecodeError:
print("Ошибка декодирования JSON. Ответ сервера не является валидным JSON.")
print("Текст ответа:", response.text)
Этот подход, основанный на реверс-инжиниринге API, является наиболее профессиональным, эффективным и надежным методом для сбора данных с современных веб-платформ.59
Глава 6: Реальный кейс: создаем парсер цен для Wildberries
Чтобы продемонстрировать применение описанных техник на практике, рассмотрим задачу создания парсера для одного из крупнейших маркетплейсов России — Wildberries. Этот кейс наглядно покажет, почему реверс-инжиниринг API является предпочтительным методом.
6.1. Анализ целевого сайта: официальные и неофициальные API
Wildberries, как и Ozon, представляет собой сложную технологическую платформу. Попытка парсить его HTML-страницы «в лоб» с помощью инструментов автоматизации браузера (Selenium или Playwright) будет медленной, ресурсозатратной и крайне нестабильной из-за постоянных изменений в верстке и активных систем защиты от ботов.63
При анализе Wildberries важно различать два типа API:
- Официальное API для продавцов. Wildberries предоставляет обширное и хорошо документированное API для своих партнеров (продавцов) на портале dev.wildberries.ru. Это API позволяет автоматизировать управление товарами, ценами, остатками, заказами и получать аналитические отчеты.64 Для работы с ним требуется специальный авторизационный токен, который генерируется в личном кабинете продавца. Это API не предназначено для публичного парсинга цен конкурентов, а служит для интеграции с учетными системами продавца.
- Недокументированные (внутренние) API. Это API, которые использует фронтенд самого сайта wildberries.ru для отображения каталога товаров, цен, отзывов и другой информации для покупателей. Эти API не описаны в публичной документации, но именно они являются нашей целью, так как позволяют получать общедоступные данные наиболее эффективным способом.
6.2. Поиск и анализ API каталога Wildberries
Применим методику из Главы 5.
- Открываем в браузере любую категорию товаров на wildberries.ru.
- Нажимаем F12, чтобы открыть Инструменты разработчика, и переходим на вкладку Network, отфильтровав запросы по типу Fetch/XHR.
- Переходим на вторую страницу каталога или применяем любой фильтр.
- В списке запросов мы немедленно обнаруживаем GET-запрос, уходящий на домен search.wb.ru. Полный URL выглядит примерно так: https://search.wb.ru/exactmatch/ru/common/v4/search?query=смартфон&resultset=catalog&page=1
Проанализируем этот запрос:
- Эндпоинт: https://search.wb.ru/exactmatch/ru/common/v4/search
- Параметры:
- query: Поисковый запрос пользователя (или категория).
- resultset: Тип выдачи, в данном случае catalog.
- page: Номер страницы.
- Ответ: Перейдя на вкладку Response или Preview, мы видим идеально структурированный JSON. Внутри него есть ключ data, который содержит объект с ключом products. Этот ключ указывает на массив, где каждый элемент — это объект с полной информацией о товаре 67:
- id: Артикул товара (nmId).
- name: Полное наименование.
- brand: Название бренда.
- salePriceU: Цена со скидкой, умноженная на 100 (т.е. в копейках).
- priceU: Цена без скидки (в копейках).
- rating: Рейтинг товара.
- feedbacks: Количество отзывов.
Мы нашли именно то, что нужно: быстрый и структурированный способ получать данные о товарах из каталога.
6.3. Пошаговый скрипт на Python для сбора данных
Теперь напишем Python-скрипт, который будет использовать найденный API для сбора данных по заданному поисковому запросу и сохранять их в CSV-файл для дальнейшего анализа.
Задача: Написать функцию, которая принимает поисковый запрос, парсит первую страницу выдачи Wildberries и возвращает данные в виде таблицы (Pandas DataFrame).
import requests
import pandas as pd
import json
from typing import Optional
def parse_wildberries_search(query: str) -> Optional:
"""
Парсит первую страницу поисковой выдачи Wildberries по заданному запросу,
используя внутренний API каталога.
Args:
query: Поисковый запрос (например, "смартфон xiaomi").
Returns:
Pandas DataFrame с данными о товарах или None в случае ошибки.
"""
products_data =
# Формируем URL для запроса к API поиска
# Важно использовать правильный эндпоинт, который может меняться со временем
api_url = f"https://search.wb.ru/exactmatch/ru/common/v4/search"
params = {
'query': query,
'resultset': 'catalog',
'sort': 'popular', # Можно менять на 'rate' или 'priceup'/'pricedown'
'page': 1,
'appType': 1, # Эмулируем запрос от десктопного сайта
'curr': 'rub'
}
# Заголовки, имитирующие запрос от браузера
headers = {
'Accept': '*/*',
'Accept-Language': 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7',
'Connection': 'keep-alive',
'Origin': 'https://www.wildberries.ru',
'Referer': 'https://www.wildberries.ru/catalog/0/search.aspx',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
}
try:
response = requests.get(api_url, params=params, headers=headers)
response.raise_for_status() # Вызовет исключение для статусов 4xx/5xx
data = response.json()
products_raw = data.get('data', {}).get('products')
if not products_raw:
print(f"Товары по запросу '{query}' не найдены.")
return None
for product in products_raw:
products_data.append({
'id': product.get('id'),
'name': product.get('name'),
'brand': product.get('brand'),
'price_rub': product.get('salePriceU', 0) / 100,
'base_price_rub': product.get('priceU', 0) / 100,
'rating': product.get('rating'),
'reviews_count': product.get('feedbacks'),
'url': f"https://www.wildberries.ru/catalog/{product.get('id')}/detail.aspx"
})
except requests.exceptions.RequestException as e:
print(f"Ошибка сетевого запроса: {e}")
return None
except json.JSONDecodeError:
print("Ошибка декодирования JSON. Возможно, структура ответа изменилась или пришла ошибка.")
print("Текст ответа:", response.text)
return None
# Создаем DataFrame из списка словарей
return pd.DataFrame(products_data)
if __name__ == '__main__':
search_query = "смартфон xiaomi"
print(f"Начинаем парсинг по запросу: '{search_query}'")
df_products = parse_wildberries_search(search_query)
if df_products is not None and not df_products.empty:
output_filename = f'wildberries_{search_query.replace(" ", "_")}.csv'
# Сохраняем в CSV с кодировкой utf-8 для корректного отображения кириллицы
df_products.to_csv(output_filename, index=False, encoding='utf-8-sig')
print(f"Данные успешно собраны. Найдено {len(df_products)} товаров.")
print(f"Результаты сохранены в файл: {output_filename}")
else:
print("Парсинг завершился безрезультатно.")
Этот скрипт полностью готов к работе. Он отправляет запрос к API, обрабатывает JSON-ответ, извлекает ключевые поля и сохраняет результат в удобный для анализа CSV-файл.67
6.4. Масштабирование и ограничения
Представленный скрипт решает базовую задачу, но для промышленного использования его необходимо доработать:
- Пагинация: Для сбора данных со всех страниц выдачи необходимо организовать цикл, который будет итерироваться по параметру page в запросе, пока API не вернет пустой список товаров.
- Обход блокировок: Несмотря на то, что парсинг через API создает меньшую нагрузку, Wildberries все равно отслеживает и блокирует IP-адреса, с которых идет аномальная активность. Для регулярного и масштабного сбора данных необходимо интегрировать ротацию прокси-серверов, как было описано в Главе 4.69 Лучшим выбором будут качественные резидентные или мобильные прокси.
- Обработка ошибок и изменений API: Внутренние API могут меняться без предупреждения. Скрипт должен быть устойчив к ошибкам: корректно обрабатывать изменения в структуре JSON, отслеживать HTTP-коды ошибок и иметь систему логирования для быстрой диагностики проблем.
Этот практический кейс показывает, что, потратив немного времени на анализ сетевой активности сайта, можно создать на порядок более эффективное и надежное решение для сбора данных, чем при попытке парсить сложный динамический фронтенд.
Глава 7: Стратегический выбор: собственная разработка или готовый сервис (Build vs. Buy)
После того как бизнес осознал необходимость в данных о ценах конкурентов и разобрался в технологиях, возникает главный стратегический вопрос: стоит ли создавать собственную систему парсинга с нуля («Build») или же проще и дешевле покупать готовые данные у специализированных сервисов («Buy»)? Это не просто технический, а в первую очередь экономический и управленческий выбор, который может серьезно повлиять на ресурсы и фокус компании.
7.1. Создание собственного решения («Build»)
Этот путь предполагает, что компания самостоятельно нанимает или выделяет команду разработчиков для создания, развертывания и поддержки всей инфраструктуры для парсинга.
- Полный контроль и кастомизация: Вы можете создать решение, которое идеально соответствует вашим уникальным бизнес-процессам. Данные будут собираться именно в том формате, в котором они нужны вашим аналитическим системам, и с той частотой, которая вам необходима. Вы полностью контролируете логику и можете адаптировать ее под любые изменения.70
- Безопасность данных: Все собранные данные и сама инфраструктура находятся внутри вашего контура. Это может быть критически важным, если вы работаете с чувствительной коммерческой информацией или просто не хотите, чтобы кто-то знал, каких конкурентов вы мониторите.70
Скрытые издержки и недостатки:
Принятие решения о собственной разработке часто основывается на неполной оценке затрат. Руководство видит только зарплату одного-двух программистов, но упускает из виду множество «скрытых» расходов, которые в итоге делают проект значительно дороже, чем казалось на старте.73
- Высокие начальные и постоянные затраты на персонал: Вам потребуются не просто Python-разработчики, а специалисты с опытом именно в веб-скрейпинге, которые умеют работать с прокси, обходить защиту и строить отказоустойчивые системы. Такие специалисты стоят дорого, и их сложно найти.70
- Затраты на инфраструктуру:
- Серверы: Парсеры должны работать 24/7, что требует аренды или покупки серверов.
- Прокси-серверы: Это самая значительная и постоянная статья расходов. Качественные резидентные или мобильные прокси, необходимые для обхода блокировок крупных маркетплейсов, могут стоить от нескольких сотен до нескольких тысяч долларов в месяц в зависимости от объема трафика.71
- Постоянная поддержка и «гонка вооружений»: Веб-сайты постоянно меняют свою структуру, HTML-разметку и усиливают анти-бот защиту. Это означает, что ваши парсеры будут регулярно «ломаться». По оценкам, команда разработчиков будет тратить от 20% до 30% своего времени не на создание новых функций, а на поддержку и починку существующих скриптов. Это непрерывная «гонка вооружений» с целевыми сайтами.73
- Длительное время выхода на рынок (Time-to-market): Разработка и отладка надежной, масштабируемой системы парсинга с нуля — это не недельный проект. В среднем, это занимает от 3 до 6 месяцев. Все это время ваш бизнес не получает нужные данные и упускает рыночные возможности.73
7.2. Использование Data-as-a-Service (DaaS) провайдеров («Buy»)
Этот путь предполагает, что вы полностью аутсорсите задачу сбора данных. Вы не пишете парсеры и не управляете инфраструктурой, а просто покупаете готовые, очищенные и структурированные данные у специализированной компании. Данные обычно предоставляются через API или в виде регулярных выгрузок в нужном формате (CSV, JSON, XML).76
- Скорость получения результата: Вы начинаете получать ценные данные практически мгновенно, часто в день заключения договора. Вам не нужно ждать месяцы, пока будет разработано собственное решение.71
- Надежность и масштабируемость: DaaS-провайдеры — это их основной бизнес. Они уже решили все сложные технические проблемы: у них есть огромные пулы прокси, системы для решения CAPTCHA, команды инженеров, которые 24/7 следят за работоспособностью парсеров и адаптируют их к изменениям на сайтах. Их инфраструктура рассчитана на обработку миллиардов страниц.76
- Предсказуемые и часто более низкие затраты: Вы платите фиксированную ежемесячную плату или платите за объем полученных данных. Это превращает непредсказуемые капитальные затраты (CAPEX) на разработку в понятные и прогнозируемые операционные расходы (OPEX). В большинстве случаев это оказывается значительно дешевле, чем содержать собственную команду и инфраструктуру.73
- Фокус на основном бизнесе: Ваши разработчики и аналитики могут сосредоточиться на своей основной задаче — использовании данных для улучшения вашего продукта и увеличения продаж, а не на решении бесконечных технических проблем с парсингом.76
Недостатки:
- Меньшая гибкость: Вы можете быть ограничены теми сайтами, форматами данных и частотой обновлений, которые предлагает сервис. Хотя многие провайдеры предлагают кастомные решения, это может стоить дороже.
- Зависимость от вендора: Вы становитесь зависимы от одного поставщика данных. Проблемы на его стороне могут повлиять на ваш бизнес.
7.3. Обзор сервиса на примере xmldatafeed.com
Сервис xmldatafeed.com является примером DaaS-провайдера, ориентированного на рынок e-commerce. Он специализируется на мониторинге цен конкурентов и предоставлении этих данных ритейлерам.78 Ключевая особенность, отраженная в названии, — это предоставление данных в формате XML-фидов. Этот формат является стандартом для многих систем управления товарами (PIM) и платформ электронной коммерции, что упрощает интеграцию полученных данных в существующие бизнес-процессы.79
Использование такого сервиса полностью абстрагирует клиента от технических сложностей парсинга. Клиент просто указывает, данные с каких сайтов и по каким товарам ему нужны, а сервис берет на себя всю работу по их извлечению, очистке, структурированию и доставке в виде готового фида.78 Это классическая модель «Buy», позволяющая бизнесу получить результат, не погружаясь в процесс.
Таблица 7.1: Анализ совокупной стоимости владения (TCO) за 3 года: Build vs. Buy
Чтобы наглядно сравнить два подхода, полезно рассчитать их совокупную стоимость владения (Total Cost of Ownership) в перспективе нескольких лет. Приведенные ниже цифры являются оценочными и служат для демонстрации порядка величин, а не точным расчетом.
| Компонент затрат | Собственная разработка (Build) | Покупка данных (Buy) |
| Год 1 | ||
| Начальная разработка (2 инженера, 4 мес.) | ~$40,000 | $0 |
| Инфраструктура (серверы + прокси) / мес. | ~$3,000 | — |
| Поддержка и доработка (0.5 инженера) / мес. | ~$2,500 | — |
| Стоимость подписки на сервис / мес. | — | ~$1,500 |
| Итого за Год 1 | ~$106,000 | ~$18,000 |
| Год 2 | ||
| Инфраструктура + Поддержка | ~$66,000 | ~$18,000 |
| Год 3 | ||
| Инфраструктура + Поддержка | ~$66,000 | ~$18,000 |
| Итого за 3 года | ~$238,000 | ~$54,000 |
| Чистая экономия при покупке | ~$184,000 |
Примечание: Расчеты основаны на усредненных данных и могут варьироваться в зависимости от сложности проекта и региона. Источник для моделирования:.73
Как видно из таблицы, несмотря на кажущуюся экономию на старте, в долгосрочной перспективе собственная разработка оказывается в разы дороже из-за постоянных расходов на поддержку и инфраструктуру.
Заключение: Ключевые выводы и рекомендации
Парсинг цен в российском e-commerce — это мощный, но сложный инструмент, требующий сбалансированного подхода, сочетающего техническую грамотность, юридическую осторожность и стратегическое видение. На основе проведенного анализа можно сформулировать несколько ключевых выводов и рекомендаций.
- Стратегический императив: В современной конкурентной среде автоматизированный сбор данных о ценах и ассортименте перестал быть опцией и стал необходимостью для выживания и роста. Компании, которые не используют эти данные, добровольно отдают преимущество своим конкурентам.
- Правовая осторожность: Российское законодательство, в частности статья 1334 ГК РФ о защите прав изготовителя базы данных, создает реальные и существенные юридические риски. Прецедентное дело «ВКонтакте vs. Double Data» показало, что суды готовы защищать инвестиции владельцев сайтов в создание контента. Крупномасштабный парсинг без предварительной юридической оценки — это игра с огнем. Необходимо минимизировать объемы извлекаемых данных, избегать сбора персональной информации и не создавать чрезмерную нагрузку на серверы.
- Технологический выбор: Эпоха простых статичных сайтов уходит в прошлое. Для эффективной работы с современными интернет-магазинами необходимо использовать инструменты, способные обрабатывать JavaScript. Playwright сегодня является золотым стандартом для этой задачи. Однако наиболее эффективной и стабильной стратегией является реверс-инжиниринг внутренних API сайтов, что позволяет получать чистые, структурированные данные с минимальными затратами ресурсов.
- Невидимость — ключ к успеху: Успех любого серьезного проекта по парсингу на 90% зависит от способности оставаться незамеченным для систем защиты. Комплексная стратегия, включающая ротацию качественных резидентных или мобильных прокси, смену User-Agent и других HTTP-заголовков, управление cookies и сессиями, а также соблюдение адекватных задержек между запросами, является обязательным условием.
- Build vs. Buy: Решение о создании собственной системы парсинга или покупке готовых данных должно приниматься на основе трезвого экономического расчета, а не только технических амбиций. Анализ совокупной стоимости владения показывает, что для подавляющего большинства компаний, чей основной бизнес не связан с извлечением данных, покупка данных у DaaS-провайдера будет значительно дешевле, быстрее и надежнее в долгосрочной перспективе. Это позволяет сфокусировать внутренние ресурсы на анализе данных и принятии бизнес-решений, а не на решении бесконечных технических проблем.
Mini-FAQ: Часто задаваемые вопросы
- Вопрос: Так все-таки, парсить законно или нет?
- Ответ: Это «серая зона». Сам по себе сбор общедоступной информации не запрещен, но вы можете нарушить смежные права изготовителя базы данных (если собираете много данных), закон о персональных данных (если парсите ФИО/контакты) или создать чрезмерную нагрузку на сервер (что могут счесть DDoS-атакой). Ключ — в умеренности и осторожности.
- Вопрос: Меня постоянно блокируют. Что я делаю не так?
- Ответ: Скорее всего, вы используете один IP-адрес (свой) и/или не отправляете заголовок User-Agent. Вам необходима ротация качественных резидентных прокси и смена User-Agent при каждом запросе.
- Вопрос: Какой инструмент выбрать для начала?
- Ответ: Если сайт простой (статичный HTML), начните с requests + BeautifulSoup. Если сайт современный и использует JavaScript для подгрузки цен, ваш лучший выбор — Playwright.
- Вопрос: Я нашел внутренний API сайта. Могу ли я его использовать?
- Ответ: Технически — да, и это самый эффективный способ. Юридически — вы все еще извлекаете данные из их базы данных, поэтому риски, связанные со ст. 1334 ГК РФ, сохраняются. Однако отследить и доказать использование API сложнее, чем агрессивный парсинг HTML-страниц.
- Вопрос: Почему я не могу просто использовать бесплатные прокси?
- Ответ: Бесплатные прокси, как правило, медленные, ненадежные, и их IP-адреса давно находятся во всех черных списках. Крупные сайты заблокируют их мгновенно. Для серьезной работы нужны платные резидентные или мобильные прокси.
- Вопрос: Что лучше: парсить Ozon или Wildberries?
- Ответ: Обе платформы активно защищаются от парсинга. Однако обе используют внутренние API для загрузки данных в каталоге. Наиболее успешная стратегия для обеих площадок — реверс-инжиниринг этих API, а не попытка парсить HTML с помощью эмуляции браузера.
- Ответ: Если вам нужны данные здесь и сейчас для принятия бизнес-решения, и у вас нет свободной команды разработчиков с опытом в парсинге — однозначно покупайте данные у DaaS-провайдера. Это будет быстрее и в итоге дешевле. Если же сбор данных — это ключевая и постоянная часть вашего бизнеса, и у вас есть ресурсы, можно рассмотреть создание собственной системы.
Источники
- Парсинг товаров: эффективный инструмент для продавцов — Облачный парсер, дата последнего обращения: августа 18, 2025, https://cloudparser.ru/wiki/parsing-tovarov-dlya-prodavca
- Почему бизнес может использовать парсинг веб-страниц для сбора данных?, дата последнего обращения: августа 18, 2025, https://proxycompass.com/ru/why-might-a-business-use-web-scraping-to-collect-data/
- Парсинг данных и парсер: что это такое, что значит парсить в программировании, программы в 2024 году — ROMI center, дата последнего обращения: августа 18, 2025, https://romi.center/ru/learning/article/what-is-data-parsing
- Что такое парсинг, зачем он нужен и законно ли парсить данные | Unisender, дата последнего обращения: августа 18, 2025, https://www.unisender.com/ru/glossary/chto-takoe-parsing/
- Scrape Popular E-Commerce Website Data — Ecommerce Data Scraping Services — Actowiz Solutions, дата последнего обращения: августа 18, 2025, https://www.actowizsolutions.com/scrape-popular-ecommerce-website-data.php
- схема работы парсинга для интернет-магазинов, обзор сервисов — InSales, дата последнего обращения: августа 18, 2025, https://www.insales.ru/blogs/university/parsing-dannykh-dlya-internet-magazinov
- Парсер товаров и цен с сайтов: парсинг данных и картинок товаров — Elbuz, дата последнего обращения: августа 18, 2025, https://elbuz.com/parser-internet-magazina
- Парсинг сайтов: что это и зачем он нужен? — Webpromo, дата последнего обращения: августа 18, 2025, https://web-promo.ua/blog/parsing-sajtov-chto-eto-i-zachem-nuzhen/
- Что такое парсинг данных? Определение, преимущества и проблемы — Bright Data, дата последнего обращения: августа 18, 2025, https://ru-brightdata.com/blog/web-data-ru/what-is-data-parsing
- Парсинг: законно ли им пользоваться — Altcraft CDP, дата последнего обращения: августа 18, 2025, https://altcraft.com/ru/glossary/parsing-chto-eto-takoe-i-mogut-li-za-nego-oshtrafovat
- Парсинг сайтов. Россия и мир. Как с точки зрения закона выглядит один из самых полезных инструментов? — Право на vc.ru, дата последнего обращения: августа 18, 2025, https://vc.ru/legal/64328-parsing-saitov-rossiya-i-mir-kak-s-tochki-zreniya-zakona-vyglyadit-odin-iz-samyh-poleznyh-instrumentov
- Как зарегистрировать базу данных и зачем это нужно? — zuykov.com, дата последнего обращения: августа 18, 2025, https://zuykov.com/about/articles/kak-zaregistrirovat-bazu-dannikh-i-zachem-eto-nuzhno/
- ГК РФ Статья 1260. Переводы, иные производные произведения. Составные произведения — КонсультантПлюс, дата последнего обращения: августа 18, 2025, https://www.consultant.ru/document/cons_doc_LAW_64629/26eaf5de7ca59025f4388fe2980d3dd03dd5e775/
- База данных как объект интеллектуальных прав: чего не хватает в регулировании, дата последнего обращения: августа 18, 2025, https://pravo.ru/story/241830/
- Статья 1334 ГК РФ. Исключительное право изготовителя базы данных, дата последнего обращения: августа 18, 2025, https://gkodeksrf.ru/ch-4/rzd-7/gl-71/prg-5/st-1334-gk-rf
- Статья 1334 ГК РФ. Исключительное право изготовителя базы данных — PPT.RU, дата последнего обращения: августа 18, 2025, https://ppt.ru/kodeks/gk/st-1334
- Статья 1334 ГК РФ. Исключительное право изготовителя базы данных, дата последнего обращения: августа 18, 2025, https://rulaws.ru/gk-rf-chast-4/Razdel-VII/Glava-71/paragraph-5/Statya-1334/
- Дело «ВКонтакте» vs «Дабл Дата» — Legal Insight, дата последнего обращения: августа 18, 2025, https://legalinsight.ru/articles/delo-vkontakte-vs-dabl-data/
- HeadHunter обвинил «Робота Веру» в использовании базы данных резюме | RB.RU, дата последнего обращения: августа 18, 2025, https://rb.ru/news/headhunter-protiv-robot-vera/
- Суд отказал HeadHunter в отмене решения ФАС — Право.ру, дата последнего обращения: августа 18, 2025, https://pravo.ru/fas15/news/230786/
- Станислав Данилов о конфликте ФАС и HeadHunter — Pen & Paper, дата последнего обращения: августа 18, 2025, https://pen-paper.com/novosti/pressa-o-pen-i-paper/stanislav-danilov-o-konflikte-fas-i-headhunter/
- Парсинг сайтов — законно ли? — Веб-студия Яворского, дата последнего обращения: августа 18, 2025, https://yavorsky.ru/stati/parsingsaitovzakonno/
- Ultimate Guide to Web Scraping with Python Part 1: Requests and …, дата последнего обращения: августа 18, 2025, https://www.learndatasci.com/tutorials/ultimate-guide-web-scraping-w-python-requests-and-beautifulsoup/
- Intro to Parsing HTML and XML with Python and lxml — Scrapfly, дата последнего обращения: августа 18, 2025, https://scrapfly.io/blog/posts/intro-to-parsing-html-xml-python-lxml
- Python Requests and Beautiful Soup — Playing with HTTP Requests, HTML Parsing and APIs — Fernando Medina Corey, дата последнего обращения: августа 18, 2025, https://www.fernandomc.com/posts/using-requests-to-get-and-post/
- Beautiful Soup: Build a Web Scraper With Python, дата последнего обращения: августа 18, 2025, https://realpython.com/beautiful-soup-web-scraper-python/
- Python lxml tutorial: XML processing and web scraping — Apify Blog, дата последнего обращения: августа 18, 2025, https://blog.apify.com/python-lxml-tutorial/
- Beautiful Soup Documentation — Beautiful Soup 4.4.0 documentation, дата последнего обращения: августа 18, 2025, https://beautiful-soup-4.readthedocs.io/en/latest/
- In-Depth Guide to How Google Search Works, дата последнего обращения: августа 18, 2025, https://developers.google.com/search/docs/fundamentals/how-search-works
- Scraping JavaScript-Rendered Web Pages With Python: Complete Guide 2025 — ZenRows, дата последнего обращения: августа 18, 2025, https://www.zenrows.com/blog/scraping-javascript-rendered-web-pages
- Puppeteer vs Playwright vs Selenium — IPRoyal.com, дата последнего обращения: августа 18, 2025, https://iproyal.com/blog/puppeteer-vs-playwright-vs-selenium/
- Choosing between Playwright, Puppeteer, or Selenium? We …, дата последнего обращения: августа 18, 2025, https://www.browserbase.com/blog/recommending-playwright
- Puppeteer, Selenium, Playwright, Cypress – how to choose? — Testim, дата последнего обращения: августа 18, 2025, https://www.testim.io/blog/puppeteer-selenium-playwright-cypress-how-to-choose/
- requests-html — PyPI, дата последнего обращения: августа 18, 2025, https://pypi.org/project/requests-html/
- Web Scraping With Python and Requests-HTML — Medium, дата последнего обращения: августа 18, 2025, https://medium.com/@datajournal/web-scraping-with-python-and-requests-html-015e202970a0
- Web Scraping With Python and Requests-HTML (with Example) — JC …, дата последнего обращения: августа 18, 2025, https://www.jcchouinard.com/web-scraping-with-python-and-requests-html/
- The ultimate Playwright Python tutorial | BrowserStack, дата последнего обращения: августа 18, 2025, https://www.browserstack.com/guide/playwright-python-tutorial
- Python Playwright: the ultimate guide — Apify Blog, дата последнего обращения: августа 18, 2025, https://blog.apify.com/python-playwright/
- Scrapy Tutorial — Scrapy 2.13.3 documentation, дата последнего обращения: августа 18, 2025, https://docs.scrapy.org/en/latest/intro/tutorial.html
- Scrapy 2.13 documentation — Scrapy 2.13.3 documentation, дата последнего обращения: августа 18, 2025, https://docs.scrapy.org/
- Scrapy Tutorial — Tutorialspoint, дата последнего обращения: августа 18, 2025, https://www.tutorialspoint.com/scrapy/index.htm
- Scrapy in Python: Web Scraping Tutorial 2025 — ZenRows, дата последнего обращения: августа 18, 2025, https://www.zenrows.com/blog/scrapy-python
- Web Scraping Showdown: Comparing Selenium, Puppeteer, and Playwright — Medium, дата последнего обращения: августа 18, 2025, https://medium.com/@fujia1742/web-scraping-showdown-comparing-selenium-puppeteer-and-playwright-59f5c662ae21
- Безопасный веб-скрейпинг: как извлекать данные с сайтов, чтобы вас не заблокировали — Tproger, дата последнего обращения: августа 18, 2025, https://tproger.ru/translations/web-scraping-without-getting-blocked
- Как обойти блокировки сайтов при парсинге? — parsing-cloud.ru, дата последнего обращения: августа 18, 2025, https://parsing-cloud.ru/articles/parsing-saitov-kak-oboiti-blokirovki
- Что такое прокси и как парсить интернет-магазины с их помощью для обхода защиты?, дата последнего обращения: августа 18, 2025, https://vc.ru/services/86635-chto-takoe-proksi-i-kak-parsit-internet-magaziny-s-ih-pomoshyu-dlya-obhoda-zashity
- Полное руководство по прокси для парсинга — Medium, дата последнего обращения: августа 18, 2025, https://medium.com/@spaw.co/%D0%BF%D0%BE%D0%BB%D0%BD%D0%BE%D0%B5-%D1%80%D1%83%D0%BA%D0%BE%D0%B2%D0%BE%D0%B4%D1%81%D1%82%D0%B2%D0%BE-%D0%BF%D0%BE-%D0%BF%D1%80%D0%BE%D0%BA%D1%81%D0%B8-%D0%B4%D0%BB%D1%8F-%D0%BF%D0%B0%D1%80%D1%81%D0%B8%D0%BD%D0%B3%D0%B0-2c4a1c9069c4
- Лучшие прокси-серверы для веб-парсинга — Bright Data, дата последнего обращения: августа 18, 2025, https://ru-brightdata.com/blog/proxy-101-ru/best-scraping-proxies-guide
- Прокси для парсинга: от теории к практике — архитектуры, алгоритмы, подводные камни — Habr, дата последнего обращения: августа 18, 2025, https://habr.com/ru/articles/930002/
- Капча при парсинге: почему появляется и как обойти? | Sparsim, дата последнего обращения: августа 18, 2025, https://sparsim.org/ru/kapcha-pri-parsinge-pochemu-poyavlyayetsya-i-kak-oboyti/
- Advanced Usage — Requests 2.32.4 documentation, дата последнего обращения: августа 18, 2025, https://requests.readthedocs.io/en/master/user/advanced/
- Сессии/сеансы Session() модуля requests в Python — Python3, дата последнего обращения: августа 18, 2025, https://docs-python.ru/packages/modul-requests-python/sessii-seansy-session/
- Robots.txt Introduction and Guide | Google Search Central | Documentation, дата последнего обращения: августа 18, 2025, https://developers.google.com/search/docs/crawling-indexing/robots/intro
- Правда про парсинг сайтов, или «все интернет-магазины делают это» / Комментарии / Хабр — Habr, дата последнего обращения: августа 18, 2025, https://habr.com/ru/articles/446488/comments/
- Парсинг сайтов — 5 ключевых ошибок | Datacol, дата последнего обращения: августа 18, 2025, https://web-data-extractor.net/parsing-sajtov-5-klyuchevyh-oshibok/
- Making network requests with JavaScript — Learn web development | MDN, дата последнего обращения: августа 18, 2025, https://developer.mozilla.org/en-US/docs/Learn_web_development/Core/Scripting/Network_requests
- Can JavaScript rendering be of use against major AI scrapers since they don’t mostly don’t render JS? : r/webdev — Reddit, дата последнего обращения: августа 18, 2025, https://www.reddit.com/r/webdev/comments/1icru6c/can_javascript_rendering_be_of_use_against_major/
- Scraping Data from JavaScript rendered tables with Python — YouTube, дата последнего обращения: августа 18, 2025, https://www.youtube.com/watch?v=qxj7EXYeNls
- How to find and use hidden APIs to automate processes, дата последнего обращения: августа 18, 2025, https://aatt.io/newsletters/how-to-find-and-use-hidden-apis-to-automate-processes
- Finding Undocumented APIs — Inspect Element, дата последнего обращения: августа 18, 2025, https://inspectelement.org/apis.html
- Scraping through hidden APIs : r/webscraping — Reddit, дата последнего обращения: августа 18, 2025, https://www.reddit.com/r/webscraping/comments/1c1mfh6/scraping_through_hidden_apis/
- Can someone shed light on how to retrieve a website’s API instead of trying to scrape the webpages? : r/learnpython — Reddit, дата последнего обращения: августа 18, 2025, https://www.reddit.com/r/learnpython/comments/ucijdo/can_someone_shed_light_on_how_to_retrieve_a/
- How to parse a dynamically loading wildberries page? — Stack Overflow, дата последнего обращения: августа 18, 2025, https://stackoverflow.com/questions/68198696/how-to-parse-a-dynamically-loading-wildberries-page
- Product cards list — Documentation — WB API — Wildberries, дата последнего обращения: августа 18, 2025, https://dev.wildberries.ru/openapi/work-with-products
- Что такое API на Wildberries и как работает — информация экспертов агентства «Шольчев» для продавцов на Вайлдберриз, дата последнего обращения: августа 18, 2025, https://sholchev.ru/blog/wildberries-api/
- token — Documentation — WB API — Wildberries, дата последнего обращения: августа 18, 2025, https://dev.wildberries.ru/en/openapi/api-information
- Бот-парсер маркетплейса на Python — Habr, дата последнего обращения: августа 18, 2025, https://habr.com/ru/companies/amvera/articles/834582/
- kirillignatyev/wildberries-parser-in-python — GitHub, дата последнего обращения: августа 18, 2025, https://github.com/kirillignatyev/wildberries-parser-in-python
- Wildberries.ru marketplace scraper using MySQL and hidemy.name proxies. — GitHub, дата последнего обращения: августа 18, 2025, https://github.com/berenzorn/wildberries
- Data Scraping Services: In-House vs. Outsourcing — Pros and Cons — PromptCloud, дата последнего обращения: августа 18, 2025, https://www.promptcloud.com/blog/data-scraping-services-in-house-vs-outsourcing-pros-and-cons/
- To Build or To Buy? The Keys to a Successful Web Scraping Project — WebAutomation, дата последнего обращения: августа 18, 2025, https://webautomation.io/blog/to-build-or-to-buy-the-keys-to-a-successful-web-scraping-project/
- Outsourcing Web Scraping is Better Than Inhouse — Here’s Why! — AskDataEntry, дата последнего обращения: августа 18, 2025, https://www.askdataentry.com/blog/why-outsourcing-web-scraping-is-better-than-inhouse/
- Build vs. buy: Real cost analysis of web scraping infrastructure — SOAX, дата последнего обращения: августа 18, 2025, https://soax.com/blog/build-vs-buy-web-scraping-cost-analysis
- Build vs. Buy: Decoding the Web Scraping Dilemma for Competitive Pricing Intelligence, дата последнего обращения: августа 18, 2025, https://anakin.company/blogs/build-vs-buy-web-scraping-dilemma
- Build vs Buy for Data Acquisition – What Works Best for You? — PromptCloud, дата последнего обращения: августа 18, 2025, https://www.promptcloud.com/blog/build-vs-buy-for-data-acquisition/
- outsourcing web scraping vs doing it yourself — X-Byte Enterprise Crawling, дата последнего обращения: августа 18, 2025, https://www.xbyte.io/outsourcing-web-scraping-vs-doing-it-yourself/
- Choosing the Right Solution: Web Scraping Tool vs. Service — ScrapeHero, дата последнего обращения: августа 18, 2025, https://www.scrapehero.com/web-scraping-tool-vs-service/
- 10 modern tools to parse information from websites, including competitors’ prices — Apifornia, дата последнего обращения: августа 18, 2025, https://blog.apifornia.com/tools-to-parse-information-from-websites/
- Infax – Flightview XML Data Feed Agreement Terms and … — Minot, ND, дата последнего обращения: августа 18, 2025, https://www.minotnd.gov/AgendaCenter/ViewFile/Item/6151?fileID=19639
- Import Data from a Reporting Services Report — Microsoft Support, дата последнего обращения: августа 18, 2025, https://support.microsoft.com/en-us/office/import-data-from-a-reporting-services-report-6c196bd9-05ee-4759-99c9-ac10d57260a1
- Shopping XML Data Feed — AdMedia | Premier Advertising Network | Reach 200M+ US Users, дата последнего обращения: августа 18, 2025, https://admedia.com/affiliate_solutions/search/shopping_xml_feed/
ПОХОЖИЕ ПУБЛИКАЦИИ:
 Полное руководство по мониторингу цен конкурентов на Wildberries и Ozon
Полное руководство по мониторингу цен конкурентов на Wildberries и Ozon  Лучший парсер цен 2023 года (парсинг цен с сайтов электронной коммерции)
Лучший парсер цен 2023 года (парсинг цен с сайтов электронной коммерции)  Парсинг простых веб-страниц с Beautiful Soup: Полное руководство для начинающих и не только
Парсинг простых веб-страниц с Beautiful Soup: Полное руководство для начинающих и не только  101 Термин про парсинг сайтов: Полное руководство для экспертов и начинающих
101 Термин про парсинг сайтов: Полное руководство для экспертов и начинающих  Защита вашего сайта от парсинга: Полное руководство по лучшим решениям
Защита вашего сайта от парсинга: Полное руководство по лучшим решениям  Парсинг аудитории в Telegram: Полное техническое и правовое исследование
Парсинг аудитории в Telegram: Полное техническое и правовое исследование  Полное руководство по парсингу, по мнению экспертов
Полное руководство по парсингу, по мнению экспертов  Полное руководство по скрин парсингу 2023 (Сравнение парсеров экранов)
Полное руководство по скрин парсингу 2023 (Сравнение парсеров экранов)  Headless-браузеры для парсинга: Полное руководство по автоматизации, обходу блокировок и масштабированию
Headless-браузеры для парсинга: Полное руководство по автоматизации, обходу блокировок и масштабированию
БЫТОВЫЕ УСЛУГИ
База всех компаний в категории: ДОМОФОНЫ
ТОРГОВЫЕ УСЛУГИ
База всех компаний в категории: РЫНОК
ОБРАЗОВАТЕЛЬНЫЕ УСЛУГИ
База всех компаний в категории: ШКОЛЫ ИСКУССТВ
ИСКУССТВО И КУЛЬТУРА
База всех компаний в категории: ЛАНДШАФТНЫЙ ДИЗАЙНЕР
ТОРГОВЫЕ УСЛУГИ
База всех компаний в категории: ДЕТСКИЙ МАГАЗИН
УСЛУГИ СВЯЗИ
База всех компаний в категории: СВЯЗЬ ОРГАНИЗАЦИИ
ЦИФРОВЫЕ УСЛУГИ
База всех компаний в категории: ЦИФРОВАЯ ПЕЧАТЬ
МЕДИЦИНСКИЕ УСЛУГИ
База всех компаний в категории: ВРАЧ СПОРТИВНОЙ МЕДИЦИНЫ