













Бизнес практика,Бизнес-аналитика,Общие вопросы парсинга
Парсинг и запрет в оферте: можно ли законно собирать данные конкурентов

Сен
Ваш конкурент запретил в «Пользовательском соглашении» собирать цены с его сайта. Означает ли это, что парсинг под запретом и вам грозит суд? Этот вопрос — один из самых частых и тревожных для бизнеса, который хочет использовать данные для роста. Кажется, что ответ очевиден: раз есть прямой запрет, значит, нарушать его нельзя. Но в мире права, особенно в сфере информационных технологий, все гораздо сложнее и многограннее.
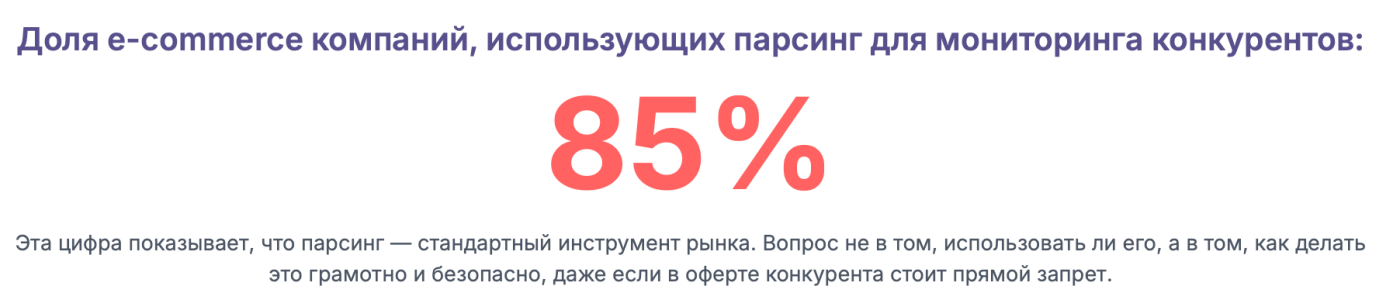
Простой ответ «да» или «нет» здесь был бы не просто неверным, но и вредным. Правда заключается в том, что прямой запрет в оферте интернет-магазина — это лишь верхушка айсберга. Его юридическая сила не абсолютна и вступает в сложное взаимодействие с вашим фундаментальным правом на информацию, антимонопольным законодательством и целым рядом других правовых норм.
Эта статья — исчерпывающее руководство, которое проведет вас через все слои этой проблемы. Мы разберем:
- Конфликт законов: Почему ваше конституционное право на информацию может оказаться весомее, чем условия частного договора, составленного вашим конкурентом.
- Реальные и мнимые риски: Мы отделим настоящие юридические угрозы (такие как нарушение прав на базу данных или сбор персональных данных) от «бумажных тигров», которыми часто и является пункт о запрете парсинга.
- Технический этикет: Как настроить сбор данных так, чтобы не только оставаться в рамках закона, но и показать себя «хорошим ботом», с которым не захотят конфликтовать.
- Практические шаги: Мы предоставим четкий чек-лист для безопасного внедрения парсинга и разберем, почему в России почти нет судебных дел о сборе цен, и чему нас это учит.
В итоге вы получите не просто ответ на вопрос, а ясную карту правового поля и практическую инструкцию по безопасному и законному использованию парсинга как мощного инструмента для анализа рынка и принятия верных бизнес-решений.
Раздел 1. Фундаментальный вопрос: правила сайта против вашего права на информацию
В основе всей дискуссии о законности парсинга при наличии запрета в пользовательском соглашении лежит столкновение двух мощных юридических концепций. С одной стороны — свобода договора, позволяющая владельцу сайта устанавливать свои правила. С другой — фундаментальное право каждого на свободный доступ к информации. Чтобы понять, какая из этих концепций имеет больший вес в нашем случае, необходимо разобраться в природе каждой из них.
Что такое публичная оферта интернет-магазина и ее юридическая сила
Когда вы заходите на сайт любого интернет-магазина, вы вступаете с ним в правовые отношения, даже если ничего не покупаете. Информация о товарах, их характеристики и цены, размещенные на сайте и адресованные неопределенному кругу лиц, с юридической точки зрения являются публичной офертой.1 Это официальное предложение заключить договор купли-продажи на указанных условиях.
Документ, который регулирует правила поведения на сайте (часто называется «Пользовательское соглашение», «Условия использования» или «Публичная оферта»), является неотъемлемой частью этих отношений. С точки зрения Гражданского кодекса РФ, такое соглашение представляет собой договор присоединения (статья 428 ГК РФ).2

Что это означает на простом языке? Договор присоединения — это договор, условия которого разработаны одной стороной (в нашем случае — владельцем сайта) в стандартных формах, и другая сторона (пользователь) может принять эти условия не иначе как путем присоединения к предложенному договору в целом.3 Вы не можете предложить свои правки или исключить какой-то пункт. Вы либо принимаете все правила игры, либо отказываетесь от использования сайта. Сам факт того, что вы начали пользоваться сайтом — просматривать страницы, искать товары — как правило, рассматривается как акцепт (принятие) условий этой оферты.
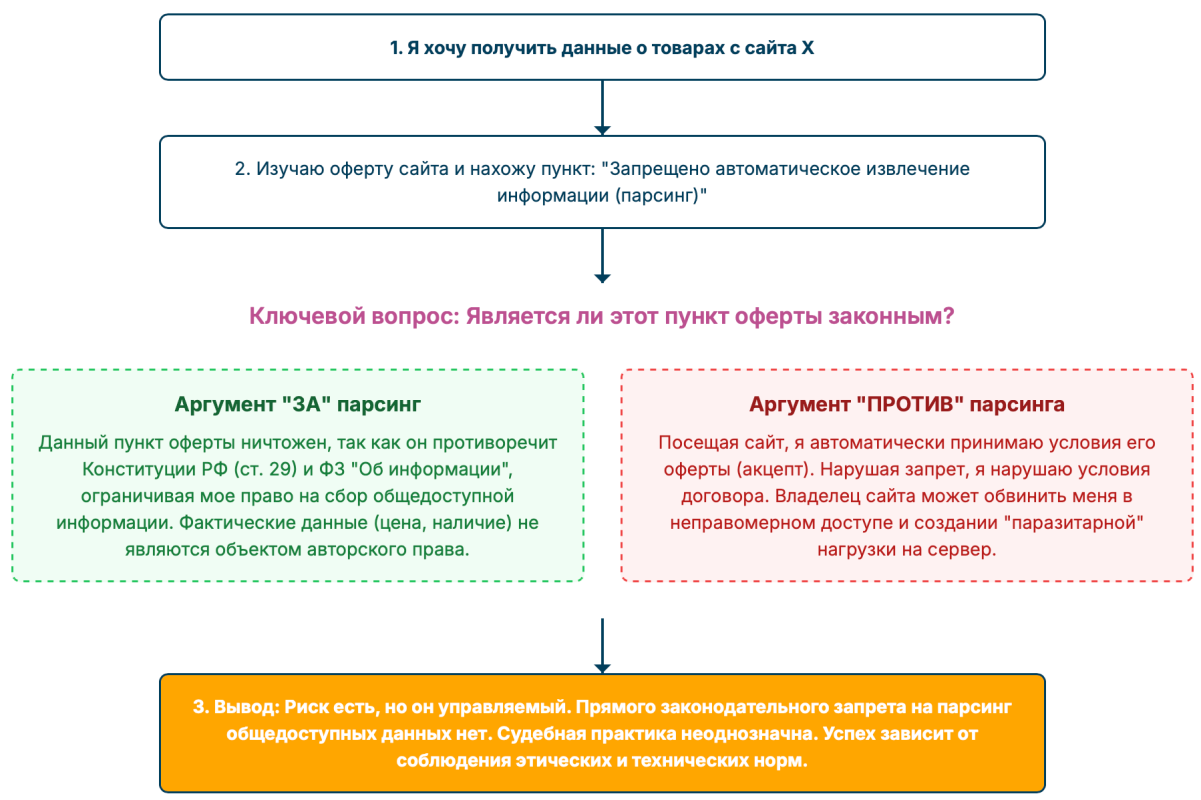
Таким образом, запрет на автоматизированный сбор данных (парсинг), прописанный в таком соглашении, имеет юридическую силу. Это не просто пожелание владельца сайта, а формально принятое вами условие договора. Однако, как и у любого договора, у его силы есть свои пределы.
Конституционное право на свободный поиск и получение информации: как оно работает в интернете
На другой чаше весов находится одно из ключевых конституционных прав — право свободно искать, получать, передавать, производить и распространять информацию любым законным способом. Это право закреплено в статье 29 Конституции РФ и детализировано в Федеральном законе № 149-ФЗ «Об информации, информационных технологиях и о защите информации».
Статья 8 этого закона прямо гласит, что граждане и организации вправе осуществлять поиск и получение любой информации в любых формах и из любых источников при условии соблюдения требований, установленных федеральными законами.4 Интернет-магазин, размещая в открытом доступе информацию о товарах и ценах, фактически создает такой общедоступный источник. Цель этой информации — донести ее до максимально широкого круга потребителей для стимуляции продаж.
Это право является основой здоровой конкуренции и свободного рынка. Возможность для потребителей и бизнеса сравнивать цены, анализировать ассортимент и следить за рыночными тенденциями — неотъемлемая часть современной экономики. Автоматизация этого процесса с помощью парсинга — лишь технический способ реализации этого фундаментального права в цифровом веке. Собирать вручную информацию с тысяч страниц неэффективно; парсинг делает этот процесс быстрым и точным.
Столкновение интересов: когда частный договор пытается ограничить публичное право
Итак, мы имеем явный конфликт. С одной стороны, владелец сайта, используя принцип свободы договора (статья 421 ГК РФ), устанавливает в договоре присоединения запрет на парсинг.5 С другой стороны, вы, как участник рынка, хотите реализовать свое законное право на сбор общедоступной информации.4
Ключевой момент, который помогает разрешить это противоречие, кроется в самой формулировке закона «Об информации». Он позволяет получать любую информацию при условии соблюдения требований других федеральных законов. Это означает, что право на информацию не является абсолютным и должно быть сбалансировано с другими правовыми институтами, такими как защита интеллектуальной собственности, персональных данных и коммерческой тайны.
Представьте себе аналогию. Владелец крупного торгового центра может установить внутренние правила поведения для посетителей. Но может ли он на законных основаниях запретить вам запоминать или записывать в блокнот цены на товары в витринах? Такой запрет выглядел бы абсурдным, поскольку противоречит самой сути торговли. Точно так же, запрет на сбор общедоступной информации о ценах в интернете входит в противоречие с основной целью существования интернет-магазина — распространением этой самой информации.
Таким образом, вопрос сводится не к тому, что «сильнее» — Конституция или оферта. Вопрос в том, является ли запрет на парсинг общедоступных, фактических данных (которые не являются чьей-то интеллектуальной собственностью) законным и обоснованным ограничением вашего права на информацию. Как мы увидим в следующих разделах, в большинстве случаев такой запрет является чрезмерным и юридически уязвимым. Судебная система стремится найти баланс, и этот баланс чаще всего склоняется в сторону свободного оборота фактической информации, при условии, что ее сбор не нарушает других, более серьезных законов.
Раздел 2. Парсинг в россии: что говорит закон в целом
Прежде чем углубляться в детали договорных запретов, важно понять, как российское законодательство в принципе относится к парсингу как к явлению. Часто вокруг этого термина существует множество мифов и страхов, которые не имеют под собой реальной правовой основы.
Базовый принцип: сбор общедоступной информации законен
Самое главное, что нужно понять: в российском законодательстве нет прямого запрета на парсинг как на технологию или процесс. Сбор информации, которая находится в открытом, общедоступном доступе, сам по себе не является правонарушением.6
По своей сути, парсинг — это всего лишь автоматизация действий, которые любой человек может совершить вручную. Программа-парсер (или «краулер», «бот») делает то же самое, что и вы, когда открываете сайт в браузере: отправляет запрос на сервер, получает в ответ HTML-код страницы и извлекает из него нужные данные. Это можно сравнить с использованием калькулятора вместо счета в столбик или автомобиля вместо пешей прогулки. Метод становится более эффективным, но суть действия не меняется.
Если информация (например, цена, название товара, его характеристики) видна любому посетителю сайта без необходимости вводить пароль, проходить регистрацию или совершать иные действия для получения доступа, то такая информация считается общедоступной. И ее сбор, в том числе автоматизированный, является законной реализацией вашего права на информацию.
Этот базовый принцип является отправной точкой для всего дальнейшего анализа. Проблемы начинаются не на этапе сбора данных как такового, а тогда, когда этот процесс пересекает определенные «красные линии», установленные законом.
Красные линии: когда парсинг становится правонарушением (краткий обзор)
Законность парсинга — это не вопрос «можно или нельзя», а вопрос «как именно и что именно». Легальный и этичный парсинг превращается в правонарушение, когда в процессе сбора или при дальнейшем использовании данных нарушаются конкретные нормы законодательства. Вот основные «красные линии», которые нельзя пересекать:
- Нарушение авторских и смежных прав. Это одна из самых серьезных и часто недооцениваемых зон риска. Хотя факты (цена, вес) не охраняются авторским правом, их совокупность в виде базы данных, а также контент (описания товаров, фотографии, статьи) могут быть объектами интеллектуальной собственности. Массовое копирование и использование такого контента является прямым нарушением.7
- Сбор и обработка персональных данных. Если в процессе парсинга вы собираете любую информацию, относящуюся к определенному или определяемому физическому лицу (ФИО, телефоны, email из отзывов или со страниц продавцов на маркетплейсах), вы подпадаете под действие Федерального закона № 152-ФЗ «О персональных данных». Нарушение этого закона влечет за собой колоссальные штрафы.8
- Создание чрезмерной нагрузки на сервер. Если ваш парсер отправляет слишком много запросов за короткий промежуток времени, это может замедлить работу сайта-источника или даже привести к его полной недоступности. Такие действия могут быть квалифицированы как разновидность DDoS-атаки, что может повлечь за собой не только гражданскую, но и уголовную ответственность.6
- Неправомерный доступ к компьютерной информации. Эта «красная линия» пересекается, когда парсер пытается получить доступ к информации, которая не является общедоступной. Например, подбирает пароли, использует уязвимости сайта для доступа к закрытым разделам или административной панели. Это уже серьезное уголовное преступление (статья 272 УК РФ).7
- Недобросовестная конкуренция и злоупотребление правом. Даже если вы формально не нарушаете ни один из вышеперечисленных пунктов, ваши действия могут быть признаны актом недобросовестной конкуренции. Например, если вы используете собранные данные для создания точной копии (клона) бизнеса конкурента, вводя потребителей в заблуждение, или целенаправленно вредите его работе.7
Важно понимать, что ни в одном из этих случаев закон не наказывает за «парсинг». Закон наказывает за кражу контента, за нарушение прайваси, за вывод из строя оборудования, за взлом или за нечестные методы ведения бизнеса. Парсинг здесь выступает лишь как инструмент, с помощью которого было совершено правонарушение. Точно так же, как молоток является легальным инструментом, но его использование для взлома чужого дома — преступление.
Этот подход полностью меняет оптику проблемы. Задача бизнеса — не бояться самого слова «парсинг», а выстроить процесс сбора данных таким образом, чтобы этот мощный и легальный инструмент не использовался для пересечения упомянутых «красных линий».
Раздел 3. Запрет на парсинг в оферте: «бумажный тигр» или реальная угроза?
Теперь, когда мы установили, что сам по себе парсинг общедоступных данных законен, вернемся к нашему главному вопросу: что делать с прямым запретом в пользовательском соглашении? Если вы, заходя на сайт, автоматически соглашаетесь с его правилами, означает ли это, что запрет на парсинг становится для вас непреложным законом? Ответ кроется в особой юридической природе таких соглашений.
Пользовательское соглашение как «договор присоединения» (ст. 428 ГК РФ): что это значит на простом языке
Как уже упоминалось, пользовательское соглашение на сайте — это классический пример договора присоединения.2 Его ключевая особенность в том, что одна сторона (бизнес) определяет все условия в стандартной форме, а другая сторона (клиент, пользователь) не имеет возможности вести переговоры и влиять на эти условия.3 Вы либо нажимаете «Принимаю», либо просто начинаете пользоваться сервисом, тем самым присоединяясь к договору в целом.
Такая модель очень удобна для массовых сервисов — от покупки авиабилетов и использования программного обеспечения до посещения интернет-магазинов. Она избавляет от необходимости заключать индивидуальный договор с каждым из миллионов пользователей.12
Однако у этой модели есть и обратная сторона, которую законодатель прекрасно понимает. Сторона, которая составляет такой договор, находится в заведомо более сильной позиции. Она может включить в него условия, которые выгодны только ей и ущемляют права присоединившейся, более слабой стороны. Чтобы защитить слабую сторону от злоупотреблений, Гражданский кодекс ввел специальные механизмы, которые ограничивают всемогущество составителя договора присоединения.
Когда запрет можно оспорить: несправедливые и обременительные условия договора
Ключевым для нас является пункт 2 статьи 428 Гражданского кодекса. Он дает присоединившейся стороне право потребовать изменения или даже расторжения договора, если он:
- Лишает эту сторону прав, которые обычно предоставляются по договорам такого вида.
- Исключает или ограничивает ответственность сильной стороны за нарушение обязательств.
- Содержит другие явно обременительные для присоединившейся стороны условия, которые она, исходя из своих разумно понимаемых интересов, не приняла бы при наличии у нее возможности участвовать в определении условий договора.3
Судебная практика подтверждает, что если суд установит наличие таких «несправедливых» договорных условий, он может их изменить или признать недействительными по требованию слабой стороны.15
Теперь применим эту норму к нашему запрету на парсинг. Можно ли считать полный и безоговорочный запрет на сбор общедоступной фактической информации (цен, наименований, наличия товара) «явно обременительным» условием? Аргументы в пользу этого достаточно весомы:
- Противоречие цели договора. Основная цель интернет-магазина — распространить информацию о своих товарах и ценах как можно шире, чтобы привлечь покупателей. Запрет на эффективный сбор этой информации противоречит этой фундаментальной цели.
- Ограничение законного права. Как мы выяснили, сбор общедоступной информации — это реализация законного права. Попытка полностью его аннулировать через стандартную форму договора, на которую пользователь не может повлиять, может рассматриваться как злоупотребление со стороны владельца сайта.
- Нарушение баланса интересов. Интерес владельца сайта — защититься от вредоносной активности (DDoS-атак, кражи контента). Интерес рынка (включая конкурентов и потребителей) — иметь доступ к информации для анализа и сравнения. Полный запрет на любой автоматизированный сбор данных непропорционально защищает интерес владельца, полностью игнорируя законные интересы другой стороны. Более справедливым был бы запрет на чрезмерно интенсивный парсинг или на копирование охраняемого контента, но не на сбор фактов как таковой.
Таким образом, существует прочная правовая основа для того, чтобы оспорить легитимность такого запрета в суде, доказав его «обременительность» и «несправедливость».
Практический вывод: почему сам по себе запрет в оферте — слабая юридическая позиция
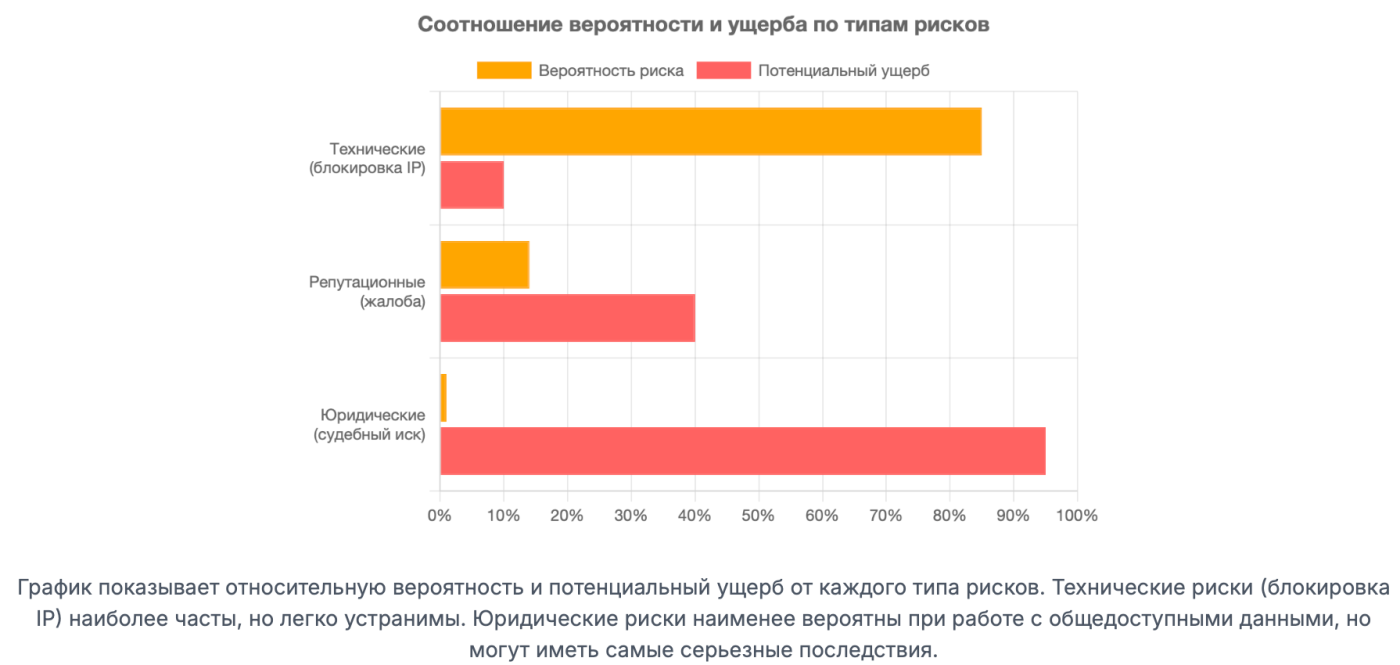
На практике это означает, что владелец интернет-магазина, который решит подать в суд на компанию только за то, что она нарушила пункт оферты о запрете парсинга (при условии, что парсинг велся аккуратно и собирались только факты), столкнется с огромными трудностями.
Во-первых, ему будет крайне сложно доказать факт причинения убытков. Какой ущерб был нанесен тем, что конкурент узнал его публичные цены на 15 минут раньше, чем мог бы это сделать вручную? В отсутствие реального ущерба (например, падения сайта или кражи клиентской базы) суд, скорее всего, не увидит оснований для удовлетворения иска.
Во-вторых, ответчик (тот, кто парсил) сможет выдвинуть встречные аргументы, основанные на статье 428 ГК РФ, о несправедливости и обременительности данного пункта договора.
Именно поэтому пункт о запрете парсинга в пользовательском соглашении часто называют «бумажным тигром». Его основная цель — не столько создание прочной юридической позиции для будущего суда, сколько психологическое и техническое сдерживание. Он служит основанием для технических служб сайта блокировать IP-адреса парсеров («мы просто обеспечиваем соблюдение наших правил») и отпугивает компании, которые не хотят вникать в юридические тонкости и предпочитают не рисковать.
Для грамотного и уверенного в своей позиции бизнеса это означает, что сам по себе этот запрет не является непреодолимым препятствием. Настоящие риски лежат в другой плоскости — в нарушении более фундаментальных законов, которые мы рассмотрим далее.
Раздел 4. Главные юридические риски при парсинге: на что действительно стоит обратить внимание
Сосредоточившись на запрете в оферте, многие упускают из виду реальные юридические «мины», на которых можно подорваться. В отличие от спорного пункта в пользовательском соглашении, эти риски закреплены в Гражданском и даже Уголовном кодексах, и их нарушение может повлечь за собой очень серьезные финансовые и репутационные последствия. Давайте подробно разберем каждую из этих угроз.
Риск №1: Авторское право и право на базу данных (самый неочевидный и серьезный риск)
Это, пожалуй, самый сложный для понимания, но при этом самый значительный риск при парсинге каталогов интернет-магазинов. Распространенное заблуждение гласит: «факты не охраняются авторским правом». Это правда. Цена товара, его вес, артикул, название — это просто факты. Однако закон защищает не только отдельные элементы, но и результат интеллектуального труда по их подбору, систематизации и представлению.
Российское законодательство (Часть 4 Гражданского кодекса РФ) предусматривает два уровня защиты для совокупности данных, которые вместе образуют каталог интернет-магазина.17
- База данных как объект авторского права (творческая база данных, ст. 1260 ГК РФ).
База данных получает охрану как объект авторского права, если подбор или расположение ее материалов является результатом творческого труда составителя.18 Что это значит на практике? Если товары в каталоге сгруппированы по стандартным, общепринятым признакам (например, по алфавиту, по цене, по категориям «смартфоны», «ноутбуки»), то творческого характера здесь нет. Но если владелец сайта разработал уникальную, оригинальную систему классификации, создал неочевидные фильтры, написал аналитические подборки (например, «топ-10 смартфонов для геймеров с лучшим охлаждением»), то такая структура и подборка материалов могут быть признаны результатом творческого труда и будут охраняться авторским правом.18 Копирование такой структуры будет нарушением. - База данных как объект смежных прав (инвестиционная база данных, ст. 1334 ГК РФ).
Это гораздо более распространенный и релевантный для e-commerce случай. Закон предоставляет особую охрану изготовителю базы данных, создание которой (включая обработку и представление соответствующих материалов) потребовало существенных финансовых, материальных, организационных или иных затрат.18
Создание и поддержка каталога крупного интернет-магазина с десятками тысяч товарных позиций — это колоссальные инвестиции: зарплаты контент-менеджеров, фотографов, закупка данных у поставщиков, разработка ПО. Закон защищает эти инвестиции.
Более того, закон устанавливает презумпцию: если база данных содержит не менее 10 000 самостоятельных информационных элементов (например, 10 000 карточек товаров), то считается, что на ее создание были понесены существенные затраты.18
Нарушением прав изготовителя такой базы данных является извлечение и последующее использование существенной части составляющих ее материалов. Понятие «существенная часть» является оценочным, но парсинг всего каталога или его основных разделов однозначно подпадает под это определение.
Практические выводы:
- Нельзя «клонировать» каталоги. Самая опасная стратегия — это полный парсинг каталога конкурента с целью создания аналогичного каталога на своем сайте.
- Собирайте только факты. Фокусируйтесь на извлечении конкретных, необходимых вам данных: артикул, цена, статус наличия, количество отзывов. Не копируйте описания, обзоры, и особенно фотографии — они являются самостоятельными объектами авторского права.
- Используйте данные для анализа, а не для перепубликации. Цель парсинга должна быть аналитической: мониторинг цен, анализ ассортимента, динамическое ценообразование. Использование собранных данных для наполнения собственного публичного каталога — прямой путь к судебному иску.
Риск №2: Персональные данные (ФЗ-152)
Этот риск абсолютно недвусмысленный и очень дорогой. Федеральный закон № 152-ФЗ «О персональных данных» устанавливает строжайшие правила сбора, хранения и обработки любой информации, которая прямо или косвенно относится к определенному физическому лицу.
Применительно к парсингу интернет-магазинов, в зону риска попадают:
- Отзывы и комментарии: Часто содержат имена, фамилии, никнеймы, а иногда и города или другие детали, позволяющие идентифицировать человека.
- Данные о продавцах на маркетплейсах: Многие площадки публикуют ФИО, ИНН, а иногда и контактные телефоны индивидуальных предпринимателей и самозанятых, торгующих на их платформе.
- Данные из разделов «Наша команда», форумов, блогов, если они есть на сайте магазина.
Сбор такой информации с помощью парсинга без явного и однозначного согласия субъекта этих данных является грубейшим нарушением. Ответственность за это несет «оператор», то есть лицо, организовавшее сбор данных. Штрафы для юридических лиц за незаконную обработку персональных данных могут достигать 18 000 000 рублей и выше, особенно при повторных нарушениях или при утечке больших объемов данных.19 Кроме того, предусмотрена и уголовная ответственность для должностных лиц.19
Практические выводы:
- Золотое правило: не собирать персональные данные. Вообще. Никакие.
- Тщательно настраивайте парсер. Необходимо четко указать программе, какие блоки на странице следует игнорировать (например, div с классом reviews или comments).
- Проводите аудит собранных данных. Регулярно проверяйте, не попали ли в вашу базу данных случайные фрагменты с персональной информацией. Если попали — немедленно удаляйте.
- Не парсите личные кабинеты и профили пользователей, даже если у вас есть легальный доступ к своему собственному.
Риск №3: Неправомерный доступ и создание угрозы для сайта (УК РФ)
Этот риск переводит нас из плоскости гражданского права в уголовную. Две статьи Уголовного кодекса РФ имеют прямое отношение к неаккуратному парсингу.
- Статья 272 УК РФ «Неправомерный доступ к компьютерной информации».
Под «неправомерным доступом» понимается доступ к информации в обход установленных средств защиты.22 Если вы парсите общедоступные страницы, которые открываются у любого пользователя в браузере, состава этого преступления, как правило, нет. Однако, если ваш парсер пытается подобрать пароли, использовать уязвимости в коде сайта для доступа к закрытым разделам (например, к базе данных клиентов или к административной панели), это является классическим примером неправомерного доступа. Последствия — от крупного штрафа до лишения свободы. - Последствия парсинга как часть состава преступления.
Даже если доступ был к публичной информации, статья 272 УК РФ становится применимой, если ваши действия повлекли за собой уничтожение, блокирование, модификацию либо копирование компьютерной информации.
Ключевое слово здесь — «блокирование». Если ваш парсер работает слишком агрессивно, отправляя тысячи запросов в минуту, он может создать такую нагрузку на сервер конкурента, что сайт перестанет открываться у обычных пользователей. Это и есть блокирование доступа к информации. В такой ситуации владелец сайта может обратиться в правоохранительные органы, и ваши действия будут рассматриваться уже не как сбор данных, а как DDoS-атака, со всеми вытекающими уголовно-правовыми последствиями.6
Практические выводы:
- Никогда не пытайтесь обойти системы защиты. Не парсите страницы, требующие авторизации (если только это не ваш собственный аккаунт и это не запрещено правилами).
- Уважайте чужую инфраструктуру. Главный технический приоритет — не навредить работе сайта-источника. Это достигается грамотной настройкой скорости парсинга (rate limiting), о чем мы поговорим в следующем разделе.
Риск №4: Недобросовестная конкуренция и злоупотребление правом (ст. 10 ГК РФ)
Это самый тонкий и оценочный риск. Статья 10 Гражданского кодекса РФ устанавливает запрет на злоупотребление правом. Это означает, что не допускается осуществление гражданских прав исключительно с намерением причинить вред другому лицу.27 Как это применимо к парсингу? У вас есть право на сбор информации. Но если вы реализуете это право недобросовестно, с основной целью навредить конкуренту, суд может отказать вам в защите этого права.29
Примеры злоупотребления правом при парсинге:
- Целенаправленное создание нагрузки. Вы знаете, что у вашего маленького конкурента слабый сервер, и запускаете парсинг в «черную пятницу» в самое пиковое время, чтобы замедлить его работу и переманить клиентов. Формально вы собираете информацию, но ваша основная цель — вред.
- Создание паразитического бизнеса. Вы парсите не только цены, но и весь контент, структуру, и на основе этих данных создаете сайт-клон, который вводит потребителей в заблуждение и напрямую паразитирует на инвестициях и репутации конкурента.
- Систематическое игнорирование просьб прекратить. Владелец сайта вежливо просит вас снизить интенсивность парсинга, а вы демонстративно ее увеличиваете.
Обвинение в злоупотреблении правом часто идет в связке с обвинением в недобросовестной конкуренции (согласно Федеральному закону № 135-ФЗ «О защите конкуренции»). Доказать злой умысел сложно, но если у истца это получится, последствия могут быть серьезными, включая возмещение убытков и предписание прекратить противоправные действия.
Практические выводы:
- Действуйте добросовестно. Ваша цель должна быть честной и экономически обоснованной — анализ рынка для улучшения собственного бизнеса, а не для разрушения чужого.
- Будьте готовы к диалогу. Если владелец сайта-источника выходит на связь, не игнорируйте его. Часто проблемы можно решить простым разговором и корректировкой настроек парсера.
- Сохраняйте доказательства своей добросовестности. Соблюдение технического этикета (о котором пойдет речь дальше) — лучший аргумент в вашу пользу.
Для наглядности сведем все риски в единую таблицу.
Таблица 1: Карта юридических рисков при парсинге и способы их минимизации
| Тип риска | Суть риска простыми словами | Возможные последствия | Ключевые меры по снижению риска |
| Нарушение прав на базу данных (ст. 1334 ГК РФ) | Копирование значительной части каталога конкурента, в создание которого он вложил много денег и сил. | Иск о возмещении убытков; требование прекратить использование данных; штраф до 5 млн. рублей или в двукратном размере стоимости права использования. | Собирать только нужные факты (цена, наличие, артикул). Не копировать весь каталог целиком. Не использовать чужие описания и фото. Использовать данные для внутреннего анализа. |
| Нарушение закона о персональных данных (ФЗ-152) | Сбор любой информации, по которой можно определить конкретного человека (ФИО, контакты из отзывов и т.д.). | Административные штрафы до 18 млн. рублей и выше для юрлиц; уголовная ответственность для должностных лиц; блокировка ресурса Роскомнадзором. | Полный отказ от сбора персональных данных. Тщательная настройка парсера на игнорирование соответствующих блоков на страницах. |
| Неправомерный доступ / Блокирование работы сайта (ст. 272 УК РФ) | Попытка взломать сайт или слишком агрессивный парсинг, который приводит к сбою в работе ресурса. | Уголовная ответственность: штраф до 500 тыс. рублей, исправительные работы, лишение свободы на срок до 5 лет. | Парсить только общедоступные страницы. Строго контролировать скорость и интенсивность запросов, чтобы не создавать избыточной нагрузки на сервер. |
| Злоупотребление правом / Недобросовестная конкуренция (ст. 10 ГК РФ, ФЗ-135) | Использование парсинга не для анализа, а с основной целью причинить вред конкуренту или создать бизнес-клон. | Отказ суда в защите ваших прав; возмещение убытков; предписание ФАС о прекращении недобросовестной конкуренции. | Иметь четкую и законную бизнес-цель для сбора данных. Соблюдать технический и деловой этикет. Не создавать продукты, паразитирующие на чужом бизнесе. |
Раздел 5. Техническая сторона этичного парсинга: как показать себя «хорошим ботом»
Минимизация юридических рисков неразрывно связана с технической грамотностью и этикой. Суды и регуляторы при рассмотрении споров всегда обращают внимание на то, как именно вел себя ответчик. Демонстрировал ли он уважение к чужой собственности и инфраструктуре или действовал агрессивно и пренебрежительно? Показать себя «хорошим», ответственным ботом — это лучшая стратегия для предотвращения конфликтов и сильнейший аргумент в вашу пользу, если конфликт все же произойдет.
Файл robots.txt: джентльменское соглашение, которое нельзя игнорировать
В корневой директории большинства сайтов можно найти небольшой текстовый файл с именем robots.txt. Это так называемый «Стандарт исключений для роботов» — набор инструкций от владельца сайта для поисковых систем и других автоматизированных программ (ботов).31 В этом файле владелец может указать, какие страницы или разделы сайта он не хотел бы, чтобы боты посещали (директива
Disallow), а также может порекомендовать желаемую задержку между запросами (Crawl-delay).
С юридической точки зрения важно понимать: файл robots.txt не имеет силы закона. В России нет нормативного акта, который бы устанавливал ответственность за нарушение инструкций из этого файла. Это не более чем рекомендации, своего рода «джентльменское соглашение» между веб-мастерами и операторами ботов.33
Однако игнорирование robots.txt имеет огромное косвенное юридическое значение. Если дело дойдет до суда по обвинению, например, в злоупотреблении правом (ст. 10 ГК РФ), и истец докажет, что вы целенаправленно парсили раздел, закрытый в robots.txt директивой Disallow: /private/, это будет мощнейшим доказательством вашей недобросовестности. Вы не сможете утверждать, что действовали в неведении или без злого умысла. Вы видели знак «проход запрещен», но сознательно его проигнорировали.
Практические выводы:
- Всегда соблюдайте robots.txt. Это правило номер один для любого этичного парсинга. Проверка и учет правил из этого файла должны быть первым шагом перед запуском любого краулера.
- Используйте robots.txt как источник информации. Иногда в этом файле можно найти ссылку на карту сайта (Sitemap), что облегчит вам задачу по обнаружению нужных страниц.
User-Agent: почему важно правильно представляться
Каждый раз, когда ваш браузер или парсер отправляет запрос к сайту, он включает в него специальный HTTP-заголовок под названием User-Agent. Это строка, которая идентифицирует программу-клиент, ее версию, операционную систему и т.д..34 Например,
User-Agent браузера Chrome на Windows может выглядеть так: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36.
Многие библиотеки для парсинга, например, популярный фреймворк Scrapy, по умолчанию используют User-Agent, который прямо указывает на то, что это бот: Scrapy/2.7.1 (+https://scrapy.org).36 Для систем защиты сайта это как красная тряпка для быка. Такой трафик легко идентифицировать и заблокировать.
Поэтому многие прибегают к маскировке: используют User-Agent’ы реальных браузеров и периодически их меняют (ротируют). Это эффективный способ избежать простейших блокировок. Однако существует еще более правильный и этичный подход. «Золотой стандарт» этичного парсинга — это создание собственного, уникального User-Agent, который идентифицирует вашу компанию и цель сбора данных, а также предоставляет контактную информацию. Например:
MySuperAnalyticCompany-PriceMonitor/1.0 (+http://www.mysuperanalytic.com/bot)
Почему это так важно?
- Прозрачность. Вы не скрываетесь. Вы честно говорите, кто вы и зачем пришли.
- Деэскалация конфликтов. Если администратор сайта заметит подозрительную активность, он сможет перейти по ссылке, понять, что это не злоумышленник, а коммерческий парсер, и, при необходимости, связаться с вами для решения проблемы. Это превращает потенциальный конфликт (блокировка, жалоба) в конструктивный диалог.
- Демонстрация добросовестности. В случае гипотетического судебного разбирательства такой User-Agent будет еще одним весомым доказательством того, что вы действовали открыто и не имели намерения причинить вред.
Практические выводы:
- Никогда не используйте User-Agent по умолчанию из библиотек для парсинга.
- Если ваша цель — долгосрочный и стабильный мониторинг, рассмотрите создание собственного идентифицирующего User-Agent. Это признак профессионализма.
- Если вы все же используете User-Agent’ы реальных браузеров, обеспечьте их регулярную ротацию и используйте актуальные версии.
Скорость парсинга (Rate Limiting): уважение к чужой инфраструктуре
Это самый критический технический аспект, напрямую связанный с риском быть обвиненным в DDoS-атаке (ст. 272 УК РФ). Сайт-источник — это чужая собственность, чужая инфраструктура, которая имеет ограниченные ресурсы (пропускная способность канала, мощность процессора, объем памяти).38 Ваша задача — собрать нужные данные, оказав на эту инфраструктуру минимально возможное, практически незаметное влияние.
Это достигается с помощью грамотного управления скоростью запросов (rate limiting). Основные принципы:
- Устанавливайте задержки между запросами (download delay). Не пытайтесь скачать весь сайт за 5 минут. Установите разумную паузу между запросами, например, несколько секунд. Начинайте с консервативных значений (например, задержка 5-10 секунд) и постепенно оптимизируйте, наблюдая за реакцией сервера.38
- Ограничивайте количество одновременных запросов (concurrency). Не запускайте 100 потоков парсинга одновременно с одного IP-адреса. Для большинства задач достаточно 1-2 одновременных запросов.
- Используйте адаптивную скорость. Современные фреймворки, такие как Scrapy, имеют встроенный механизм AutoThrottle.38 Он автоматически регулирует скорость парсинга в зависимости от текущей загрузки и времени ответа сервера. Если сайт начинает отвечать медленнее, парсер автоматически увеличивает задержки. Это самый умный и уважительный подход.
- Распределяйте нагрузку. Если вам нужно собирать большой объем данных, используйте пул прокси-серверов. Это позволит распределить запросы по разным IP-адресам, снижая нагрузку с каждой отдельной точки и уменьшая вероятность блокировки.
- Парсите в «тихие» часы. По возможности, планируйте запуск самых интенсивных задач на ночное время или выходные дни, когда нагрузка на сайт со стороны реальных пользователей минимальна.
Соблюдение этих технических правил — это не просто хороший тон. Это ваша главная защита от самых серьезных обвинений. Если вы можете доказать (например, логами вашего парсера), что вы предпринимали все необходимые меры для снижения нагрузки на сервер, обвинить вас в «блокировании» работы сайта будет практически невозможно.
Для удобства сведем эти рекомендации в простой чек-лист.
Таблица 2: Чек-лист технически грамотного парсинга
| Что делать (✅) | Чего не делать (❌) |
| Всегда проверять и соблюдать правила в файле robots.txt. Это первый и самый важный шаг. | Игнорировать robots.txt. Это прямой путь к блокировке и демонстрация недобросовестности. |
| Использовать уникальный User-Agent, который идентифицирует вашу компанию или цель парсинга. Это создает прозрачность и доверие. | Использовать стандартный User-Agent из библиотеки парсинга (например, ‘Scrapy’). Вас немедленно вычислят и заблокируют. |
| Настроить динамическую задержку между запросами (AutoThrottle), чтобы не перегружать сервер. Парсер должен сам замедляться, если сайт «устает». | Отправлять сотни запросов в секунду с одного IP-адреса. Это прямой путь к обвинению в DDoS-атаке. |
| Ограничивать количество одновременных запросов к одному домену. Начинайте с одного запроса за раз. | Парсить сайт в 100 потоков. Это гарантированный способ «положить» чужой сервер и получить серьезные проблемы. |
| Распределять запросы через пул качественных прокси-серверов, если объем данных большой. | Использовать бесплатные, «грязные» прокси. Они часто находятся в черных списках и могут навредить вашей репутации. |
| Обрабатывать коды ответа сервера. Если сайт отвечает ошибкой 429 (Too Many Requests) или 503 (Service Unavailable), ваш парсер должен остановиться и подождать. | Игнорировать ошибки сервера и продолжать отправлять запросы. Это агрессивное и вредоносное поведение. |
Раздел 6. Судебная практика и кейсы: чему нас учат реальные споры
Теория и анализ законов — это важно, но для бизнеса всегда главный вопрос: а как это работает на практике? Были ли реальные судебные дела? Какие решения принимали суды? Изучение судебной практики позволяет понять, на какие аспекты правоприменители обращают внимание в первую очередь.
Анализ принципов из знаковых дел (например, дело «ВКонтакте» против Double)
Одним из самых известных и показательных дел в России, связанных со сбором данных, является спор между социальной сетью «ВКонтакте» и компанией «Дабл». Хотя это дело касалось не парсинга цен, а сбора данных пользователей для оценки кредитоспособности, выводы суда установили несколько важнейших принципов, применимых к любому виду сбора данных.
Компания «Дабл» создала сервис, который собирал общедоступную информацию из профилей пользователей «ВКонтакте» (имя, возраст, место учебы, друзья и т.д.) и на основе этих данных формировал отчеты для банков и микрофинансовых организаций. «ВКонтакте» подала в суд, обвинив «Дабл» в нарушении правил пользования сайтом (которые запрещали автоматизированный сбор данных) и в нарушении своих прав на базу данных.
Суды нескольких инстанций поддержали позицию «ВКонтакте». Ключевыми аргументами, на которые опирался суд, были:
- Нарушение условий договора присоединения. Суд признал, что правила пользования сайтом являются договором присоединения, и «Дабл», создавая аккаунты для доступа к данным, согласилась с этими правилами, а затем нарушила их.
- Нарушение прав на базу данных. Суд счел, что совокупность профилей пользователей «ВКонтакте» представляет собой базу данных, в создание и поддержание которой соцсеть вложила значительные средства. «Дабл» извлекала и использовала существенную часть этой базы данных, что является нарушением смежных прав изготовителя (ст. 1334 ГК РФ).
- Создание «паразитического» бизнеса. Суд обратил внимание на то, что «Дабл» не просто анализировала данные для себя, а создала коммерческий продукт, который полностью основывался на данных, сгенерированных инфраструктурой и пользователями «ВКонтакте». Это было расценено как форма недобросовестной конкуренции.
Какие выводы мы можем сделать из этого дела?
- Суды серьезно относятся к нарушению прав на инвестиционные базы данных. Если вы извлекаете существенную часть каталога, в который были вложены большие деньги, риск проиграть суд очень высок.
- Ключевое значение имеет цель использования данных. Риски многократно возрастают, если вы не просто проводите внутренний анализ, а начинаете перепродавать собранные данные или строите на их основе публичный сервис, напрямую конкурирующий с источником.
- Нарушение пользовательского соглашения само по себе может и не быть решающим фактором, но в совокупности с нарушением прав на базу данных и недобросовестной конкуренцией оно становится весомым аргументом против парсера.
Почему нет громких дел о парсинге цен в интернет-магазинах?
На фоне дела «ВКонтакте» возникает резонный вопрос: а почему мы не слышим о судебных исках между крупными ритейлерами из-за мониторинга цен? Ведь все они прекрасно знают, что конкуренты постоянно парсят их сайты. Причин этому несколько, и они носят скорее экономический и прагматический, чем юридический характер.
- Сложность доказывания убытков. Это ключевая причина. Чтобы выиграть суд, истцу нужно доказать не только факт парсинга, но и наличие конкретных, исчисляемых убытков, возникших именно из-за этого. Как доказать, что вы потеряли 100 000 рублей, потому что конкурент вовремя снизил цену на пылесос, узнав вашу цену через парсер? Это практически невозможно. Конкурент всегда может сказать, что узнал цену, просто зайдя на сайт как обычный покупатель.
- Всеобщая практика («все парсят всех»). В конкурентных нишах (электроника, бытовая техника, автозапчасти, fashion) мониторинг цен конкурентов — это стандартная и необходимая часть работы. Крупные игроки понимают, что если они подадут в суд на конкурента, то завтра получат симметричный иск в ответ. Это приведет к «ядерной зиме» — дорогим и бессмысленным судебным тяжбам, которые не выгодны никому. Проще молча продолжать собирать данные друг у друга.
- Технические решения дешевле и эффективнее юридических. Вместо того чтобы тратить миллионы рублей на юристов с непредсказуемым результатом, гораздо проще и дешевле вложить 100-200 тысяч рублей в хорошую систему защиты от ботов. Технические средства (CAPTCHA, анализ поведенческих факторов, блокировка IP-адресов) позволяют эффективно бороться с нежелательными парсерами без привлечения судов. Бизнес предпочитает решать техническую проблему техническими методами.
Отсутствие громких дел не означает, что рисков нет. Оно означает, что рынок нашел определенное равновесие. Конфликты в основном происходят в технической плоскости (соревнование парсеров и систем защиты), а до суда доходят только самые вопиющие случаи — например, когда парсинг привел к падению сайта или когда одна компания полностью скопировала весь контент другой.
Успешный кейс (гипотетический, но основанный на практике)
Чтобы сделать все вышесказанное более наглядным, рассмотрим пример успешного и безопасного проекта по парсингу, основанный на реальной практике.
Задача: Компания «Ритейл-Плюс», крупный онлайн-продавец бытовой техники, столкнулась с проблемой. Конкуренты постоянно меняли цены, и ручной мониторинг не позволял оперативно реагировать. Было принято решение внедрить систему динамического ценообразования, для которой требовался ежедневный сбор данных о ценах и наличии товаров у 5 ключевых конкурентов.
Реализация: Вместо того чтобы просто заказать «парсер всего», компания подошла к задаче комплексно, следуя принципам безопасного сбора данных.
- Юридический аудит (Шаг 1). Перед началом работы был проведен анализ пользовательских соглашений и файлов robots.txt сайтов-конкурентов. Было установлено, что у всех есть стандартный запрет на парсинг. Также было выявлено, что каталоги всех конкурентов подпадают под защиту как инвестиционные базы данных (более 10 000 товаров). Это определило ключевое ограничение: собирать можно только факты, но не контент.
- Техническая настройка (Шаг 2). Был разработан парсер со следующими настройками:
- User-Agent: Использовался кастомный User-Agent RetailPlus-PriceAnalytics/2.0 (+http://retailplus.ru/datapolicy), который четко идентифицировал компанию и давал ссылку на страницу с политикой сбора данных.
- Соблюдение robots.txt: Парсер был настроен на полное соблюдение всех директив Disallow.
- Контроль скорости: Была включена адаптивная регулировка скорости (AutoThrottle) с очень консервативными начальными настройками. Максимальное количество одновременных запросов к одному сайту было ограничено до двух.
- Распределение нагрузки: Использовался пул из 10 качественных серверных прокси-адресов для распределения запросов.
- Фокус на данных (Шаг 3). Техническое задание для парсера было сформулировано максимально узко: со страниц товаров извлекать только 4 поля: наименование товара, артикул (SKU), текущая цена, статус наличия («в наличии» / «нет в наличии»). Сбор описаний, характеристик, фотографий и отзывов был категорически запрещен.
- Использование данных (Шаг 4). Собранные данные поступали во внутреннюю аналитическую систему компании. Они использовались исключительно для алгоритмов ценообразования и для отчетов отдела маркетинга. Никакая часть собранной информации никогда не публиковалась на сайте «Ритейл-Плюс».
Результат: За два года ежедневной работы системы «Ритейл-Плюс» получила стабильный поток данных, который позволил увеличить маржинальность на 7% и оборот на 12%. За все это время компания не получила ни одной блокировки, ни одной жалобы и ни одного письма от юридических служб конкурентов. Прозрачный и уважительный подход к сбору данных позволил получить необходимую рыночную информацию, полностью избежав юридических и технических конфликтов.
Этот кейс наглядно демонстрирует, что при правильном, профессиональном подходе парсинг является абсолютно законным, безопасным и высокоэффективным бизнес-инструментом.
Раздел 7. Чек-лист: как безопасно заказать или внедрить парсинг
Этот раздел представляет собой практическое руководство для менеджеров, маркетологов и владельцев бизнеса. Используйте этот чек-лист, когда вы планируете запустить проект по сбору данных внутри компании или при выборе внешнего подрядчика. Правильные вопросы на старте помогут избежать 99% потенциальных проблем в будущем.
Юридическая проверка (что нужно сделать до старта)
- [ ] Определить точный перечень данных для сбора.
- Составьте исчерпывающий список полей, которые вам нужны (например: артикул, цена со скидкой, цена без скидки, статус наличия, URL страницы). Чем короче и конкретнее этот список, тем безопаснее.
- [ ] Проверить данные на наличие персональных данных (ПДн).
- Убедитесь, что в ваш список не попали поля, которые могут содержать ПДн (например, имена в отзывах, ФИО продавцов, контактные данные). Если есть хоть малейший риск — исключите эти поля.
- [ ] Проверить данные на наличие объектов авторского права.
- Убедитесь, что вы не планируете собирать тексты (описания, статьи), фотографии, видео и другие элементы контента. Их сбор и использование — прямой путь к нарушению авторских прав.
- [ ] Проанализировать robots.txt целевых сайтов.
- Проверьте, не запрещают ли владельцы сайтов доступ к нужным вам разделам. Если нужный раздел закрыт директивой Disallow, от его парсинга следует отказаться.
- [ ] Определить цель использования данных.
- Четко зафиксируйте, как вы будете использовать информацию. Только для внутреннего анализа (безопасно)? Или для публикации на своем сайте (высокий риск)? От этого зависит допустимый объем и тип собираемых данных.
Техническая подготовка (вопросы к вашему IT-отделу или подрядчику)
- [ ] Как вы обеспечиваете соблюдение правил из robots.txt?
- Правильный ответ: «Наш парсер автоматически скачивает и анализирует robots.txt перед началом работы и не посещает запрещенные URL».
- [ ] Какую политику по User-Agent вы используете?
- Плохой ответ: «Мы используем User-Agent по умолчанию».
- Хороший ответ: «Мы используем ротацию User-Agent’ов из пула актуальных браузеров».
- Отличный ответ: «Мы можем настроить кастомный User-Agent, который будет идентифицировать вашу компанию, чтобы обеспечить максимальную прозрачность».
- [ ] Как вы контролируете скорость запросов, чтобы не навредить сайту?
- Правильный ответ: «Мы используем комбинацию методов: устанавливаем задержку между запросами, ограничиваем число одновременных потоков и, что самое важное, используем адаптивный механизм (типа AutoThrottle), который сам подстраивает скорость под нагрузку на сервере».
- [ ] Используете ли вы ротацию IP-адресов?
- Правильный ответ: «Да, для крупных проектов мы используем пул качественных серверных или мобильных прокси, чтобы распределить нагрузку и снизить вероятность блокировки».
- [ ] Как парсер обрабатывает ошибки и блокировки?
- Правильный ответ: «При получении кодов ошибок, свидетельствующих о перегрузке (например, 429, 503) или блокировке (CAPTCHA), парсер автоматически останавливается на некоторое время (тайм-аут) и только потом предпринимает новую попытку, возможно, через другой прокси».
Использование данных (правила после сбора)
- [ ] Хранить данные только во внутренних системах.
- Собранная информация должна использоваться в ваших CRM, ERP, BI-системах. Она не должна быть доступна извне.
- [ ] Не копировать структуру каталога конкурента.
- Даже если вы собрали данные о товарах, не воспроизводите на своем сайте такую же логику категорий, фильтров и подборок, как у конкурента. Создавайте свою собственную структуру.
- [ ] Не публиковать собранные данные «как есть».
- Никогда не берите описание товара или его фото с сайта конкурента и не размещайте у себя. Весь контент на вашем сайте должен быть уникальным.
- [ ] Быть готовым к диалогу.
- Если владелец сайта-источника обратился к вам с просьбой прекратить или снизить активность парсинга, отнеситесь к этому серьезно. Часто проще пойти на компромисс, чем на эскалацию конфликта.
Следование этому чек-листу поможет вам выстроить процесс сбора данных максимально безопасно, профессионально и этично, превратив парсинг из источника рисков в мощный инструмент для роста вашего бизнеса.
Раздел 8. FAQ: часто задаваемые вопросы о законности парсинга
Вопрос 1: Так можно или нельзя парсить, если в оферте есть прямой запрет?
Ответ: В большинстве случаев — можно, при условии, что вы делаете это грамотно. Сам по себе запрет в оферте является «договором присоединения», и его условия можно оспорить как «явно обременительные», если они ограничивают ваше законное право на сбор общедоступной фактической информации. Главное — не нарушать другие, более серьезные законы: об авторском праве (особенно на базу данных), о персональных данных и не создавать чрезмерную нагрузку на сайт. Запрет в оферте — это скорее сигнал о том, что владелец сайта не хочет, чтобы его парсили, но это не абсолютный юридический барьер.
Вопрос 2: Что будет, если меня все-таки «поймают» за парсингом?
Ответ: В 99% случаев самое страшное, что произойдет — ваш IP-адрес (или пул IP-адресов) заблокируют. Владельцы сайтов предпочитают решать эту проблему техническими средствами, а не юридическими. Судебные иски — это дорого, долго и сложно, особенно когда нужно доказать реальный ущерб от сбора публичных цен. Иски становятся реальной угрозой только в случаях, когда парсинг сопровождается дополнительными нарушениями: кражей всего контента (фото, описания), сбором персональных данных, созданием сбоев в работе сайта или построением бизнеса-клона.
Вопрос 3: Нужно ли мне получать разрешение у владельца сайта на парсинг?
Ответ: Нет, для сбора общедоступной информации, которая не является объектом авторского права, предварительное разрешение не требуется. Это часть вашего права на свободный поиск и получение информации. Однако, соблюдая «технический этикет» (представляясь через User-Agent, контролируя скорость), вы демонстрируете уважение и минимизируете вероятность конфликта. Это не юридическое требование, а признак профессионального подхода.
Вопрос 4: Могу ли я парсить данные через официальный API, если он есть у сайта?
Ответ: Да, использование официального API (Application Programming Interface) — это самый безопасный, законный и предпочтительный способ получения данных. Когда вы используете API, вы действуете в рамках правил, явно установленных владельцем сервиса. Он сам определяет, какие данные, в каком объеме и с какой частотой вы можете получать. Условия использования API также являются офертой, и их необходимо строго соблюдать, но в этом случае вы получаете гарантированный и легальный канал доступа к информации.
Вопрос 5: Наша компания находится не в России. Распространяются ли на нас российские законы при парсинге российских сайтов?
Ответ: Да, безусловно. Если вы собираете данные с сайта, который ориентирован на российскую аудиторию, работает в российской юрисдикции и, что особенно важно, может содержать персональные данные граждан РФ, вы обязаны соблюдать российское законодательство. В первую очередь это касается Федерального закона № 152-ФЗ «О персональных данных», который имеет экстерриториальное действие. Независимо от местонахождения вашей компании, при обработке данных россиян вы должны следовать его требованиям.
Заключение: парсинг как законный инструмент роста вашего бизнеса
Подводя итог этому детальному разбору, можно с уверенностью сделать главный вывод: парсинг — это не «серая зона» и не сомнительная практика на грани фола. В современном цифровом мире это стандартный и необходимый бизнес-инструмент для сбора рыночной информации, такой же, как анализ отраслевых отчетов или проведение маркетинговых исследований.
Риски, связанные с парсингом, реальны, но они практически никогда не связаны с самим фактом автоматического сбора общедоступных данных. Они возникают из-за непрофессионального подхода:
- Юридической безграмотности, когда компания не видит разницы между фактом (цена) и объектом интеллектуальной собственности (база данных, фото, текст).
- Технической небрежности, когда парсер работает как «слон в посудной лавке», создавая чрезмерную нагрузку и вредя чужой инфраструктуре.
- Неуважения к чужой собственности, когда парсинг используется для кражи контента или создания бизнеса-паразита.
Пункт в пользовательском соглашении, запрещающий парсинг, не должен быть для вас стоп-сигналом. Рассматривайте его как предупреждение: «Мы следим за автоматизированным трафиком и не приветствуем агрессивное поведение».
При правильном, экспертном подходе, который сочетает в себе юридическую осмотрительность, технический этикет и четкое понимание бизнес-целей, парсинг является абсолютно законным, безопасным и чрезвычайно мощным драйвером для принятия верных решений. Он позволяет видеть рынок в реальном времени, оперативно реагировать на действия конкурентов, оптимизировать собственную ценовую и ассортиментную политику и, в конечном счете, выигрывать в конкурентной борьбе.
Задача современного бизнеса — не бояться данных, а научиться работать с ними профессионально. И грамотно выстроенный процесс парсинга — ключевой шаг на этом пути.
Источники
- ГК РФ Статья 435. Оферта — КонсультантПлюс, дата последнего обращения: сентября 29, 2025, https://www.consultant.ru/document/cons_doc_LAW_5142/892c4b89172aef07157d5d6c0e5dcde6e37b3a83/
- Законный парсинг интернет-магазинов в России: исчерпывающее руководство по праву и практике — xmldatafeed.com, дата последнего обращения: сентября 29, 2025, https://xmldatafeed.com/zakonnyj-parsing-internet-magazinov-v-rossii-ischerpyvayushhee-rukovodstvo-po-pravu-i-praktike/
- ГК РФ Статья 428. Договор присоединения — Audit-it.ru, дата последнего обращения: сентября 29, 2025, https://www.audit-it.ru/gk/428.html
- Статья 8. Право на доступ к информации — КонсультантПлюс, дата последнего обращения: сентября 29, 2025, https://www.consultant.ru/document/cons_doc_LAW_61798/78b773a28f3ad19eb234697b20ab1d48c09f748a/
- ГК РФ Статья 421. Свобода договора — КонсультантПлюс, дата последнего обращения: сентября 29, 2025, https://www.consultant.ru/document/cons_doc_LAW_5142/ad08909251f4d26ebc935648e4e708a31e160348/
- Парсинг: законно ли им пользоваться — Altcraft CDP, дата последнего обращения: сентября 29, 2025, https://altcraft.com/ru/glossary/parsing-chto-eto-takoe-i-mogut-li-za-nego-oshtrafovat
- Законно ли парсить сайты в России? Даем правовое основание — xmldatafeed.com, дата последнего обращения: сентября 29, 2025, https://xmldatafeed.com/zakon/
- Парсинг сайтов — законно ли? — Веб-студия Яворского, дата последнего обращения: сентября 29, 2025, https://yavorsky.ru/stati/parsingsaitovzakonno/
- Скрапинг интернет-ресурсов: критерии законности, дата последнего обращения: сентября 29, 2025, https://ipcmagazine.ru/articles/1729240/
- Парсинг данных в России: этические аспекты и законодательство – DP.PRO, дата последнего обращения: сентября 29, 2025, https://dataparsing.pro/dataparsing-blog/parsing-dannyh-v-rossii-eticheskie-aspekty-i-zakonodatelstvo/
- Договор присоединения и оферта — в чем разница — Блог Moscow Digital School, дата последнего обращения: сентября 29, 2025, https://mosdigitals.ru/blog/dogovor-prisoedineniya-i-oferta-v-chem-raznicza
- Оферта или договор присоединения: что выбрать бизнесу и не обжечься? — VC.ru, дата последнего обращения: сентября 29, 2025, https://vc.ru/legal/2059885-oferta-ili-dogovor-prisoedineniya-dlya-biznesa-chto-vybrat
- Договор присоединения — Гражданский кодекс для бухгалтера быстро и легко, дата последнего обращения: сентября 29, 2025, https://e.glavbukh.ru/399250
- Навязанные условия договора: можно ли от них защититься | Статьи компании «РосКо», дата последнего обращения: сентября 29, 2025, https://rosco.su/press/navyazannye-usloviya-dogovora-mozhno-li-ot-nikh-zashchititsya/
- Энциклопедия судебной практики. Договор присоединения (Ст. 428 ГК) | ГАРАНТ, дата последнего обращения: сентября 29, 2025, https://base.garant.ru/57590355/
- Судебная практика по договорам присоединения — Закон и право. Библиотека юриста, дата последнего обращения: сентября 29, 2025, https://legallib.ru/civillaw/sudebnaya-praktika-po-dogovoram-prisoedineniya.html
- ГРАЖДАНСКИЙ КОДЕКС РФ (ГК РФ) Часть 4. N 230-ФЗ. в ред. 2006-2025 г.г. Глава 70 Авторское право. Реклама и право. Реклама в метро. — Реклама на МЦК, дата последнего обращения: сентября 29, 2025, https://metroreklama.ru/pravo/gk-rf/ch-4/230fz_gk_70-1.php
- Базы данных и сервисы онлайн-классифайдов: пользование …, дата последнего обращения: сентября 29, 2025, https://ipcmagazine.ru/articles/1729189/
- Что представляет собой Федеральный закон «О персональных данных» N 152-ФЗ и какая ответственность за его нарушения — RTM Group, дата последнего обращения: сентября 29, 2025, https://rtmtech.ru/articles/152-fz-otvetstvennost/
- Ответственность за нарушение закона о персональных данных — ГАРАНТ, дата последнего обращения: сентября 29, 2025, https://www.garant.ru/actual/persona/otvetstvennost/
- Ответственность за нарушения 152-ФЗ и разглашение персональных данных — Selectel, дата последнего обращения: сентября 29, 2025, https://selectel.ru/blog/responsibility-152-fz/
- Статья 272. Неправомерный доступ к компьютерной информации — Комментарии к УК РФ, дата последнего обращения: сентября 29, 2025, https://ukodeksrf.ru/ch-2/rzd-9/gl-28/st-272-uk-rf
- Адвокат по ст. 272 УК РФ неправомерный доступ к компьютерной информации, дата последнего обращения: сентября 29, 2025, https://advokat-krasnogorsk.ru/uslugi/zachita-po-ugolovnim-delam/computernie-prestupleniya/272-uk-rf/
- УК РФ Статья 272. Неправомерный доступ к компьютерной информации \ КонсультантПлюс, дата последнего обращения: сентября 29, 2025, https://www.consultant.ru/document/cons_doc_LAW_10699/5c337673c261a026c476d578035ce68a0ae86da0/
- Статья 272 УК РФ (последняя редакция с комментариями). Неправомерный доступ к компьютерной информации, дата последнего обращения: сентября 29, 2025, https://www.ugolkod.ru/statya-272
- Преступления в сфере компьютерной информации — ст. 272 УК РФ — RTM Group, дата последнего обращения: сентября 29, 2025, https://rtmtech.ru/articles/prestupleniya-v-sfere-kompyuternoj-informatsii-st-272-uk-rf/
- Применение ст. 10 ГК (злоупотребление правом) | Caselaw, дата последнего обращения: сентября 29, 2025, http://caselaw.today/archives/795
- Статья 10. Пределы осуществления гражданских прав, дата последнего обращения: сентября 29, 2025, https://gkrfkod.ru/statja-10_1/
- ГК РФ Статья 10. Пределы осуществления гражданских прав \ КонсультантПлюс, дата последнего обращения: сентября 29, 2025, https://www.consultant.ru/document/cons_doc_LAW_5142/62129e15ab0e6008725f43d63284aef0bb12c2cf/
- ГК РФ Статья 10. Пределы осуществления гражданских прав — Audit-it.ru, дата последнего обращения: сентября 29, 2025, https://www.audit-it.ru/gk/10.html
- О файлах robots.txt | Центр Google Поиска | Documentation, дата последнего обращения: сентября 29, 2025, https://developers.google.com/search/docs/crawling-indexing/robots/intro?hl=ru
- Как создать, правильно настроить и загрузить на сайт файл robots.txt? — beSeller, дата последнего обращения: сентября 29, 2025, https://beseller.by/blog/robots-txt/
- Парсинг — а это вообще легально и законно? — xmldatafeed.com, дата последнего обращения: сентября 29, 2025, https://xmldatafeed.com/parsing-a-jeto-voobshhe-legalno-i-zakonno/
- Parse a User Agent String — WhatIsMyBrowser Developers, дата последнего обращения: сентября 29, 2025, https://explore.whatismybrowser.com/useragents/parse/
- Parsing User Agent Strings in Big Data — 2025 — Integrate.io, дата последнего обращения: сентября 29, 2025, https://www.integrate.io/blog/parsing-user-agent-strings-in-big-data/
- Scrapy User Agent: How to Change and Tips 2025 — ZenRows, дата последнего обращения: сентября 29, 2025, https://www.zenrows.com/blog/scrapy-user-agent
- Scrapy Beginners Series Part 4 — User Agents and Proxies — ScrapeOps, дата последнего обращения: сентября 29, 2025, https://scrapeops.io/python-scrapy-playbook/scrapy-beginners-guide-user-agents-proxies/
- How do I implement rate limiting in Scrapy? — WebScraping.AI, дата последнего обращения: сентября 29, 2025, https://webscraping.ai/faq/scrapy/how-do-i-implement-rate-limiting-in-scrapy
ПОХОЖИЕ ПУБЛИКАЦИИ:
 Можно ли парсить данные пользователей с Авито, ВКонтакте и других социальных сетей? Парсинг – это совершенно законно, правда? Парсинг — а это вообще легально и законно? Можно ли юридически запретить парсинг сайта?
Можно ли парсить данные пользователей с Авито, ВКонтакте и других социальных сетей? Парсинг – это совершенно законно, правда? Парсинг — а это вообще легально и законно? Можно ли юридически запретить парсинг сайта?  Как собирать отзывы клиентов, которые действительно ценны
Как собирать отзывы клиентов, которые действительно ценны  Законно ли парсить сайты?
Законно ли парсить сайты?  Парсинг цен конкурентов: полное руководство по обходу блокировок и защит
Парсинг цен конкурентов: полное руководство по обходу блокировок и защит  Парсинг контактов клиентов с сайтов ваших конкурентов Законно ли парсить сайты в России? Законно ли заниматься парсингом сайтов в России?
Парсинг контактов клиентов с сайтов ваших конкурентов Законно ли парсить сайты в России? Законно ли заниматься парсингом сайтов в России?
МЕДИЦИНСКИЕ УСЛУГИ
База всех компаний в категории: МЕДИЦИНСКИЕ ЦЕНТРЫ СИМЕД МЕДИЦИНСКИЙ ЦЕНТР
ЭКСПЕРТНЫЕ УСЛУГИ
База всех компаний в категории: УПРАВЛЕНЧЕСКИЙ КОНСАЛТИНГ
НАУЧНАЯ И ТЕХНИЧЕСКАЯ ДЕЯТЕЛЬНОСТЬ
База всех компаний в категории: ОКВЭД 71.12.15 — ИНЖЕНЕРНЫЕ ИЗЫСКАНИЯ В СТРОИТЕЛЬСТВЕ
БЫТОВЫЕ УСЛУГИ
База всех компаний в категории: АВТОМОЙКИ
ГОСТИНИЦЫ И ОБЩЕСТВЕННОЕ ПИТАНИЕ
База всех компаний в категории: ОКВЭД 56.30 — ПОДАЧА НАПИТКОВ
АДМИНИСТРАТИВНАЯ ДЕЯТЕЛЬНОСТЬ И УСЛУГИ
База всех компаний в категории: ОКВЭД 77.39.27 — АРЕНДА И ЛИЗИНГ ТОРГОВОГО ОБОРУДОВАНИЯ
ПРОИЗВОДСТВЕННЫЕ УСЛУГИ
База всех компаний в категории: МЕТАЛЛУРГИЧЕСКАЯ КОМПАНИЯ
БИЗНЕС-УСЛУГИ
База всех компаний в категории: ФРАНЧАЙЗИНГ