













Безопасность в сети,Интернет,Общие вопросы парсинга,Программирование
Защита вашего сайта от парсинга: Полное руководство по лучшим решениям

Июл
Введение: Невидимая война за ваши данные
В цифровой экономике данные — это новая нефть. Ваш веб-сайт, будь то интернет-магазин, новостной портал или SaaS-платформа, является не просто витриной вашего бизнеса, а ценнейшим активом, наполненным уникальным контентом, ценами, пользовательской информацией и коммерческими данными. Ежедневно этот актив подвергается невидимой, но интенсивной осаде. Речь идет о парсинге — автоматизированном процессе сбора и структурирования информации с веб-страниц с помощью специальных программ, известных как парсеры.1 Важно понимать: парсинг — это не взлом. Он не предполагает обхода систем безопасности для получения доступа к закрытой информации. Парсеры работают с теми же данными, которые видит любой обычный посетитель вашего сайта, но делают это в промышленных масштабах, с машинной скоростью и эффективностью.
Эта технология, как и любой мощный инструмент, имеет две стороны. С одной стороны, существуют «хорошие» боты, без которых современный интернет немыслим. Поисковые роботы, такие как Googlebot и YandexBot, парсят ваш сайт, чтобы индексировать его страницы и показывать их в результатах поиска. Сервисы мониторинга цен, на которые вы, возможно, сами подписаны, используют парсинг для предоставления вам актуальной информации. С другой стороны, существует армия «плохих» ботов, чьи цели варьируются от недобросовестной конкуренции до откровенного мошенничества. Это боты ваших конкурентов, которые ежеминутно копируют ваши цены, чтобы предложить скидку на один рубль дешевле. Это агрегаторы контента, которые воруют ваши уникальные статьи и описания товаров, чтобы наполнить свои ресурсы. Это злоумышленники, которые сканируют ваш сайт в поисках уязвимостей, и спамеры, собирающие контактные данные ваших пользователей для своих рассылок.3
Именно поэтому защита от нежелательного парсинга превратилась из технической задачи для узких специалистов в критически важный элемент бизнес-стратегии. Вопрос больше не в том, «парсят ли мой сайт?», а в том, «кто, как часто и с какой целью это делает, и какой ущерб это наносит моему бизнесу?». Эта статья представляет собой исчерпывающее руководство по защите ваших цифровых активов. Мы разберем анатомию угроз, проанализируем сложную правовую базу в России и мире, рассмотрим весь арсенал методов защиты — от базовых настроек сервера до передовых технологий на основе искусственного интеллекта. Мы сравним лучшие коммерческие решения на рынке и, в конечном итоге, поможем вам выстроить многоуровневую стратегию, которая позволит найти разумный баланс между необходимой открытостью вашего сайта для мира и надежной защитой ваших ценных данных.
Часть 1: Анатомия угрозы — почему парсинг может быть опасен?
Многие владельцы сайтов недооценивают риски, связанные с парсингом, полагая, что раз данные общедоступны, их сбор не несет прямого вреда. Это опасное заблуждение. Неконтролируемый автоматизированный сбор данных может нанести серьезный и многогранный ущерб, затрагивающий коммерческие, технические и юридические аспекты бизнеса. Угроза парсинга не является единичной проблемой; она действует как каскадный мультипликатор рисков, где одна, казалось бы, безобидная активность запускает цепную реакцию негативных последствий для разных отделов компании.
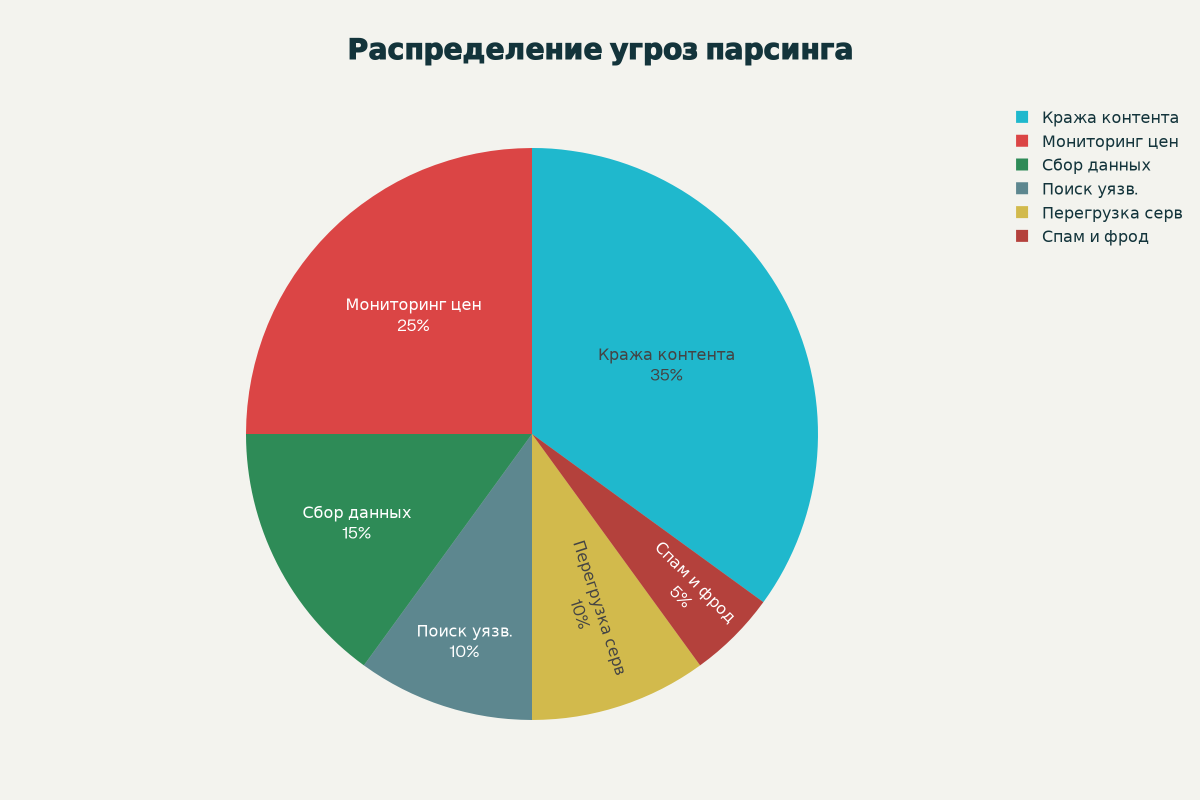
1.1. Прямые бизнес-риски: Утечка конкурентных преимуществ
Это наиболее очевидная и болезненная категория последствий, напрямую влияющая на доходы компании.
- Мониторинг цен (Price Scraping): Для интернет-магазинов это угроза номер один. Конкуренты используют парсеры для автоматического мониторинга ваших цен в режиме реального времени.1 Как только вы снижаете цену на товар или запускаете акцию, их система мгновенно получает уведомление и автоматически корректирует цены на их собственном сайте, чтобы всегда быть на шаг впереди.5 Это приводит к ценовым войнам, снижению маржинальности и потере клиентов, которые видят у конкурента более выгодное предложение.3
- Кража контента и интеллектуальной собственности: Уникальный контент — это результат значительных инвестиций времени и денег. Парсеры могут за считанные часы скопировать тысячи уникальных описаний товаров, экспертных статей, аналитических обзоров и пользовательских отзывов для наполнения сайтов-конкурентов или создания сеток сателлитов.2 Это не только обесценивает ваши усилия, но и является прямым нарушением ваших авторских прав, что может привести к потере уникальности вашего контента в глазах поисковых систем.5
- Анализ ассортимента и бизнес-стратегии: Парсеры собирают не только цены и описания. Они анализируют весь ваш каталог: какие товары появляются как новинки, какие уходят со склада (анализ товарных остатков), какие акции и сезонные предложения вы запускаете.1 Эта информация позволяет конкурентам копировать вашу маркетинговую и ассортиментную стратегию, лишая вас конкурентного преимущества, основанного на аналитике и планировании.2
1.2. Технические и операционные риски: Удар по инфраструктуре и SEO
Даже если вас не волнует конкурентная разведка, агрессивный парсинг наносит прямой технический ущерб, который ложится на плечи IT-отдела и SEO-специалистов.
- Перегрузка сервера: Парсеры, в отличие от людей, могут отправлять сотни запросов в минуту. Массовый и агрессивный парсинг создает колоссальную нагрузку на серверную инфраструктуру. Это может замедлить скорость загрузки сайта для реальных пользователей, а в худшем случае — привести к его полной недоступности, что по сути является разновидностью DDoS-атаки (Denial of Service).5 В результате вы несете расходы на более мощное «железо» и теряете клиентов из-за медленной работы сайта.
- Негативное влияние на SEO:
- Кража и дублирование контента: Когда ваш контент массово копируется и размещается на других ресурсах, поисковые системы, такие как Яндекс и Google, сталкиваются с проблемой дублированного контента. Они могут ошибочно посчитать первоисточником не ваш сайт, а сайт-плагиатор, что приведет к пессимизации ваших страниц в поисковой выдаче.5
- «Сжигание» краулингового бюджета: Поисковые системы выделяют каждому сайту определенный лимит на количество страниц, которые их робот обойдет за определенное время (краулинговый бюджет). «Плохие» боты, хаотично сканируя ваш сайт, тратят этот ценный ресурс. В итоге поисковый робот может не успеть дойти до ваших новых или важных страниц, и они не попадут в поисковый индекс.8
- Искажение поведенческих факторов: Поисковые системы анализируют, как пользователи ведут себя на сайте (время на сайте, глубина просмотра, показатель отказов). Массовый трафик от ботов, которые заходят на страницу и тут же уходят, создает крайне негативную статистику. Алгоритмы могут интерпретировать это как сигнал о низком качестве или нерелевантности вашего ресурса, что также негативно скажется на ранжировании.9
1.3. Риски безопасности и комплаенса
Парсинг часто является первым шагом для более серьезных атак и может создавать юридические проблемы, связанные с обработкой данных.
- Поиск уязвимостей: Злоумышленники используют парсеры для автоматического сканирования сайта на предмет устаревшего ПО, открытых портов и других технических ошибок, которые можно использовать для взлома, внедрения вредоносного кода или кражи данных.5
- Сбор персональных данных: Парсеры могут целенаправленно собирать с вашего сайта любую общедоступную контактную информацию: email-адреса из комментариев, номера телефонов со страниц контактов, профили пользователей. Эти данные затем используются для спам-рассылок, фишинговых атак или продаются на черном рынке.2 Такой сбор является прямым нарушением законодательства о персональных данных, например, российского ФЗ-152 или европейского GDPR, и может повлечь за собой крупные штрафы.7
1.4. Классификация по OWASP: Взгляд через призму мировых стандартов
Чтобы систематизировать эти угрозы, обратимся к авторитетной международной организации OWASP (Open Web Application Security Project). В рамках проекта «Automated Threats to Web Applications» (Автоматизированные угрозы для веб-приложений) был составлен список типовых атак, выполняемых ботами. Парсинг и связанные с ним активности занимают в нем центральное место.10
Даже «условно легальный» парсинг, например, сбор общедоступных цен, может быть таким же разрушительным для бизнеса, как и откровенно вредоносные действия. Законы в основном регулируют вопросы авторского права и персональных данных, но ценовые войны, которые подрывают вашу экономику, часто лежат в «серой зоне».4 Это означает, что полагаться исключительно на юридическую защиту — недальновидно. Технические средства защиты становятся не просто опцией, а фундаментальной необходимостью для выживания и сохранения конкурентоспособности в цифровой среде.
Таблица 1: Классификация угроз парсинга по OWASP и их бизнес-последствия
| Идентификатор OWASP | Название угрозы | Описание действия бота | Пример бизнес-ущерба |
| OAT-011 Scraping | Парсинг (Скрейпинг) | Массовый сбор любой информации с веб-сайта: контент, цены, контактные данные, структура. | Потеря конкурентного преимущества, снижение SEO-позиций из-за дублирования контента, нарушение авторских прав.13 |
| OAT-018 Footprinting | Снятие карты сайта | Систематический обход всех страниц и ссылок для составления полной карты ресурса и его структуры. | Подготовка к более сложным атакам, выявление скрытых или тестовых разделов, анализ бизнес-логики приложения.10 |
| OAT-004 Fingerprinting | Снятие отпечатков | Отправка специфических запросов для определения версий ПО, фреймворков и технологий, используемых на сайте. | Обнаружение известных уязвимостей в используемом ПО для последующей целенаправленной атаки.10 |
| OAT-008 Credential Stuffing | Подстановка учетных данных | Массовые попытки входа в аккаунты пользователей с использованием баз украденных логинов и паролей с других сайтов. | Взлом аккаунтов пользователей, репутационный ущерб, финансовые потери клиентов, блокировка легитимных пользователей.10 |
| OAT-019 Account Creation | Создание аккаунтов | Автоматическая регистрация большого количества поддельных аккаунтов. | Спам, накрутка отзывов и рейтингов, злоупотребление бонусами за регистрацию, размывание пользовательской базы.10 |
| OAT-001 Carding | Кардинг | Автоматизированная проверка валидности списков украденных данных банковских карт путем совершения микротранзакций. | Финансовые потери из-за комиссий за отклоненные транзакции, репутационный ущерб, попадание в черные списки платежных систем.13 |
Часть 2: Правовое поле — что говорит закон о парсинге в России и мире?
Вопрос законности парсинга сложен и многогранен. Не существует единого международного закона, который бы четко отвечал «да» или «нет». Легальность зависит от того, что парсят, как парсят и для чего используют собранные данные. Для принятия взвешенного решения о защите необходимо понимать ключевые юридические аспекты и прецеденты. При этом важно осознавать, что правовая защита — это своего рода «бумажный щит», который становится эффективным только при поддержке технического «меча». Без технических средств для обнаружения и идентификации нарушителя юридические нормы остаются лишь теорией, ведь невозможно подать в суд на анонимного бота.
2.1. Громкое дело: LinkedIn против hiQ Labs — прецедент, изменивший правила игры
Это судебное разбирательство в США стало, пожалуй, самым важным событием, сформировавшим современное понимание законности парсинга.15
- Контекст дела: Аналитическая компания hiQ Labs занималась парсингом публичных профилей пользователей социальной сети LinkedIn для создания HR-продуктов — например, предсказывала, какие сотрудники могут скоро уволиться.12 LinkedIn отправила hiQ требование прекратить эту деятельность, ссылаясь на американский закон «О компьютерном мошенничестве и злоупотреблениях» (CFAA), по сути, обвиняя hiQ во взломе.15
- Ключевые решения суда: Судебный процесс прошел несколько инстанций, и его выводы имеют огромное значение:
- Парсинг публичных данных — не взлом: Суд постановил, что сбор информации, которая находится в открытом доступе и не требует для просмотра аутентификации (ввода логина и пароля), не является «неавторизованным доступом» и не нарушает закон CFAA.12 Это был серьезный удар по позициям крупных платформ, которые пытались приравнять любой парсинг к хакерской атаке.
- Пользовательское соглашение (Terms of Service) имеет силу: Несмотря на первый вывод, в конечном итоге суд встал на сторону LinkedIn по другому основанию. Он признал, что hiQ, создавая аккаунты для своей деятельности, согласилась с Пользовательским соглашением LinkedIn, которое прямо запрещало использование автоматизированных скриптов и парсинг. Таким образом, hiQ нарушила не уголовный закон, а договорные обязательства перед LinkedIn.12
Этот прецедент показал, что главным юридическим инструментом защиты от парсинга является грамотно составленное Пользовательское соглашение.
2.2. Российское законодательство: на что можно опереться?
В России нет отдельного закона «о парсинге», но эта деятельность регулируется несколькими статьями Гражданского и Уголовного кодексов.
- Авторское право (ГК РФ, ст. 1274): Тексты, фотографии, видео и другой контент на вашем сайте являются объектами авторского права. Их копирование и использование без разрешения автора (владельца сайта) является плагиатом и прямым нарушением закона.20 Это наиболее сильный аргумент против парсинга контента.
- Права на базу данных (ГК РФ): Если ваш сайт представляет собой структурированную совокупность данных (например, каталог товаров, база объявлений, справочник), он может быть признан базой данных. Закон защищает права изготовителя такой базы. Извлечение и последующее использование существенной части ее содержимого является нарушением смежных прав.22 За такое нарушение предусмотрена денежная компенсация в размере до 5 миллионов рублей.
- Неправомерный доступ и DDoS (УК РФ, ст. 272): Если парсинг осуществляется настолько агрессивно, что это приводит к нарушению работы сайта, перегрузке серверов и их недоступности для легитимных пользователей, такие действия могут быть квалифицированы как неправомерный доступ к компьютерной информации или как разновидность DDoS-атаки. Это уже уголовное преступление, за которое предусмотрены серьезные штрафы и даже лишение свободы.7
- ФЗ-152 «О персональных данных»: Сбор, хранение и любая обработка персональных данных граждан РФ (ФИО, email, телефон, адрес и т.д.) без их явного и информированного согласия запрещены. Парсинг таких данных с сайта является нарушением закона. Штрафы для юридических лиц могут быть весьма значительными.7 Важно понимать, что даже если пользователь сам опубликовал свои данные (например, в профиле на форуме), это не означает автоматического согласия на их сбор в коммерческую базу данных для рассылок.
2.3. Международные нормы: GDPR и CCPA
Если ваш сайт ориентирован на международную аудиторию, особенно на пользователей из Европейского союза или Калифорнии (США), вы обязаны соблюдать местные законы о защите данных.
- GDPR (Общий регламент по защите данных, ЕС): Это один из самых строгих законов о приватности в мире.
- Что такое персональные данные? GDPR трактует это понятие очень широко. К персональным данным относится любая информация, которая прямо или косвенно идентифицирует физическое лицо. Это не только имя и email, но и IP-адрес, данные о местоположении, cookie-файлы и другие онлайн-идентификаторы.23
- Обязательства: Для сбора и обработки таких данных у вас должно быть законное основание. Чаще всего это — явное, недвусмысленное согласие пользователя. Вы не можете просто парсить email-адреса для создания базы лидов без разрешения их владельцев.25
- Права пользователей: GDPR наделяет пользователей широкими правами, включая «право на забвение» (требование удалить все свои данные), право на доступ к своим данным и право на их исправление.23
- CCPA (Калифорнийский закон о защите прав потребителей): Во многом схож с GDPR, но имеет свои особенности.
- Ключевые права: CCPA предоставляет жителям Калифорнии право знать, какие данные о них собираются, право требовать их удаления, и, что особенно важно, право на отказ от продажи или передачи своей личной информации. Сайты, подпадающие под действие CCPA, обязаны размещать на видном месте ссылку «Do Not Sell or Share My Personal Information».23
Публикация данных в открытом доступе не означает автоматического разрешения на их любое использование. Существует фундаментальное различие между «правом на просмотр» для человека и «правом на массовое извлечение и коммерческое использование» для машины. Технические средства защиты как раз и служат инструментом для принудительного соблюдения этой разницы.
Таблица 2: Сравнение ключевых требований GDPR и CCPA для владельцев сайтов
| Аспект регулирования | GDPR (Европейский союз) | CCPA (Калифорния, США) |
| Территория действия | Применяется, если обрабатываются данные резидентов ЕС, независимо от местонахождения компании. | Применяется к компаниям, ведущим бизнес в Калифорнии и соответствующим определенным критериям (например, годовой доход > $25 млн).27 |
| Определение персональных данных | Любая информация, относящаяся к идентифицированному или идентифицируемому физлицу (включая IP, cookie).23 | Любая информация, которая идентифицирует, относится, описывает или может быть связана с конкретным потребителем или домохозяйством.23 |
| Ключевые права пользователей | Право на доступ, исправление, удаление («право на забвение»), ограничение обработки, возражение против обработки.23 | Право знать, удалять, исправлять, ограничивать использование и отказываться от продажи/передачи персональной информации.27 |
| Требования к согласию | Требуется явное, информированное согласие на обработку данных (opt-in). Молчание или бездействие не являются согласием.25 | Работает по принципу opt-out. Данные можно собирать по умолчанию, но пользователь должен иметь простую возможность отказаться от их продажи/передачи.23 |
| Обязательные уведомления на сайте | Подробная Политика конфиденциальности. Уведомления об использовании cookie. | Политика конфиденциальности. Ссылка «Do Not Sell or Share My Personal Information» на главной странице.23 |
2.4. Юридическая линия обороны: Пользовательское соглашение (Terms of Service)
Как показало дело LinkedIn vs hiQ, грамотно составленное Пользовательское соглашение (или Условия использования) — это ваш главный юридический инструмент.
- Что включить: В документе необходимо явно и недвусмысленно прописать запрет на использование любых автоматизированных средств (роботов, пауков, парсеров, скрейперов) для доступа к сайту и сбора информации без предварительного письменного согласия администрации.25
- Как обеспечить принятие: Недостаточно просто разместить ссылку на документ в футере сайта. Для максимальной юридической силы необходимо, чтобы пользователь явно подтвердил свое согласие с условиями, например, поставив галочку в чекбоксе при регистрации с текстом «Я принимаю Условия использования».
Таким образом, даже если парсинг публичных данных сам по себе не нарушает уголовный закон, он будет являться нарушением заключенного с вами договора, что дает вам полное право требовать прекращения этих действий и обращаться в суд за защитой своих прав.
Часть 3: Фундаментальная защита — базовые методы на уровне сервера
Прежде чем переходить к сложным и дорогим технологиям, необходимо выстроить первый, базовый эшелон обороны. Эти методы реализуются непосредственно на уровне веб-сервера, часто не требуют значительных финансовых вложений и способны отсечь самых простых и «ленивых» ботов. Важно понимать, что это необходимый, но недостаточный «гигиенический минимум». Любой серьезный коммерческий парсер изначально проектируется для обхода этих мер, однако их внедрение заставляет злоумышленника применять более сложные инструменты и снижает общий «шум» от неквалифицированных ботов.
3.1. Файл robots.txt: Джентльменское соглашение
- Принцип работы: robots.txt — это простой текстовый файл, который размещается в корневой директории вашего сайта (например, your-site.com/robots.txt). Он содержит набор инструкций-рекомендаций для роботов, в первую очередь для поисковых систем, о том, какие разделы или страницы сайта не следует посещать и индексировать.29
- Ограничения: Ключевое слово здесь — «рекомендации». robots.txt основан на добровольном соблюдении правил. Все «хорошие» боты, такие как Googlebot и YandexBot, строго следуют этим инструкциям. Однако «плохие» боты и коммерческие парсеры, чья цель — сбор данных вопреки вашему желанию, просто игнорируют этот файл.7 Поэтому
robots.txt нельзя считать реальным средством защиты, это скорее способ управления индексацией для поисковиков. - Примеры конфигурации:
- Запретить всем ботам доступ ко всему сайту (используется для тестовых сайтов):
User-agent: *
Disallow: / - Запретить всем ботам доступ к определенным папкам (например, административной панели и личным кабинетам):
User-agent: *
Disallow: /admin/
Disallow: /private/ - Запретить доступ конкретному «плохому» боту (например, AhrefsBot, если вы не хотите, чтобы SEO-сервисы анализировали ваш сайт):
User-agent: AhrefsBot
Disallow: /
3.2. Ограничение частоты запросов (Rate Limiting): «Протекающее ведро»
Это один из самых эффективных базовых методов защиты от агрессивного парсинга.
- Концепция: Rate Limiting ограничивает количество запросов, которое один и тот же клиент (обычно идентифицируемый по IP-адресу) может сделать к вашему серверу за определенный промежуток времени. Например, можно установить лимит в 60 запросов в минуту.33 Если клиент превышает этот лимит, его последующие запросы либо замедляются, либо блокируются с ошибкой (чаще всего 429 Too Many Requests или 503 Service Unavailable).35 Для наглядности этот механизм часто сравнивают с «протекающим ведром» (leaky bucket): запросы наполняют ведро, а оно «протекает» с заданной скоростью. Если запросы поступают слишком быстро, ведро переполняется, и новые запросы отбрасываются.
- Практическая реализация на Nginx: Nginx предоставляет мощные и гибкие инструменты для настройки Rate Limiting.
- Определение зоны: Сначала в секции http конфигурационного файла Nginx создается зона в разделяемой памяти, где будут храниться состояния IP-адресов.
Nginx# /etc/nginx/nginx.conf
http {
...
limit_req_zone $binary_remote_addr zone=mylimit:10m rate=10r/s;
...
}
Здесь $binary_remote_addr — это IP-адрес клиента в бинарном формате (экономит память), zone=mylimit:10m — название зоны mylimit и ее размер 10 мегабайт (хватит примерно на 160,000 IP-адресов), rate=10r/s — максимальная средняя скорость 10 запросов в секунду.35 - Применение ограничения: Затем в секции server или location это ограничение применяется к нужным ресурсам.
Nginx# /etc/nginx/sites-available/default
server {
...
location /catalog/ {
limit_req zone=mylimit burst=20 nodelay;
#... другие настройки
}
...
}
Здесь limit_req zone=mylimit применяет ранее созданную зону. burst=20 позволяет клиенту кратковременно превысить лимит на 20 запросов (они будут поставлены в очередь и обработаны с задержкой), что сглаживает пики активности от реальных пользователей. nodelay указывает Nginx обрабатывать запросы из burst без задержки, а блокировать только те, что превышают rate + burst.33
При всей своей эффективности, Rate Limiting требует осторожной настройки. Слишком жесткие лимиты могут заблокировать легитимных пользователей, работающих из одной корпоративной сети (за одним NAT), или даже поисковых роботов, что негативно скажется на SEO. Поэтому перед включением блокировки рекомендуется сначала анализировать логи, чтобы подобрать оптимальные значения rate и burst.
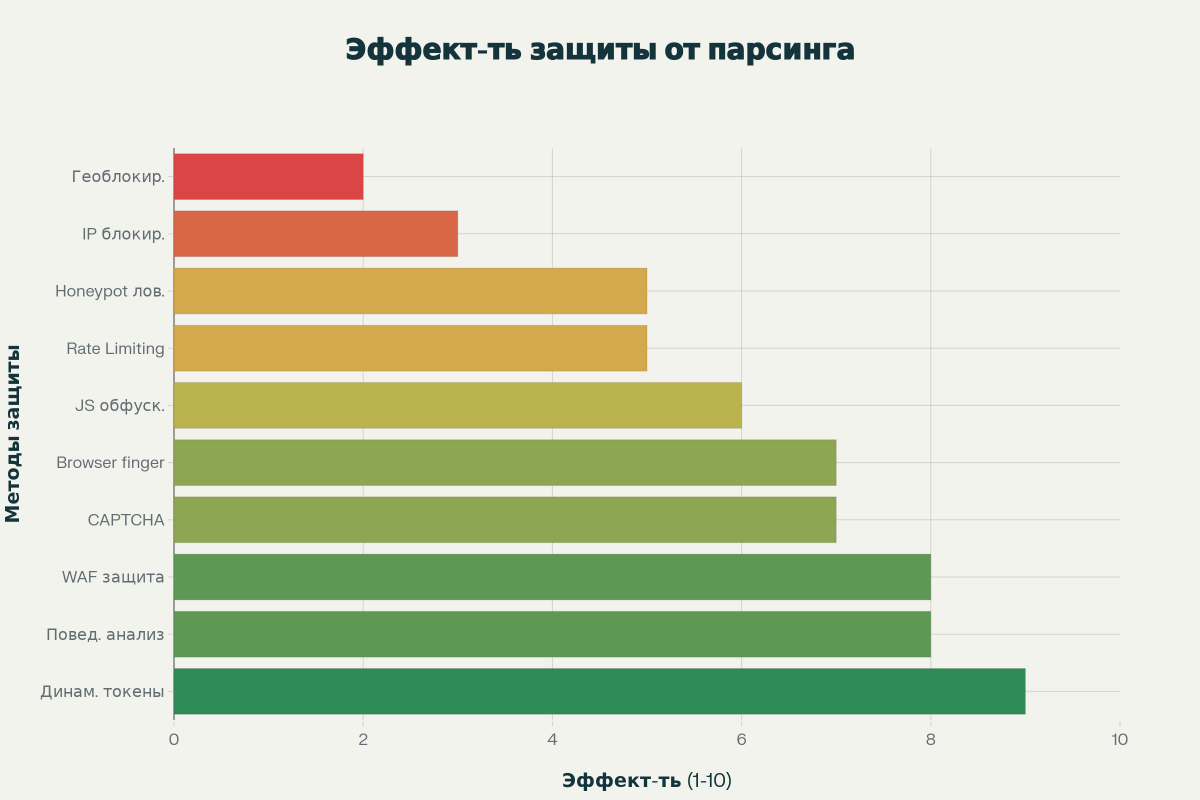
3.3. Блокировка по IP-адресу и User-Agent: Простые, но хрупкие методы
Эти методы являются самыми прямолинейными, но и самыми легко обходимыми.
- Блокировка по IP-адресу: Если вы заметили в логах сервера аномальную активность с одного или нескольких IP-адресов, вы можете заблокировать их на уровне веб-сервера или файрвола.38
- Недостаток: Этот метод практически бесполезен против современных парсеров. Они используют ротируемые прокси — огромные сети из тысяч и миллионов IP-адресов (часто это IP-адреса реальных пользователей, так называемые резидентные прокси). Парсер автоматически меняет IP-адрес для каждого нового запроса или через короткие промежутки времени, делая блокировку конкретного IP бессмысленной.40
- Блокировка по User-Agent: Каждый HTTP-запрос содержит заголовок User-Agent, который идентифицирует программу-клиент (например, Chrome/125.0.0.0 или YandexBot/3.0). Можно составить черный список User-Agent’ов, принадлежащих известным парсерам или SEO-инструментам, и блокировать запросы от них.44
- Пример для Nginx:
Nginx# /etc/nginx/nginx.conf
http {
...
if ($http_user_agent ~* (AhrefsBot|SemrushBot|MJ12bot)) {
return 403;
}
...
} - Недостаток: Заголовок User-Agent — это просто текстовая строка, которую можно легко подделать. Любой разработчик парсера может указать в качестве User-Agent’а строку от популярного браузера, например, Google Chrome, и эта защита его не остановит.
В заключение, базовые методы защиты — это важный первый шаг. Они отсекают неквалифицированные угрозы и создают фундамент для более сложных систем. Однако полагаться только на них в борьбе с целенаправленным коммерческим парсингом — все равно что пытаться остановить танк забором из штакетника.
Часть 4: Активная оборона — усложняем жизнь парсерам
Если базовые методы защиты можно сравнить со статичной стеной, то активная оборона — это система динамических ловушек и препятствий. Ее цель — не просто заблокировать бота, а сделать процесс парсинга настолько сложным, дорогим и непредсказуемым, что он становится экономически нецелесообразным. Эффективность этих методов обратно пропорциональна их предсказуемости: чем больше случайности и динамики, тем сложнее парсеру адаптироваться.
4.1. CAPTCHA: Эволюция и дилемма «Безопасность vs. UX»
CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart) — это самый известный механизм для различения людей и ботов.47 За годы своего существования он прошел значительную эволюцию.
- Эволюция версий:
- reCAPTCHA v2: Это классический и самый узнаваемый вид капчи. Он представлен в двух вариантах: флажок «I’m not a robot» и, в случае подозрений, задача с выбором изображений (например, «выберите все светофоры»).49 Этот метод понятен большинству пользователей, но часто вызывает раздражение, особенно когда приходится решать несколько головоломок подряд. Кроме того, он создает серьезные проблемы для людей с нарушениями зрения.47
- reCAPTCHA v3: Эта версия работает преимущественно в фоновом режиме и невидима для пользователя. Она анализирует поведение посетителя на сайте (движения мыши, время между кликами, историю взаимодействия) и на основе этих данных присваивает ему «оценку риска» (score) от 0.1 (вероятно, бот) до 0.9 (вероятно, человек).49 Владелец сайта сам решает, что делать с пользователями с низкой оценкой: заблокировать, запросить дополнительную проверку (например, показать reCAPTCHA v2) или пропустить. Это значительно улучшает пользовательский опыт (UX), но вызывает серьезные опасения по поводу конфиденциальности, так как для анализа Google собирает огромное количество поведенческих данных.47
- hCaptcha: Популярная альтернатива от компании Intuition Machines, которую часто использует Cloudflare. Для пользователя она выглядит похоже на reCAPTCHA v2 — нужно решать задачи по разметке изображений. Ее бизнес-модель заключается в том, что размеченные пользователями данные продаются компаниям, занимающимся машинным обучением. Задачи в hCaptcha часто воспринимаются как более сложные и утомительные, чем в reCAPTCHA.52
- Проблема обхода: Несмотря на всю сложность, CAPTCHA является легко преодолимым барьером для любого серьезного парсера. Существуют десятки специализированных сервисов (например, 2Captcha, RuCaptcha, Anti-Captcha), которые интегрируются с парсерами через API. Парсер отправляет картинку с капчей на такой сервис, где ее за несколько секунд решает либо человек, либо продвинутый AI, и возвращает готовый ответ.55 Стоимость таких услуг крайне низка — например, решение 1000 reCAPTCHA v2 может стоить около $2-3, а текстовых капч — менее $1.39 Это делает экономику обхода CAPTCHA абсолютно рентабельной.
- Влияние на конверсию: CAPTCHA — это барьер не только для ботов, но и для ваших потенциальных клиентов. Исследования показывают, что наличие капчи может снизить конверсию на 3-4%.58 Исследование Стэнфордского университета показало, что в среднем пользователи тратят около 10 секунд на решение капчи, а в 8% случаев они просто не могут ее решить и покидают сайт.58 Это означает, что, устанавливая капчу для защиты от ботов, вы сознательно жертвуете частью своих реальных клиентов.
4.2. Honeypots (Ловушки-приманки): Ловим бота «на живца»
Концепция Honeypot («горшочек с медом») заключается в создании ловушек, которые невидимы и недоступны для обычного человека, но которые обязательно привлекут внимание автоматизированного бота.59 Это элегантный способ защиты, который эксплуатирует «тупость» и неразборчивость скриптов.
- Примеры реализации:
- Скрытое поле в форме: В любую форму на сайте (регистрации, входа, комментария) добавляется дополнительное текстовое поле, например, <input type=»text» name=»comment_email» style=»display:none»>. С помощью CSS оно делается абсолютно невидимым для человеческого глаза. Реальный пользователь никогда его не заполнит. А вот простой бот, который запрограммирован на заполнение всех полей формы, вставит туда какие-то данные. На сервере достаточно добавить простую проверку: если это скрытое поле заполнено, значит, запрос пришел от бота, и его можно молча отклонить или заблокировать IP-адрес отправителя.61
- Невидимая ссылка: В код страницы (например, в футер) добавляется ссылка, которая скрыта от пользователей с помощью CSS (например, visibility: hidden или смещение за пределы экрана). «Хорошие» поисковые боты не будут переходить по этой ссылке, если она запрещена в robots.txt. Человек ее просто не увидит. А вот «плохой» бот, который жадно сканирует весь HTML-код в поисках ссылок, перейдет по ней. Эта ссылка может вести на специальный скрипт, который немедленно занесет IP-адрес бота в черный список.59
4.3. Динамическая маскировка контента: Постоянно меняющееся поле боя
Цель этих методов — сделать структуру вашего сайта максимально непредсказуемой для парсеров.
- Загрузка данных через JavaScript/AJAX: Это один из самых эффективных способов усложнить парсинг. Вместо того чтобы вставлять важные данные (например, цену товара, номер телефона, описание) непосредственно в HTML-код страницы при ее генерации на сервере, вы оставляете на их месте пустой блок-заглушку. Сами данные подгружаются уже в браузере пользователя с помощью отдельного асинхронного JavaScript-запроса (AJAX) к вашему API.62 Простые парсеры, которые скачивают только исходный HTML-код, просто не увидят этих данных. Чтобы их получить, парсеру придется использовать так называемый «headless-браузер» (например, Puppeteer или Selenium) — полноценный браузер, работающий без графического интерфейса. Это на порядок сложнее, медленнее и требует значительно больше серверных ресурсов, что резко повышает стоимость парсинга.62
- Динамическое изменение верстки: Этот метод направлен на то, чтобы «сломать» логику парсеров, которые ориентируются на конкретную структуру HTML-документа (CSS-селекторы, XPath). С помощью серверного скрипта вы можете сделать так, чтобы при каждой загрузке страницы (или раз в несколько часов) имена CSS-классов и id элементов генерировались случайным образом. Например, вместо <div class=»price»> будет <div class=»ax7b-c9f»>. Для пользователя ничего не изменится, так как стили будут применяться к новым классам. Но парсер, который был настроен на поиск элемента с классом price, перестанет работать и потребует постоянной ручной перенастройки со стороны его разработчика.39
Таблица 3: Сравнительный анализ CAPTCHA-решений
| Тип CAPTCHA | Принцип работы | Влияние на UX | Аспект приватности (GDPR) | Эффективность и уязвимости |
| reCAPTCHA v2 | Пользователь подтверждает, что он не робот, ставя галочку или решая визуальную задачу (выбор картинок).47 | Негативное. Раздражает пользователей, замедляет взаимодействие, имеет проблемы с доступностью для людей с ограниченными возможностями.50 | Средние риски. Google собирает данные о браузере и поведении пользователя для оценки, но основной фокус на задаче. | Легко обходится автоматизированными сервисами решения капчи (2Captcha, RuCaptcha) за низкую плату.48 |
| reCAPTCHA v3 | Невидима для пользователя. Анализирует поведение на сайте и присваивает оценку риска (score). Решение о блокировке принимает сайт.49 | Позитивное. Не прерывает пользовательский путь в большинстве случаев. | Высокие риски. Для анализа собирает обширные поведенческие данные, что может нарушать GDPR, если нет явного согласия. Google может использовать данные для своих целей.47 | Более устойчива к простым ботам, но продвинутые боты могут имитировать поведение человека. Требует сложной настройки на стороне сайта для обработки оценок. |
| hCaptcha | Пользователь решает визуальную задачу по разметке изображений. Данные используются для обучения ML-моделей.52 | Очень негативное. Задачи часто сложнее и утомительнее, чем в reCAPTCHA v2. | Средние риски. Собирает меньше поведенческих данных, чем v3, но использует cookie для отслеживания. Бизнес-модель основана на продаже размеченных данных.53 | Схожа с reCAPTCHA v2. Также уязвима для сервисов ручного решения. Может быть эффективна против ботов, но ценой значительного ухудшения UX.52 |
| Альтернативы (например, Friendly Captcha) | Пользователь решает небольшую криптографическую задачу в фоновом режиме, не требующую взаимодействия. | Очень позитивное. Полностью невидима и не требует от пользователя никаких действий. | Низкие риски. Разработана с упором на приватность, не использует cookie и не собирает персональные данные. | Эффективна против большинства ботов, так как требует значительных вычислительных ресурсов для массового решения, что делает атаку нерентабельной. |
Часть 5: Продвинутая защита — технологии идентификации нового поколения
Когда базовые и активные методы обороны оказываются недостаточными, в игру вступают технологии, которые смещают фокус с анализа самого запроса на глубокий анализ того, кто этот запрос отправляет. Цель этих методов — не просто блокировать аномальные запросы, а верифицировать легитимность клиента, создавая для него уникальный и трудно подделываемый идентификатор. Это фундаментальный сдвиг парадигмы: от блокировки «плохих» к пропуску «проверенных хороших».
5.1. Цифровой отпечаток браузера (Browser Fingerprinting): Идентификация по совокупности признаков
- Концепция: Browser Fingerprinting — это технология сбора десятков и сотен неперсональных технических параметров браузера, операционной системы и аппаратного обеспечения пользователя. Комбинация этих параметров оказывается настолько уникальной, что позволяет создать стабильный цифровой «отпечаток» (fingerprint), который идентифицирует конкретное устройство с высокой точностью (до 90-99%).64 В отличие от cookie, этот отпечаток не удаляется при очистке браузера и остается неизменным даже в режиме инкогнито.64
- Собираемые параметры: В состав отпечатка входят: строка User-Agent, список установленных плагинов и шрифтов, параметры экрана (разрешение, глубина цвета), часовой пояс, язык системы, характеристики аудио- и видеокарт и многое другое.68
- Ключевые технологии:
- Canvas Fingerprinting: Это одна из самых мощных техник. На странице создается невидимый для пользователя HTML5-элемент canvas, на котором с помощью JavaScript рисуется определенный текст с набором эффектов. То, как именно это изображение будет отрисовано, до мельчайших деталей на уровне отдельных пикселей, зависит от уникальной комбинации видеокарты, графических драйверов, операционной системы и самого браузера. Затем это изображение преобразуется в строку данных (хеш). На двух внешне одинаковых компьютерах эти хеши почти всегда будут разными, что дает очень точный компонент для общего отпечатка.68
- WebGL Fingerprinting: Техника, аналогичная Canvas, но использующая API для рендеринга 3D-графики (WebGL). Она позволяет собрать еще более детальную и уникальную информацию о графическом процессоре (GPU), его производителе, версии и поддерживаемых расширениях. Подделать WebGL-отпечаток на порядок сложнее, чем Canvas, так как для этого требуется эмулировать поведение конкретного «железа».68
- WebRTC Fingerprinting: Технология WebRTC, предназначенная для аудио- и видеосвязи в реальном времени, имеет побочный эффект: она может раскрыть реальный IP-адрес пользователя, даже если он использует VPN или прокси-сервер. Системы защиты используют этот API для получения дополнительного сигнала при идентификации клиента.68
- Реализация: Для самостоятельной реализации можно использовать open-source библиотеки, такие как FingerprintJS 67, ClientJS 69 или ThumbmarkJS.74 Однако стоит понимать, что точность таких клиентских решений ограничена (40-60%) и они уязвимы для подделки. Коммерческие системы (например, Fingerprint Pro) достигают точности 99.5% за счет серверной обработки данных и использования машинного обучения.67
5.2. Поведенческий анализ: «Двигайся как человек»
Эта группа методов основана на простом наблюдении: боты, даже самые продвинутые, взаимодействуют с веб-страницей не так, как люди. Системы поведенческого анализа отслеживают и оценивают эту динамику в реальном времени.39
- Анализируемые метрики:
- Движение мыши: Человек двигает курсор по плавным, часто хаотичным кривым, останавливается, наводя на элементы. Бот либо телепортирует курсор из одной точки в другую, либо движет его по идеально прямой линии с постоянной скоростью.
- Скроллинг: Люди прокручивают страницу с разной скоростью, с рывками, останавливаясь для чтения. Боты скроллят монотонно или мгновенно до конца страницы.
- Скорость набора текста: Человек печатает с определенным ритмом, делает паузы, исправляет опечатки. Бот вставляет текст в поле формы мгновенно и без ошибок.
- Взаимодействие с элементами: Анализируется последовательность кликов, время, проведенное на странице перед действием, и другие паттерны, которые в совокупности создают уникальный поведенческий портрет.
5.3. Защита API: Закрываем «черный ход»
В современной веб-разработке, особенно с распространением одностраничных приложений (SPA), большая часть контента загружается не вместе с HTML-страницей, а через фоновые запросы к API (Application Programming Interface). Для парсеров это настоящий подарок: вместо того чтобы разбирать сложный HTML, они могут напрямую обращаться к API и получать чистые, структурированные данные в формате JSON.62 Если ваш API не защищен, все остальные слои обороны сайта становятся практически бесполезными.
- Аутентификация vs. Авторизация: Ключевое различие
- Аутентификация отвечает на вопрос «Кто ты?». Это процесс проверки подлинности клиента, который пытается получить доступ. Система удостоверяется, что клиент является тем, за кого себя выдает.77 Если аутентификация не пройдена, сервер обычно возвращает ошибку
401 Unauthorized. - Авторизация отвечает на вопрос «Что тебе можно делать?». Это процесс предоставления уже аутентифицированному клиенту определенных прав и разрешений. Например, обычный пользователь может читать данные через API, а администратор — еще и изменять их.78 Если у клиента нет прав на операцию, сервер вернет ошибку
403 Forbidden. - Методы защиты API:
- API-ключи: Самый простой метод. Каждому приложению-клиенту выдается уникальная строка (ключ), которая должна передаваться в каждом запросе к API (обычно в заголовке). Сервер проверяет наличие и валидность ключа.78 Этот метод хорош для публичных API, но не очень безопасен, так как ключ может быть украден.
- Аутентификация по токену (Bearer Token, JWT): Это стандарт де-факто для современных API. Клиент сначала проходит аутентификацию (например, по логину и паролю), а взамен получает от сервера специальный токен (чаще всего JSON Web Token, JWT) с ограниченным сроком действия. Далее клиент включает этот токен в заголовок Authorization: Bearer <token> в каждом последующем запросе. Серверу не нужно каждый раз проверять пароль, достаточно проверить валидность токена.77
- OAuth 2.0: Это не метод аутентификации, а фреймворк авторизации. Он используется, чтобы позволить одному приложению (например, вашему сайту) получить ограниченный доступ к данным пользователя в другом приложении (например, в его профиле Google или VK) от имени этого пользователя, не получая при этом его пароль. Это сложный, но очень мощный и безопасный стандарт для управления доступом.77
- Rate Limiting для API: К конечным точкам (endpoints) API обязательно должны применяться те же принципы ограничения частоты запросов, что и к обычным страницам сайта, чтобы предотвратить злоупотребления и перегрузку.86
Часть 6: Коммерческие решения — комплексная защита «под ключ»
Хотя самостоятельная реализация многоуровневой защиты возможна, она требует серьезной экспертизы и постоянной поддержки. Для большинства компаний более эффективным решением является использование специализированных коммерческих сервисов. Эти платформы предлагают комплексную защиту от ботов «из коробки», сочетая в себе все передовые технологии и постоянно обновляя свои алгоритмы для борьбы с новыми угрозами.
6.1. Обзор рынка: Кто задает тренды?
Рынок защиты от ботов является частью более крупного рынка WAAP (Web Application and API Protection). Лидерство здесь определяют авторитетные аналитические агентства, такие как Gartner и Forrester. В их отчетах (Gartner Magic Quadrant, Forrester Wave) из года в год в качестве лидеров фигурируют одни и те же глобальные игроки: Cloudflare, Akamai и Imperva.87 Их ключевое преимущество заключается не столько в уникальности технологий (все они используют схожий стек: ML, fingerprinting, поведенческий анализ), сколько в огромном объеме данных, на которых обучаются их модели. Анализируя триллионы запросов в день с миллионов сайтов по всему миру, они способны выявлять новые угрозы в реальном времени и мгновенно применять защиту для всех своих клиентов.91
6.2. Ведущие международные провайдеры
- Технология: Cloudflare работает как обратный прокси (reverse proxy), пропуская через свою глобальную сеть весь трафик вашего сайта. Для каждого запроса система вычисляет «Bot Score» (оценку бота) от 1 (явный бот) до 99 (явный человек) на основе машинного обучения, поведенческого анализа и данных fingerprinting.91
- Подход: Вместо агрессивной блокировки, которая может задеть реальных пользователей, Cloudflare предпочитает использовать «умные» проверки (challenges), которые часто невидимы для человека. Компания активно развивает альтернативы традиционной CAPTCHA, например, технологию Private Access Tokens для устройств Apple.93
- Ценообразование: Одним из главных преимуществ Cloudflare является наличие мощного бесплатного тарифа, который включает базовую защиту от DDoS и WAF. Продвинутое управление ботами (Bot Management) доступно на платных тарифах: Business (от $200-250 в месяц) и Enterprise (цена договорная).94
- Кейсы: Компании из сферы e-commerce используют Cloudflare для защиты от ботов-скальперов, которые массово скупают лимитированные товары, и от атак типа Credential Stuffing, направленных на взлом аккаунтов.91
- Akamai:
- Технология: Akamai — один из старейших и крупнейших CDN-провайдеров и пионеров в области кибербезопасности. Их решение Bot Manager также использует многоуровневый подход с применением AI/ML, поведенческого анализа (анализ движений мыши, ритма нажатия клавиш) и сложного fingerprinting для генерации собственного «Bot Score».92
- Подход: Akamai делает особый акцент на управлении трафиком из «серой зоны». Вместо простой блокировки они предлагают широкий спектр ответных действий: замедление бота, подмена данных (например, показ завышенных цен), отправка в кэш, чтобы снизить нагрузку на сервер.99
- Ценообразование: Это решение исключительно корпоративного уровня. Цены не публикуются и формируются индивидуально в зависимости от объема трафика и требуемого уровня защиты. Стоимость может достигать десятков тысяч долларов в месяц.101
- Кейсы: Akamai успешно защищает ритейлеров от ботов, скупающих лимитированные кроссовки (sneaker bots), и авиакомпании от агрессивного парсинга цен на билеты.92
- Imperva (ранее Distil Networks):
- Технология: Imperva Advanced Bot Protection славится своей дотошностью в идентификации ботов. Их технология fingerprinting анализирует более 200 атрибутов устройства и браузера. Решение защищает не только веб-сайты, но и мобильные приложения, и API.103
- Подход: Imperva позиционирует свое решение как защиту от всех автоматизированных угроз из списка OWASP. Они предлагают самый широкий спектр ответных мер, включая «смоляную яму» (tarpit) — технику, которая удерживает соединение с ботом, заставляя его тратить ресурсы, но не отдавая контент.105
- Ценообразование: Как и Akamai, Imperva является решением корпоративного класса с индивидуальным ценообразованием по запросу.107
6.3. Российские сервисы защиты
На российском рынке также есть сильные игроки, которые исторически выросли из сервисов по защите от DDoS-атак и со временем добавили в свой портфель решения для борьбы с ботами.
- Технология: Основной продукт — защита от DDoS-атак. Защита от ботов реализована в виде дополнительного модуля Bot Mitigation. Он работает на основе анализа заголовков (включая User-Agent), сигнатурного анализа и поведенческих факторов, на основе которых выставляется bot score. Для трафика из «серой зоны» применяются проверки JS challenge и CAPTCHA.109
- Подход: Предлагается как интегрированное решение в рамках общей платформы защиты. Является более простым и доступным вариантом по сравнению с глобальными лидерами.
- Ценообразование: Часто предлагается как недорогая дополнительная услуга к основному пакету защиты от DDoS. Например, у хостинг-провайдеров-партнеров (таких как Timeweb) стоимость может составлять всего несколько сотен рублей в месяц.112
- Qrator Labs:
- Технология: Qrator Labs также является экспертом в области противодействия DDoS. Их продукт Qrator Bot Protection использует комбинацию анализа запросов, пассивного и активного цифрового отпечатка пользователя для обнаружения ботов. Важной особенностью является точечная блокировка отдельных вредоносных запросов, а не всего IP-адреса.113
- Подход: Компания делает акцент на блокировке вредоносной активности с первого же запроса, без необходимости длительного «обучения» на трафике клиента. Принципиально не используют CAPTCHA, чтобы не ухудшать пользовательский опыт.114
- Ценообразование: Решение корпоративного уровня, стоимость рассчитывается индивидуально.
- Другие игроки: На рынке также присутствуют и другие сервисы, например, Servicepipe с продуктом Bot Protection, BotFAQtor и облачный сервис Antibot.Cloud, ориентированный на защиту PHP-сайтов.113
Таблица 4: Сравнение ведущих сервисов защиты от парсинга (Россия и мир)
| Сервис | Страна | Ключевые технологии | Модель ценообразования | Целевой сегмент | Ключевое преимущество |
| Cloudflare | США | ML, Bot Score, Fingerprinting, поведенческий анализ, Private Access Tokens | Freemium (бесплатный базовый тариф, платные тарифы от $200/мес) 94 | SMB, Enterprise | Огромная сеть, лучшее соотношение цена/качество, простота настройки, мощный бесплатный тариф. |
| Akamai | США | AI/ML, поведенческий анализ (движение мыши, нажатия клавиш), Fingerprinting, Bot Score | По запросу (Enterprise) | Крупный Enterprise | Высочайшая точность детекции, гибкие политики реагирования (не только блокировка), огромный опыт. |
| Imperva | США | Глубокий Fingerprinting (>200 атрибутов), биометрическая валидация, защита API и мобильных приложений | По запросу (Enterprise) | Enterprise | Комплексная защита от всех угроз OWASP, широкий спектр ответных мер, включая «tarpit». |
| DDoS-Guard | Россия | Bot score на основе сигнатур и User-Agent, JS challenge, CAPTCHA | Доп. услуга к защите от DDoS (от ~300 руб/мес у партнеров) 112 | SMB, средний бизнес | Доступность, простота, интеграция с популярной в РФ защитой от DDoS. |
| Qrator Labs | Россия | Анализ запросов, цифровой отпечаток, точечная блокировка запросов | По запросу (Enterprise) | Enterprise, госсектор | Высокая экспертиза в РФ, отказ от CAPTCHA, блокировка с первого запроса. |
Часть 7: Стратегия защиты — как выбрать и внедрить правильное решение?
После детального разбора угроз, юридических аспектов и технологических решений наступает самый важный этап — формирование собственной стратегии защиты. Не существует универсального ответа, подходящего всем. Правильный выбор зависит от специфики вашего бизнеса, ценности ваших данных и готовности инвестировать в их безопасность.
7.1. Нужна ли вам защита? Чек-лист для самооценки
Прежде чем вкладывать ресурсы в защиту от парсинга, честно ответьте на следующие вопросы. Чем больше ответов «да», тем острее для вас стоит эта проблема:
- Ценность данных: Является ли контент на вашем сайте (статьи, описания, отзывы) уникальным и результатом значительных вложений? Представляет ли ваша база данных (каталог товаров, объявлений, пользователей) коммерческую ценность?
- Конкурентная среда: Является ли цена ключевым фактором конкуренции в вашей нише? Замечали ли вы, что конкуренты мгновенно реагируют на ваши ценовые изменения? (Критично для e-commerce).1
- Техническая производительность: Сталкивались ли вы с необъяснимыми пиками нагрузки на сервер, которые не коррелируют с маркетинговыми активностями? Жалуются ли пользователи на медленную работу сайта?
- Безопасность и спам: Страдаете ли вы от массовых фейковых регистраций, спама в комментариях или формах обратной связи? Были ли попытки подбора паролей к аккаунтам пользователей (credential stuffing)?.39
- SEO-показатели: Наблюдаете ли вы проблемы с индексацией новых страниц или находите копии вашего контента на других сайтах, которые ранжируются выше вас?.8
Если вы ответили «да» на 2-3 и более вопросов, вам определенно стоит задуматься о внедрении как минимум базовых, а возможно, и продвинутых мер защиты.
7.2. Построение многоуровневой системы защиты (Defense in Depth)
Самая большая ошибка — полагаться на какой-то один, даже самый продвинутый, метод защиты. Эффективная оборона всегда эшелонирована, то есть состоит из нескольких уровней, каждый из которых дополняет предыдущий. Этот принцип называется «Defense in Depth».
Пример архитектуры многоуровневой защиты:
- Уровень 1 (Фундаментальный): Настройка на уровне сервера.
- Действия: Корректная настройка файла robots.txt для управления «хорошими» ботами. Внедрение Rate Limiting на веб-сервере (Nginx, Apache) для ограничения частоты запросов с одного IP.
- Цель: Отсечь самых простых, неквалифицированных ботов и скрипты. Создать базовый «гигиенический» барьер с минимальными затратами.33
- Уровень 2 (Активная оборона): Усложнение на уровне приложения.
- Действия: Внедрение Honeypots (ловушек-приманок) в формы и HTML-код. Загрузка наиболее ценных данных (цен, контактов) через AJAX-запросы. Реализация механизма динамической смены CSS-классов.
- Цель: Сделать парсинг экономически невыгодным для целенаправленных ботов, заставив их разработчиков постоянно адаптировать и усложнять свои скрипты.61
- Уровень 3 (Продвинутая верификация): Специализированные сервисы.
- Действия: Подключение внешнего сервиса защиты (например, Cloudflare, DDoS-Guard или другого провайдера из Части 6).
- Цель: Передать задачу обнаружения самых сложных ботов (которые используют headless-браузеры, ротируемые прокси и имитируют поведение человека) на откуп профессионалам. Эти системы используют Browser Fingerprinting, поведенческий анализ и машинное обучение на огромных объемах данных, что невозможно реализовать в рамках одного проекта.92
7.3. Практические рекомендации по внедрению
Внедрение систем защиты — это деликатный процесс, в котором легко навредить. Следуйте этим правилам, чтобы минимизировать риски:
- Сначала мониторинг, потом блокировка. Никогда не включайте блокировку сразу. Запустите любую новую систему (будь то Rate Limiting или коммерческий сервис) в режиме «только мониторинг» или «только логирование» на несколько дней или недель. Проанализируйте, какой трафик система помечает как ботов. Убедитесь, что в это число не попадают легитимные пользователи, важные партнеры или поисковые системы.
- Управляйте «белыми списками» (Allowlisting). Обязательно создайте и поддерживайте список доверенных ботов, которым всегда должен быть разрешен доступ. В первую очередь это Googlebot и YandexBot. Также сюда могут входить боты различных маркетинговых сервисов, которые вы используете. Блокировка поисковых роботов — самый быстрый способ уничтожить SEO вашего сайта.39
- Оценивайте влияние на производительность. Любая дополнительная проверка — это дополнительная нагрузка на сервер или задержка для пользователя. Простые методы, как Rate Limiting, почти не влияют на производительность. Сложные, как JS-проверки и fingerprinting, могут незначительно замедлить загрузку страницы. Тестируйте скорость сайта до и после внедрения защиты.
- Помните, что это процесс, а не проект. Ландшафт угроз постоянно меняется. Боты становятся умнее, появляются новые техники парсинга. Регулярно (хотя бы раз в квартал) просматривайте логи вашей системы защиты, анализируйте, кого и почему она блокирует, и при необходимости корректируйте правила. Защита от парсинга — это непрерывная гонка вооружений.
Заключение: Баланс между открытостью и безопасностью
Мы прошли долгий путь: от понимания, что такое парсинг, до анализа сложных юридических коллизий и погружения в передовые технологии кибербезопасности. Становится очевидно, что защита от нежелательного сбора данных — это не просто техническая настройка, а комплексная бизнес-задача, требующая стратегического подхода.
Ключевые выводы нашего исследования можно свести к нескольким тезисам:
- Парсинг — это не абстрактная угроза, а прямой и измеримый риск для выручки, репутации, позиций в поиске и безопасности вашего бизнеса. Игнорировать его в современной конкурентной среде — значит добровольно отдавать свои преимущества противникам.
- Не существует «серебряной пули». Ни один, даже самый дорогой, метод не даст стопроцентной гарантии. Эффективная защита — это всегда многоуровневая система (Defense in Depth), где простые серверные настройки дополняются активными ловушками на уровне приложения и, при необходимости, мощными коммерческими платформами.
- Правовая база — важный, но вспомогательный инструмент. Законы об авторском праве и персональных данных дают вам юридические основания для преследования нарушителей, но без технических средств для их обнаружения и идентификации эти законы остаются бессильны. Грамотное Пользовательское соглашение — ваш главный юридический щит.
- Выбор стратегии зависит от ценности ваших данных. Не каждому сайту нужен «противотанковый ров» корпоративного уровня. Оцените свои риски и начните с фундаментальных мер. Если ваш бизнес критически зависит от уникальности контента или цен — инвестиции в продвинутые коммерческие решения абсолютно оправданы.
Взглянув в будущее, можно с уверенностью сказать, что гонка вооружений между парсерами и системами защиты будет только обостряться. Искусственный интеллект уже сегодня используется с обеих сторон: для создания все более «человекоподобных» ботов, способных обходить сложные проверки, и для разработки более интеллектуальных систем их обнаружения. В этих условиях задача владельца сайта — не стремиться к абсолютной, недостижимой неуязвимости, а поддерживать разумный баланс. Баланс между открытостью, необходимой для привлечения клиентов и поисковых систем, и безопасностью, которая защищает самые ценные цифровые активы, созданные вашим трудом.
Источники
- Парсинг это что такое простыми словами: сайтов, данных — Rush Analytics, дата последнего обращения: июля 21, 2025, https://www.rush-analytics.ru/blog/chto-takoe-parser
- Парсинг данных с сайтов: что это и зачем он нужен — Блог Ringostat, дата последнего обращения: июля 21, 2025, https://blog.ringostat.com/ru/parsing-dannyh-s-saytov-chto-eto-i-zachem-on-nuzhen/
- Что такое парсинг сайтов, для чего нужен парсер — Webcom Performance, дата последнего обращения: июля 21, 2025, https://www.promowebcom.by/analytics/articles/seo/chto-takoe-parsing-saytov/
- Что такое парсинг и что о нём обязательно нужно знать маркетологу — Skillbox, дата последнего обращения: июля 21, 2025, https://skillbox.ru/media/marketing/chto-takoe-parsing-i-chto-o-nyem-obyazatelno-nuzhno-znat-marketologu/
- Защита сайта от парсинга: как это работает, и зачем нужно | Zennolab Journal, дата последнего обращения: июля 21, 2025, https://journal.zennolab.com/zashhita-sajta-ot-parsinga-kak-jeto-rabotaet-i-zachem-nuzhno/
- Парсинг: что это такое | Блог Roistat, дата последнего обращения: июля 21, 2025, https://roistat.com/rublog/parsing/
- Парсинг: законно ли им пользоваться — Altcraft CDP, дата последнего обращения: июля 21, 2025, https://altcraft.com/ru/glossary/parsing-chto-eto-takoe-i-mogut-li-za-nego-oshtrafovat
- Гайд по дублированному контенту в SEO — PR Posting, дата последнего обращения: июля 21, 2025, https://prposting.com/ru/blog/90-duplicate-content-in-seo
- ТОП-10 SEO-атак и как от них защититься — SEOnews, дата последнего обращения: июля 21, 2025, https://m.seonews.ru/analytics/top-10-seo-atak-i-kak-ot-nikh-zashchititsya/
- OWASP Automated Threats to Web Applications, дата последнего обращения: июля 21, 2025, https://owasp.org/www-project-automated-threats-to-web-applications/
- Что такое парсинг и как правильно парсить — Calltouch, дата последнего обращения: июля 21, 2025, https://www.calltouch.ru/blog/chto-takoe-parsing/
- HiQ v. LinkedIn: web scraping case law — Apify Blog, дата последнего обращения: июля 21, 2025, https://blog.apify.com/hiq-v-linkedin/
- The Ultimate Guide To The OWASP 21 Top Automated Threats and Security Capabilities To Stop Them — Radware, дата последнего обращения: июля 21, 2025, https://www.radware.com/getattachment/81a3f83f-f3d5-4d60-b1f8-4dbd27e55d6a/OWASP-Top-21-Automated-Threats-and-How-To-Stop-Them-Guide_2022_Guide.pdf.aspx
- OWASP Automated Threats to Web Applications — F5 Networks, дата последнего обращения: июля 21, 2025, https://www.f5.com/glossary/owasp-automated-threats
- HIQ LABS, INC. V. LINKEDIN CORPORATION, No. 17-16783 (9th Cir. 2022) — Justia Law, дата последнего обращения: июля 21, 2025, https://law.justia.com/cases/federal/appellate-courts/ca9/17-16783/17-16783-2022-04-18.html
- Ninth Circuit Holds Data Scraping is Legal in hiQ v. LinkedIn — California Lawyers Association, дата последнего обращения: июля 21, 2025, https://calawyers.org/privacy-law/ninth-circuit-holds-data-scraping-is-legal-in-hiq-v-linkedin/
- hiQ Labs v. LinkedIn — Wikipedia, дата последнего обращения: июля 21, 2025, https://en.wikipedia.org/wiki/HiQ_Labs_v._LinkedIn
- What Recent Rulings in ‘hiQ v. LinkedIn’ and Other Cases Say About the Legality of Data Scraping — Farella Braun + Martel LLP, дата последнего обращения: июля 21, 2025, https://www.fbm.com/publications/what-recent-rulings-in-hiq-v-linkedin-and-other-cases-say-about-the-legality-of-data-scraping/
- hiQ v. LinkedIn Wrapped Up: Web Scraping Lessons Learned — ZwillGen, дата последнего обращения: июля 21, 2025, https://www.zwillgen.com/alternative-data/hiq-v-linkedin-wrapped-up-web-scraping-lessons-learned/
- ГК РФ Статья 1274. Свободное использование произведения в информационных, научных, учебных или культурных целях — КонсультантПлюс, дата последнего обращения: июля 21, 2025, https://www.consultant.ru/document/cons_doc_LAW_64629/84bbd636598a59112a4fe972432343dd4f51da1d/
- Парсинг сайтов. Россия и мир. Как с точки зрения закона выглядит один из самых полезных инструментов? — Право на vc.ru, дата последнего обращения: июля 21, 2025, https://vc.ru/legal/64328-parsing-saitov-rossiya-i-mir-kak-s-tochki-zreniya-zakona-vyglyadit-odin-iz-samyh-poleznyh-instrumentov
- Парсинг сайтов: законно или нет? Юридические способы защиты — Ezybrand, дата последнего обращения: июля 21, 2025, https://ezybrand.ru/blog/kak-zashhitit-svoj-veb-resurs-ot-kopirovaniya/
- How to Comply with the GDPR and CCPA as a Web Scraper …, дата последнего обращения: июля 21, 2025, https://mccarthylg.com/how-to-comply-with-the-gdpr-and-ccpa-as-a-web-scraper/
- Scraping and processing AI training data – key legal challenges under data protection laws, дата последнего обращения: июля 21, 2025, https://www.taylorwessing.com/en/insights-and-events/insights/2025/02/scraping-and-processing-ai-training-data
- Is Web Scraping Legal? — Scrapfly, дата последнего обращения: июля 21, 2025, https://scrapfly.io/is-web-scraping-legal
- The state of web scraping in the EU — IAPP, дата последнего обращения: июля 21, 2025, https://iapp.org/news/a/the-state-of-web-scraping-in-the-eu
- California Consumer Privacy Act (CCPA) | State of California …, дата последнего обращения: июля 21, 2025, https://oag.ca.gov/privacy/ccpa
- Understanding the Legal Landscape of Web Scraping — InstantAPI.ai, дата последнего обращения: июля 21, 2025, https://web.instantapi.ai/blog/understanding-the-legal-landscape-of-web-scraping/
- Настройка файла robots.txt — База знаний Timeweb Cloud, дата последнего обращения: июля 21, 2025, https://timeweb.cloud/docs/general/nastrojka-fajla-robots-txt
- Как настроить robots.txt — База знаний | Рег.ру, дата последнего обращения: июля 21, 2025, https://help.reg.ru/support/hosting/prodvizheniye-sayta/kak-nastroit-robots-txt
- Блокировка ботов с помощью robots.txt :: Биллинговая система Link-Host.net, дата последнего обращения: июля 21, 2025, https://link-host.net/billing/billing.php?do=faq&group=7&fgroup=0&item=55
- Роботы или боты: какие бывают, как их вычислять, ограничивать и блокировать, дата последнего обращения: июля 21, 2025, https://firstvds.ru/blog/kak-blokirovat-botam-dostup-k-saytu
- NGINX Rate Limiting: The Basics and 3 Code Examples | Solo.io, дата последнего обращения: июля 21, 2025, https://www.solo.io/topics/nginx/nginx-rate-limiting
- Настройка сервера Nginx для защиты от ботов: экспертное руководство, дата последнего обращения: июля 21, 2025, https://xmldatafeed.com/nastrojka-servera-nginx-dlya-zashhity-ot-botov-ekspertnoe-rukovodstvo/
- Rate Limiting with NGINX — NGINX Community Blog, дата последнего обращения: июля 21, 2025, https://blog.nginx.org/blog/rate-limiting-nginx
- Limiting Access to Proxied HTTP Resources | NGINX Documentation, дата последнего обращения: июля 21, 2025, https://docs.nginx.com/nginx/admin-guide/security-controls/controlling-access-proxied-http/
- Protecting Against Bot Attacks Using Nginx Rate Limits | by Irtiza Hafiz — Medium, дата последнего обращения: июля 21, 2025, https://irtizahafiz.medium.com/protecting-against-bot-attacks-using-nginx-rate-limits-12872fcbaafd
- Как снизить число запросов, ограничив доступ роботам на VPS — База знаний | Рег.ру, дата последнего обращения: июля 21, 2025, https://help.reg.ru/support/klassicheskie-vps/problemi-s-vps/kak-snizit-chislo-zaprosov-ogranichiv-dostup-robotam-na-vps
- Эффективные способы защиты от парсинга сайта — MegaIndex.com, дата последнего обращения: июля 21, 2025, https://ru.megaindex.com/blog/stop-bots
- Статические и ротируемые прокси-серверы. В чем разница? — Bright Data, дата последнего обращения: июля 21, 2025, https://ru-brightdata.com/blog/proxy-101-ru/static-vs-rotating-proxies
- 11 лучших ротационных прокси с неограниченной пропускной способностью, дата последнего обращения: июля 21, 2025, https://www.ipburger.com/ru/blog/rotating-proxies-with-unlimited-bandwidth/
- Как реализовать ротацию IP-адресов с помощью прокси-серверов | HackerNoon, дата последнего обращения: июля 21, 2025, https://hackernoon.com/lang/ru/%D0%BA%D0%B0%D0%BA-%D1%80%D0%B5%D0%B0%D0%BB%D0%B8%D0%B7%D0%BE%D0%B2%D0%B0%D1%82%D1%8C-%D1%80%D0%BE%D1%82%D0%B0%D1%86%D0%B8%D1%8E-IP-%D1%81-%D0%BF%D0%BE%D0%BC%D0%BE%D1%89%D1%8C%D1%8E-%D0%BF%D1%80%D0%BE%D0%BA%D1%81%D0%B8
- Что такое прокси и как парсить интернет-магазины с их помощью для обхода защиты?, дата последнего обращения: июля 21, 2025, https://vc.ru/services/86635-chto-takoe-proksi-i-kak-parsit-internet-magaziny-s-ih-pomoshyu-dlya-obhoda-zashity
- Как заблокировать кастомных ботов и другие user-agent. — Foxcloud.net, дата последнего обращения: июля 21, 2025, https://ru.foxcloud.net/kb/drugie-stati/kak-zablokirovat-kastomnyh-botov-i-drugie-user-agent.php
- Заблокировать User Agents используя Nginx — linux-notes.org, дата последнего обращения: июля 21, 2025, https://linux-notes.org/zablokirovat-user-agents-ispol-zuya-nginx/
- Блокировка ботов на сайте — просто и эффективно — Хостинг Джихост, дата последнего обращения: июля 21, 2025, https://jehost.ru/poleznaya-informatsiya/blokirovka-botov-na-sajte-prosto-i-effektivno.html
- reCAPTCHA v2 vs v3: Effective Bot Protection? [2025 Update], дата последнего обращения: июля 21, 2025, https://friendlycaptcha.com/insights/recaptcha-v2-vs-v3/
- CAPTCHA vs. reCAPTCHA — What are the key differences? — DataDome, дата последнего обращения: июля 21, 2025, https://datadome.co/guides/captcha/hcaptcha-vs-recaptcha/
- Choosing the type of reCAPTCHA — Google for Developers, дата последнего обращения: июля 21, 2025, https://developers.google.com/recaptcha/docs/versions
- CAPTCHA UX: Why CAPTCHA is bad and its alternatives — LogRocket Blog, дата последнего обращения: июля 21, 2025, https://blog.logrocket.com/ux-design/captcha-ux/
- Распознавание капчи – разбираемся в сложном для понимания процессе максимально просто — Habr, дата последнего обращения: июля 21, 2025, https://habr.com/ru/articles/846458/
- hCaptcha vs. reCAPTCHA | Blog, дата последнего обращения: июля 21, 2025, https://www.hcaptcha.com/post/hcaptcha-vs-recaptcha
- hCAPTCHA vs reCAPTCHA vs Friendly Captcha for Bot Protection, дата последнего обращения: июля 21, 2025, https://friendlycaptcha.com/insights/hcaptcha-vs-recaptcha/
- What is the difference between hCaptcha and reCAPTCHA? — Stack Overflow, дата последнего обращения: июля 21, 2025, https://stackoverflow.com/questions/74496380/what-is-the-difference-between-hcaptcha-and-recaptcha
- Антикапча — лучшие сервисы автоматического распознавания и обхода капчи | Блог SEO.RU, дата последнего обращения: июля 21, 2025, https://seo.ru/blog/10-luchshih-servisov-dlya-raspoznavaniya-kapchi/
- Антикапча: сервис для распознавания и обхода капчи, онлайн автоматического решения Google reCAPTCHA и других, дата последнего обращения: июля 21, 2025, https://rucaptcha.com/
- Решатель капчи: Автоматическое распознавание, решение и обход reCAPTCHA и других капч. Дешево и быстро, дата последнего обращения: июля 21, 2025, https://solvecaptcha.com/ru
- CAPTCHA негативно влияет на конверсии: компиляция исследований — SEOnews, дата последнего обращения: июля 21, 2025, https://m.seonews.ru/events/captcha-negativno-vliyaet-na-konversii-kompilyatsiya-issledovaniy/
- Top 20+ Types of Honeypots to Detect Network Threats — SecurityTrails, дата последнего обращения: июля 21, 2025, https://securitytrails.com/blog/top-honeypots
- What Is a Honeypot Trap and How to Bypass It — ZenRows, дата последнего обращения: июля 21, 2025, https://www.zenrows.com/blog/what-is-honeypot-trap
- How to stop bots with honeypots — WorkOS, дата последнего обращения: июля 21, 2025, https://workos.com/blog/stop-bots-with-honeypots
- Парсинг динамических сайтов: Полное руководство по сбору данных, дата последнего обращения: июля 21, 2025, https://truetech.by/posts/parsing-dinamicheskih-saitov.html
- Как защитить свой сайт от парсинга данных. Практические советы — Сервисы на vc.ru, дата последнего обращения: июля 21, 2025, https://vc.ru/services/262190-kak-zashitit-svoi-sait-ot-parsinga-dannyh-prakticheskie-sovety
- Что такое отпечаток (fingerprint) браузера. Анализ скликивания — Блог — Botfaqtor, дата последнего обращения: июля 21, 2025, https://botfaqtor.ru/blog/chto-takoe-fingerprint/
- Что такое Fingerprint браузера и как он работает, дата последнего обращения: июля 21, 2025, https://proxy-seller.io/blog/what_is_fingerprint_how_to_check_and_change/
- Отпечаток браузера: что это, как работает, нарушает ли закон и как защититься. Часть 1 — Habr, дата последнего обращения: июля 21, 2025, https://habr.com/ru/companies/selectel/articles/521550/
- fingerprintjs/fingerprintjs: The most advanced browser fingerprinting library. — GitHub, дата последнего обращения: июля 21, 2025, https://github.com/fingerprintjs/fingerprintjs
- Browser Fingerprint – анонимная идентификация браузеров / Хабр, дата последнего обращения: июля 21, 2025, https://habr.com/ru/companies/oleg-bunin/articles/321294/
- jackspirou/clientjs: Device information and digital fingerprinting written in pure JavaScript. — GitHub, дата последнего обращения: июля 21, 2025, https://github.com/jackspirou/clientjs
- Canvas Fingerprinting — BrowserLeaks, дата последнего обращения: июля 21, 2025, https://browserleaks.com/canvas
- Что такое Canvas Fingerprinting: борьба с фродом — Блог — Botfaqtor, дата последнего обращения: июля 21, 2025, https://botfaqtor.ru/blog/chto-takoe-canvas-fingerprinting-i-fraud/
- What Is WebGL Fingerprinting and How to Bypass It — ZenRows, дата последнего обращения: июля 21, 2025, https://www.zenrows.com/blog/webgl-fingerprinting
- Отпечаток браузера Фингерпринт: что это такое — Dolphin {anty}, дата последнего обращения: июля 21, 2025, https://dolphin-anty.net/blog/chto-takoe-fingerprint-brauzera/
- thumbmarkjs/thumbmarkjs: A free, open-source javascript fingerprinting library — GitHub, дата последнего обращения: июля 21, 2025, https://github.com/thumbmarkjs/thumbmarkjs
- Welcome to the world of FingerprintJS open source software. — GitHub, дата последнего обращения: июля 21, 2025, https://github.com/fingerprintjs/home
- Анализ данных о посещении сайта роботами и людьми в Яндекс.Метрике. Часть I, дата последнего обращения: июля 21, 2025, https://osipenkov.ru/analysis-visits-robots-peoples-yandex-metrika-1/
- Основные методы аутентификации для REST API — Блог — Tune IT, дата последнего обращения: июля 21, 2025, https://www.tune-it.ru/web/romo/blog/-/blogs/rest-api-most-used-authentification-methods
- Требования аутентификации и авторизации API | learnapidoc-ru, дата последнего обращения: июля 21, 2025, https://starkovden.github.io/authentication-and-authorization.html
- Аутентификация: что это, различия от авторизации и идентификации — Sber Developers, дата последнего обращения: июля 21, 2025, https://developers.sber.ru/help/sber-id/what-is-authentication
- Аутентификация VS авторизация – в чем разница?, дата последнего обращения: июля 21, 2025, https://wiki.merionet.ru/articles/autentifikaciia-vs-avtorizaciia-v-cem-raznica
- Аутентификация и авторизация: в чём между ними разница? — МТС Exolve, дата последнего обращения: июля 21, 2025, https://exolve.ru/blog/authentication-vs-authorization/
- В чем разница между аутентификацией и авторизацией? | INTROSERV, дата последнего обращения: июля 21, 2025, https://introserv.com/ru/blog/v-chem-raznicza-mezhdu-autentifikacziej-i-avtorizacziej/
- Аутентификация/авторизация в API ч.1 — Разработка на vc.ru, дата последнего обращения: июля 21, 2025, https://vc.ru/dev/1044949-autentifikaciya-avtorizaciya-v-api-ch1
- Что такое безопасность API? 7 практик обеспечения безопасности API — Astera Software, дата последнего обращения: июля 21, 2025, https://www.astera.com/ru/type/blog/api-security/
- Проверка подлинности и авторизация API — обзор — Azure API Management, дата последнего обращения: июля 21, 2025, https://learn.microsoft.com/ru-ru/azure/api-management/authentication-authorization-overview
- Строим защиту от парсинга. Часть 1: основные принципы предотвращения парсинга, дата последнего обращения: июля 21, 2025, https://www.securitylab.ru/analytics/541667.php
- Gartner: Magic Quadrant for Cloud Web Application and API Protection — Techcity, дата последнего обращения: июля 21, 2025, https://techcity.cloud/information/gartner-magic-quadrant-for-cloud-web-application-and-api-protection/
- Bot Management — The Cloudflare Blog, дата последнего обращения: июля 21, 2025, https://blog.cloudflare.com/tag/bot-management/
- The Forrester Wave™: Bot Management Software, Q3 2024, дата последнего обращения: июля 21, 2025, https://www.forrester.com/report/the-forrester-wave-tm-bot-management-software-q3-2024/RES181013
- The Forrester Wave™: Bot Management Software, Q3 2024 — DataDome, дата последнего обращения: июля 21, 2025, https://datadome.co/resources/forrester-wave-bot-management/
- How Cloudflare Bot Management Works, дата последнего обращения: июля 21, 2025, https://www.cloudflare.com/resources/assets/slt3lc6tev37/JYknFdAeCVBBWWgQUtNZr/61844a850c5bba6b647d65e962c31c9c/BDES-863_Bot_Management_re_edit-_How_it_Works_r3.pdf
- Bot Manager | Bot Detection, Protection, and Management — Akamai, дата последнего обращения: июля 21, 2025, https://www.akamai.com/products/bot-manager
- Cloudflare Bot Management & Protection, дата последнего обращения: июля 21, 2025, https://www.cloudflare.com/application-services/products/bot-management/
- Our Plans | Pricing — Cloudflare, дата последнего обращения: июля 21, 2025, https://www.cloudflare.com/plans/
- Обзор плана Business — Cloudflare, дата последнего обращения: июля 21, 2025, https://www.cloudflare.com/ru-ru/plans/business/
- Protect Your E-commerce Platform and Apps — HUMAN Security, дата последнего обращения: июля 21, 2025, https://www.humansecurity.com/platform/industry/retail-e-commerce/
- Improved Bot Management flexibility and visibility with new high-precision heuristics, дата последнего обращения: июля 21, 2025, https://blog.cloudflare.com/bots-heuristics/
- Outsmarting Akamai’s Bot Detection with JA3Proxy — HackerNoon, дата последнего обращения: июля 21, 2025, https://hackernoon.com/outsmarting-akamais-bot-detection-with-ja3proxy
- Building an Effective Bot Management Strategy — Akamai, дата последнего обращения: июля 21, 2025, https://www.akamai.com/blog/security/building-an-effective-bot-management-strategy
- Bot Manager Premier and PIM I Privacy by Design| Akamai, дата последнего обращения: июля 21, 2025, https://www.akamai.com/site/en/documents/white-paper/compliance-through-privacy-by-design-white-paper.pdf
- Akamai Bot Manager — Digital Marketplace, дата последнего обращения: июля 21, 2025, https://www.applytosupply.digitalmarketplace.service.gov.uk/g-cloud/services/843750853041629
- Case Study: Retailer Saves $500K/mo with Anti-Bot Innovation | GlobalDots, дата последнего обращения: июля 21, 2025, https://www.globaldots.com/resources/case-studies/case-study-retailer-saves-500k-mo-with-anti-bot-innovation/
- Imperva Advanced Bot Protection for Financial Services | Resource Library, дата последнего обращения: июля 21, 2025, https://www.imperva.com/resources/resource-library/datasheets/imperva-bot-management-for-financial-services/
- Advanced Bot Protection — Imperva, дата последнего обращения: июля 21, 2025, https://www.imperva.com/resources/datasheets/Datasheet-Advanced-Bot-Protection.pdf
- Advanced Bot Protection — Imperva, дата последнего обращения: июля 21, 2025, https://www.imperva.com/resources/datasheets/Advanced-Bot-Protection_DATASHEET_2024.pdf
- Advanced Bot Protection | Stop Advanced Bots | Imperva, дата последнего обращения: июля 21, 2025, https://www.imperva.com/products/advanced-bot-protection-management/
- Imperva Advanced Bot Protection Base Plan — enhanced subscription (1 month) — additional 1 Mbps, дата последнего обращения: июля 21, 2025, https://ca.insight.com/en_CA/shop/product/ABPABP1MBOVRSRV11/imperva%20inc/A-BP-ABP-1MB-OVR-SRV1/Imperva-Advanced-Bot-Protection-Base-Plan-enhanced-subscription-1-month-additional-1-Mbps/
- Imperva Advanced Bot Protection Bot + Cloud WAF Base Plan — subscription license (1 year) + Enhanced Support — 100 Mbps — Insight, дата последнего обращения: июля 21, 2025, https://www.insight.com/en_US/shop/product/BPABPBASE1001YSRV1/imperva%20inc/BP-ABP-BASE-100-1Y-SRV1/Imperva-Advanced-Bot-Protection-Bot-+-Cloud-WAF-Base-Plan-subscription-license-1-year-+-Enhanced-Support-100-Mbps/
- DDoS-Guard | Российский сервис защиты от DDoS-атак, дата последнего обращения: июля 21, 2025, https://ddos-guard.ru/
- Bot Mitigation — DDoS-Guard, дата последнего обращения: июля 21, 2025, https://ddos-guard.net/technologies/bot-mitigation
- Технология защиты от ботов (Bot Mitigation) — DDoS-Guard, дата последнего обращения: июля 21, 2025, https://ddos-guard.ru/technologies/bot-mitigation
- Защита от DDoS-атак — Виртуальный хостинг — Справочный центр Timeweb, дата последнего обращения: июля 21, 2025, https://timeweb.com/ru/docs/virtualnyj-hosting/zaschita-ot-ddos/zashchita-ot-ddos-atak/
- Обзор мирового и российского рынков систем защиты от вредоносных ботов (Bot), дата последнего обращения: июля 21, 2025, https://www.anti-malware.ru/analytics/Market_Analysis/Bot-Protection
- Qrator Labs выпускает решение для защиты от ботов Qrator Bot …, дата последнего обращения: июля 21, 2025, https://safe.cnews.ru/news/line/2021-09-22_qrator_labs_vypuskaet_reshenie
- Qrator Labs: DDoS Attacks Protection, WAF, DNS, Hosting, CDN, and Bot Protection, дата последнего обращения: июля 21, 2025, https://qrator.net/
- Антибот – защита сайтов, веб-приложений и API — Servicepipe, дата последнего обращения: июля 21, 2025, https://servicepipe.ru/antibot
- What is bot management? | How bot managers work — Cloudflare, дата последнего обращения: июля 21, 2025, https://www.cloudflare.com/learning/bots/what-is-bot-management/
ПОХОЖИЕ ПУБЛИКАЦИИ:
 Руководство по лучшим бесплатным программным решениям CRM для рассмотрения в 2022 году
Руководство по лучшим бесплатным программным решениям CRM для рассмотрения в 2022 году  Защита вашего сайта от парсинга с помощью настроек Nginx: глубокий анализ
Защита вашего сайта от парсинга с помощью настроек Nginx: глубокий анализ  Защита сайта от ботов и парсинга: экспертный взгляд
Защита сайта от ботов и парсинга: экспертный взгляд  Защита описаний товаров и изображений на вашем Интернет-магазине в России: Полное руководство
Защита описаний товаров и изображений на вашем Интернет-магазине в России: Полное руководство  Полное пошаговое руководство по тестированию функциональности веб-сайта
Полное пошаговое руководство по тестированию функциональности веб-сайта  Полное руководство по 152-ФЗ для веб-сайта: Как избежать штрафов Роскомнадзора в 2025 году и далее
Полное руководство по 152-ФЗ для веб-сайта: Как избежать штрафов Роскомнадзора в 2025 году и далее  Стоимость разработки сайта в 2023 году: Полное руководство
Стоимость разработки сайта в 2023 году: Полное руководство  Как использовать WordPress: полное руководство по созданию сайта на WordPress
Как использовать WordPress: полное руководство по созданию сайта на WordPress  Headless-браузеры для парсинга: Полное руководство по автоматизации, обходу блокировок и масштабированию
Headless-браузеры для парсинга: Полное руководство по автоматизации, обходу блокировок и масштабированию  Как остановить плагины ChatGPT от парсинга содержимого вашего сайта
Как остановить плагины ChatGPT от парсинга содержимого вашего сайта
БАНКОВСКИЕ И ФИНАНСОВЫЕ УСЛУГИ
База всех компаний в категории: ВАЛЮТА ОБМЕН
МЕДИЦИНСКИЕ УСЛУГИ
База всех компаний в категории: МЕДИЦИНСКИЕ АНАЛИЗЫ
СТРОИТЕЛЬНЫЕ УСЛУГИ
База всех компаний в категории: СУДОСТРОЕНИЕ СУДОРЕМОНТ
WILDBERRIES
WILDBERRIES
ТОРГОВЫЕ УСЛУГИ
База всех компаний в категории: МАГАЗИН МОДНЫХ АКСЕССУАРОВ
СТРОИТЕЛЬНЫЕ УСЛУГИ
База всех компаний в категории: СТРОИТЕЛЬНЫЕ ГИПЕРМАРКЕТЫ
АВТОМОБИЛЬНЫЕ УСЛУГИ
База всех компаний в категории: ЗАПРАВОЧНЫЕ СТАНЦИИ
УПРАВЛЕНИЕ НЕДВИЖИМОСТЬЮ
База всех компаний в категории: КОМПАНИЯ ЖКХ